
Abstract
Keywords
Introduction and Related Literature
Recent Internet clickstream tracking technology has generated the fast growing practice of web analytics and extensive ongoing research in academia. Indeed, the Internet has changed the way business works by providing new information and distribution channels for both firms and customers. Customers can readily obtain product information online without physically visiting a firm. Firms can use clickstream tracking technology to see in real time who is visiting their websites and analyze detailed clickstreams to learn more information in advance.
Clickstream tracking allows firms to “learn about customers without asking” (Montgomery and Srinivasan 2003), but the associated academic research has been largely focused on online shopping and e‐commerce: Montgomery (2001) shows that quantitative models that are commonly used in brick‐and‐mortar distribution channels prove to be useful in optimizing the use of clickstream data. The associated literature is extensive; see, e.g., Johnson et al. (2003), Moe and Fader (2004), Montgomery et al. (2004), Sismeiro and Bucklin (2004), Van den Poel and Buckinx (2005), Hui et al. (2009) and references therein. This literature is essentially about the marketing benefits of clickstream tracking because e‐commerce websites serve primarily as sales channels. Clickstream tracking allows e‐commerce firms to get accurate readings of the efficiency of their websites, quickly usher a visitor (referred to as “she” throughout the study) who is about to purchase an item to a high‐speed server, identify target visitors to show pop‐up coupons, and so on.
In contrast to e‐commerce settings, we investigate “non‐transactional websites” that serve predominantly as a product catalog while orders are taken offline. Many business‐to‐business (B2B) settings as well as some business‐to‐consumer (B2C) settings fall in this category. Specifically, this study stems from our interaction with a US manufacturer of industrial products, hereafter referred to as “the company.” The company makes high‐end roll‐up doors that are customized for industrial and commercial buildings with regards to size, type of material, type of environment, etc. The doors can go into new buildings or can replace older doors. Prices for a door range from the thousands to tens of thousands of dollars. Like many others, the company provides current and potential customers with company, product, and contact information on its website. However, the website is non‐transactional and the company sells its products offline, either direct or through dealers. The company hires the services of a web analytics firm that specializes in clickstream tracking to help demand forecasting, procurement, and inventory planning.
Our study focuses on the operational benefit of clickstream tracking by investigating its use as advance demand information for procurement, production, and inventory planning. We are interested in how, and to what extent, clickstream data from non‐transactional websites can improve demand forecasting for inventory management. In particular, in this setting of a B2B business with non‐transactional informational websites, we address the following research questions: (1) How can we use clickstream data in inventory management? This requires a tactical model that explicitly incorporates clickstream data in operations management. (2) How can we identify the statistically significant clickstream data and prediction functions (needed in the model) and improve the demand forecast? (3) How large is the operational value of using the advance demand information from clickstreams to reduce inventory holding and backordering costs in our setting?
We believe these questions are timely and important for several reasons. The recent fast‐growing research using clickstream data has already demonstrated the great interest and importance for e‐commerce firms. The same applies to offline‐selling firms. Understanding consumer online browsing behavior and its value helps firms make investment decisions regarding the adoption of clickstream tracking technology. Manyika et al. (2011) report that “big data—large pools of data that can be captured, communicated, aggregated, stored, and analyzed—is now part of every sector and function of the global economy.” Clickstream tracking has allowed individuals around the world to contribute to the amount of big data available to companies. Our study examines the potential operational value that clickstream data, an important type of big data, can create for companies and seeks to illustrate and quantify that value. In a concrete setting of the company, we show that using the information extracted from the clickstream data can reduce the inventory holding and backordering cost by 3% to 5% in many representative parameter scenarios. The model and empirical methods we use in our study may be useful for other companies that aim to exploit big data to gain competitive advantage.
The clickstream data and sales data we study has significant differences from the data from e‐commerce stores studied in the literature because the company website is non‐transactional. While it has been confirmed in the literature that online click behavior is correlated with purchasing behavior in e‐commerce settings, it is much less clear whether such correlation persists in non‐transactional settings because customers do not have to visit the website to make a purchase. This procedural separation reduces the predictive power of web visits to forecast purchase orders if there is any statistical relationship between them at all. It is reported that e‐commerce sales only account for 1.2% of all retail sales. 1 Hence, the vast majority of commerce still is executed offline, and thus our research setting addresses a larger part of the economy beyond e‐commerce.
Due to the procedural separation, non‐transactional websites provide the opportunity for firms to react. Clearly, in an e‐commerce setting like Amazon, the time lag between clicks and orders could be on the order of minutes, too short to adjust operational plans. The longer time separation between clicks and orders has an important benefit: if it exceeds the production or procurement lead time, the firm can respond to changes in advance demand information. Matching supply with demand is one of the main issues for operations management. There is a vast body of literature modeling advance demand information; see, for example, Hariharan and Zipkin (1995), Raman and Fisher (1996), Chen (2001), Gallego and Özer (2001, 2003), Özer and Wei (2004), Tan et al. (2007), Wang and Toktay (2008), and Gayon et al. (2009). Özer (2011) provides a comprehensive literature review. All these studies assume that advance demand information is available and study how to use it in inventory management. On one hand, our study is in the same spirit of, and complementary to, this literature by introducing a practical decision support model that endows classic inventory management with clickstreams as a flow of advance demand information. On the other hand, our study is the logical precedent: to what extent can advance demand information be obtained from clickstreams? Although the value of advance demand information is well established and understood theoretically, research on how advance demand information is obtained in practice and its empirical evidence seems largely absent in the operations management literature. Özer (2011) offers several examples of obtaining advance demand information in practice such as flexible delivery at the time of ordering, ordering customized products, and advance selling. All these practices share the same feature that advance demand information is obtained at the time of customer ordering. Clickstream data, in contrast, provides advance demand information in a completely different way: first, it can be unrelated to customer ordering. Second, such information can be obtained well before customer ordering. (For example, the earliest lead time in our data set is 438 days before a customer actually placed an order and the mean time is around 90 days.) Hence, this kind of demand information can be truly “advance.” More importantly, such information is obtained “without asking” customers, which is also called “inferring” (Fay et al. 2009). Our empirical study of this novel information technology shows that clickstream data is useful for operation managers to predict demand and helps firms “do the right thing at right time in right quantities.”
Our work is also related to recent empirical study in the information systems literature of using keyword search and social mentions to predict future events, based on the idea that what people are searching for today is predictive of what they will do in the future (cf. Asur and Huberman 2010, Goel et al. 2010, Joo et al. 2012, and reference therein). Our research shares the same theme in spirit in that we all demonstrate the promise of using online data to forecast future consumer demand. While their studies are typically at the aggregate level using public data, our study shows that an individual firm can actually exploit its private data from click tracking and directly translate it to profit.
The main contributions and findings of the study are as follows: We introduce a practical dynamic decision support model that augments the traditional inventory management with clickstreams as additional state variables in the dynamic programming formulation for demand forecasting. We conduct an empirical study to identify (i) which clickstream variables are statistically significant for demand forecasting, (ii) how to include them into the state variables of the dynamic model, and (iii) to estimate the extent to which utilizing the clickstreams creates operational value. We find that customer clicking behavior is a statistically significant predictor of the corresponding offline purchasing behavior in terms of not only ordering probabilities and ordering amount (in monetary value), but also ordering timing (lead time). Through a counterfactual study, we show that using the information extracted from the clickstream data can reduce the inventory holding and backordering cost by 3% to 5% in many representative parameter scenarios. To the best of our knowledge, this study is the first in the operations management literature that provides both a model and empirical evidence to demonstrate how the recent clickstream tracking technology can be used to improve operational decisions. Our study aims to stimulate future empirical and theoretical work in this practice‐ and data‐driven field.
The outline of this study is as follows. The next section presents a theoretical model to demonstrate how clickstream data can be used to improve demand forecasting and inventory management. In section 3, we empirically identify the clickstream variables that are significant for demand forecasting. In section 4, we quantify the operational value of advance demand information from the clickstream data using our model. Section 5 contains the discussion and limitations.
A Model of Using Clickstream Data in Inventory Management
We start by introducing a tactical model of using clickstream data in demand forecasting and inventory management that can serve as a decision support system in practice. This practical model endows classic inventory management with clickstreams as a dynamic flow of advance demand information. In section 3, we will empirically identify relevant model variables. This model will also be our tool for estimating the operational value of clickstream data in section 4.
We explain how to use clickstreams in inventory management first in a single‐period newsvendor model and then in a multi‐period dynamic model. In a single‐period model, before the company's production or procurement decisions, clickstreams are observed to predict demand. For each visitor 


To explain how to use clickstream data in a dynamic setting, consider a discrete‐time inventory control model endowed with clickstream data. Suppose there are



Extending the previous single‐period model to a multi‐period model introduces significant analytical complications for at least three reasons: first, the demand distribution in period 













We are now ready to describe the system dynamics analytically. Our approach allows for a class‐by‐class analysis. Recall that 









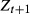





According to flow Equation 1, 








The Markovian assumption allows us to formulate the company's inventory management problem as a finite‐horizon discounted dynamic programming problem using 


For 


In this section, we will empirically demonstrate that clickstreams are indeed useful to estimate the purchasing probability 

Background, Data Source, and Characteristics
The company is in the Midwest of the United States and has some smaller rivals in neighboring states. Consumers can freely shop around and visit websites of multiple similar providers. The website provides comprehensive information to customers; however, due to the customized nature of the product, committing to purchasing is done typically over the phone either through the company directly or through dealers.
The company's website provides the company profile information, product specification information based on different industries, contact information for the company and its dealers, and a webpage where customers can send an email to the company. However, price is not shown on the website and is communicated offline. Customers can acquire information from a few other channels such as phone calls, word of mouth, and brochures from industry conferences. Visiting the website is not a prerequisite for purchasing the product. We do not have an exact percentage of customers that visit the website, as some customers may visit through private computers or their internet service providers that prevent identity identification. 4 Hence, this study focuses on only those identifiable customers who ever visited the website.
Let us discuss the current inventory management at the company we studied. The company has to keep inventory for a “patented part” (required for assembling an end product) that is supplied from Europe with a transportation lead time of three months. The company procures this component every three months, which we model as one “period” using Figure 1 in section 2. The supply lead time is one period. The “demand lead time” (Hariharan and Zipkin 1995, Gallego and Özer 2001, Tan et al. 2007, Özer 2011, and references therein) is approximately zero, as customer demand is satisfied in less than two weeks. (The company can assemble‐to‐order within two weeks if all required components are available.) The challenge for inventory management is that the supply lead time is much longer than the demand lead time and that backordering customer demand is costly. The intangible adverse effect of the future loss of customer goodwill due to backordering is estimated by managers at around five times of the per unit procurement cost.
We use two data sets of the company that sells high‐end roll‐up doors in North America. The first data set is the clickstream data from August 26, 2006 to February 28, 2008. The company started to track clickstreams from August 2006. The second data set includes both the historical sales data that dates back to March 1998 and recent sales data from August 2006 to November 2008. There are 5185 customers, and 9694 visits in the data.
In our setting, web visitors do not identify themselves because they do not purchase and reveal contact or payment information online. The firm can only learn each visitor's identity through her IP address. In addition, we study a B2B setting where the customers themselves are firms. This has benefits and drawbacks: about 82% of the visits in our clickstream data come from a company‐registered IP address so that the visitor is easily identified with a company. Then we can manually match clickstream data with sales data to investigate the correlation between clicking behavior and ordering behavior. The other 18% of visits come from large service provider IP addresses (e.g.,
In the clickstream data, the unit of data corresponds to a customer who clicked and has the following fields: the name of the customer identified from her IP address; the clickstream, which is a summary of the recorded click behavior that includes the time of visits/clicks; cumulative visits (i.e., the cumulative number of visits); average time stayed online per visit, average number of pages visited per visit; and the detailed page‐specific data such as the sequences of pages visited and the time length.
Each unit in the sales data records the customer name, the ordering amount (in US dollars), and the time of ordering.
Before statistical analysis could be started, several preprocessing tasks were executed. First, we cleaned the clickstream data by deleting unidentifiable clicks. The second preprocessing step deleted some organizations that we excluded in our study such as universities, public organizations, etc. In the ordering data set, indeed, no universities or public organizations ever purchased any product from the company. Their visits may have been research‐inspired.
Third, as discussed in the introduction, we aggregated all the visitors within a company as a
Finally, we matched the clickstream data set with the sales data set together by the firm/customer names. We have 9694 visits in our clickstream data set after preprocessing and matching with the sales data. 6
Variable Definitions
We use the (binary) indicator variable
Which variables should be used to approximate for customer click behavior? We believe that the answer depends on the context. What we did is to explore all the commonly used click variables that have been used in the literature (cf. Moe and Fader 2004), for example, cumulative number of visits, visit duration, cumulative and average number of pages, etc. At the same time, we avoid any multicollinearity problem. We also include webpage‐specific variables to capture more individual heterogeneity. In our setting, the contact information pages appear informative in terms of predicting purchase propensity.
We have four different kinds of variables that comprise our explanatory variables. First, we have “general clickstream measures,” which concern data measured at a rather general level of the clickstreams. They represent the information at the level of the session, which is defined as a single visit to the website.
Second, we have “detailed clickstream measures” that indicate whether some specific pages were visited or not. There are essentially two categories of web pages on the firm's website: one category of pages presents product information while the other category shows the contact information if visitors want to contact the company or distributors or if visitors want to become distributors. Intuitively, we expect visits to pages of contact information to be more informative. Indeed, there is a lot of variation in terms of whether these contact‐information pages were visited or not, and we use indicator variables to account for this variation. In particular, the variables
Third, given that new customers may derive more informational value from web browsing than existing customers, we have “historical order information” about each visitor, and the dummy variable
Finally, some “company demographics variables,” i.e., industry control variables, are at our disposal. We include company industry type variables to control for the heterogeneity in the
Summary Statistics
Summary Statistics
We need a specific empirical prediction function 
We thus adopt a logit model as our prediction function 

The vector 

The vector 


The error terms 



The simple logit model has limitations in our setting in that all visitors within each industry share the same coefficients for click variables, although we used demographic variables to take into account visitor heterogeneity.
To incorporate more customer heterogeneity in the prediction function 








The unconditional probability is the integral of the conditional probability over all possible values of 



In this subsection, we conduct hypothesis testing to investigate how the clickstream data can be useful for demand forecasting. Then, we present the empirical results.
The first hypothesis is to test whether the clickstream data can be used as advance demand information:
Visitor online behavior, as defined by the general clickstream measures and the detailed clickstream measures, is significantly correlated with offline ordering probability/propensity.
Demand/order lead time plays an important role in operations management. While past research almost exclusively focused on predicting purchase probabilities, we also investigate whether we can use clickstream data as advance demand information to predict the
Order lead time is negatively and significantly correlated with cumulative visits.
We are also interested in whether click information is useful for predicting the ordering amount as well:
Online clicking behavior is significantly correlated with offline ordering amount.
Now we present our regression results. Table 2 shows the logit regression results. From the Wald test result, our logit regression model is significant at level 0.00%. Some of the general click variables and detailed page‐specific variables are statistically significant, which indicates that we fail to reject Hypothesis 1, i.e., visitor online click behavior is indeed providing the firm useful information to predict future ordering probabilities.
Logistic Regression Results (Dependent Variable: Order)













Standard errors are reported in parentheses. 


We find that
Table 2 also shows that the detailed click variable
Intuitively, how long a customer has been searching may affect or reflect her purchasing propensity. We create a new age factor variable to keep track of how long a customer has been searching:
Logistic Regression Results with Searching Time Length: Order as the Dependent Variable




Standard errors are reported in parentheses. 

More interestingly, from Table 4, not only does
Regression Results: Lead Time as the Dependent Variable



Standard errors are reported in parentheses. 



From Table 5, we can see
Regression Results: Order Amount as the Dependent Variable





Standard errors are reported in parentheses. 
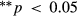


Table 2 also shows that the
Table 2 shows the results for new customers and existing customers separately. One implication is that these two classes of customers indeed should be treated differently in terms of linking their click behavior to their ordering probability. For new customers,
To include more customer heterogeneity, we also estimate the random coefficient logit model. Assuming the coefficients of click variables are normally distributed, we conduct the simulated maximum likelihood estimation using KNITRO‐MATLAB and report the results in Table 6. The click variables are jointly significant, suggesting that click information indeed provides useful information for predicting purchase probabilities even if visitor heterogeneity is taken care of. Furthermore, we have the same signs for these click variables as in the standard logit. From Table 6, we can also see that there is indeed some heterogeneity among visitors, but such heterogeneity is not significant for the majority of the click variables such as
Random‐coefficient Logit with Clickstream Coefficients Normally Distributed






Standard errors are reported in parentheses. 


To further examine predictive validity of the clickstream data for demand, we also estimate the logit model using only the randomly selected first half of the data set. Then, we apply the estimated regression equation to the holdout sample (i.e., the second half of the data) and obtain the predicted average purchasing probability (also called conversion rate) 15.61%. Lastly, we compare the predicted average purchasing probability with the actual purchasing probability 14.65%, and get the prediction error in percentage: 6.49% ( ≅ (15.61% − 14.65%)/14.65%). This demonstrates that the predictive power of the clickstream data is fairly good.
We highlight a few findings that are novel compared with those in e‐commerce: First, we include more detailed webpage‐specific variables that are typically absent in the e‐commerce literature (cf. Moe and Fader 2004), and we find that visiting the contact‐distributor page or not is useful for predicting future demand. Second, we find differences between new customers and existing customers (e.g., average time length is significant for new customers but not for existing customers). Third, we have the ordering amount information, which is also absent in the literature.
In the previous section, we have provided affirmative statistical evidence that the clickstream data is useful for operational forecasting in terms of advance demand information. In this section, we will discuss what predictors from the clickstream data companies should track and evaluate the operational value of the clickstream data based on the theoretical model in section 2 and empirical analysis in section 3.
Which predictors should be tracked?
Although the findings here are only for a specific company, the methods do generalize. In general, companies should first conduct a similar empirical study and estimate the statistical significance of both general click measures and detailed click measures as we did. This will reveal which predictors are most statistically significant for the specific setting during that specific time period. (Indeed, if seasonality is perceived to be significant, the empirical study and any parametric estimation should be performed repeatedly per season.) For example, in our setting,
To illustrate how our approach and the dynamic flow Equation 1 works, we now discuss how the operational forecasting process can be simulated based on our data sets. As a simple heuristic and representative example, we classify the visitors based on whether their 











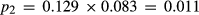



For the initialization period, 
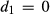


In the next period, 






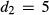


In period 









Let us apply the model to the current inventory management at the company we studied. As aforementioned, the company keeps inventory for a “patented part” (required for assembling an end product) that is supplied from Europe with a transportation lead time of three months. The company procures this component every period (i.e., three months) using Figure 1 in section 2. The supply lead time is one period, and the demand lead time is zero.

Description of the Dynamic Programming Model
Before quantifying the operational value in terms of cost reduction, we can first demonstrate how clickstream data improves operational forecasting by reducing demand uncertainty. We compare the variance of demand when clickstream data is utilized versus when it is not. Without clickstream data, the company can only use its prior demand distribution. Let 








We used the following parameters: 
Robustness Check of the Operational Value


Our primary goal of this study is to show how, and to what extent, clickstream data from non‐transactional websites can improve operational forecasting and inventory management. We first introduced a dynamic decision support model that includes clickstreams as state variables in inventory management. Second, we conducted an empirical study to identify which clickstream variables are statistically significant for demand forecasting and to estimate the extent to which including these clickstreams reduces operational costs. We found that clickstream data can be used to estimate ordering probability, amount, and timing. We also found that advance demand information extracted from the clickstream data can reduce the inventory holding and backordering cost by 3% to 5% in many representative parameter scenarios.
Our study is motivated by practice and is aimed to guide better practice of clickstream tracking in operations management (see also our companion study, Huang and Van Mieghem 2013). Our model provides a practical framework to dynamically convert clickstream data into useful advance demand information for inventory management. In practice, firms should develop decision support systems using clickstream data by taking advantage of various statistical and computer science tools, such as data mining and artificial intelligence, to enhance the prediction from the regression equation (e.g., using more sophisticated prediction function 
Our findings must be interpreted cautiously given the limitations of our study: first, all our hypotheses are about “correlation” rather than “causality.” Establishing the causality has been difficult in the literature, and we are not aware of any study that establishes whether clicking causes purchasing or whether it is vice versa. Our data does not allow us to establish such a causal relationship. That requires expensive field experiments for future research. Second, we only used the visitors who are identifiable in our clickstream data set, which can create biases for our empirical study. Companies should consider mechanisms to improve customer identification of clickstreams (e.g., use cookies, let customers sign in and provide more information, etc.). Third, considering the heterogeneity of visitors, our control variables are limited. For example, price is negotiated offline and such information is unobserved by us. While this is the best our data allows, we can take comfort knowing that the random‐coefficient logit model further takes care of the heterogeneity to some degree. Fourth, we do not conduct time series analysis due to our limited observations within a short period of time. Availability of large‐scale data sets for a long period of time would allow us to investigate the dynamics over time. Fifth, due to analytical tractability and data availability, we cannot incorporate multi‐unit demand information for a customer. Hence, this study provides a lower bound for the operational value of the clickstream data. Finally, although our models and methods can be generalized and help build an integrated decision support tool to be applied to other settings of offline sales with informational websites, all the findings herein are based on the data from a particular industrial firm with a fixed period of visiting customers. We hope our study stimulates more research in this important, practice‐driven and data‐driven area.