
Abstract
Introduction
Scheduling is ubiquitous in organizations and often involves the assignment of people with preferences to scarce resources or tasks. Examples include the allocation of surgeons to hospital operating rooms, workers to shifts or projects over time, or students to different courses on a weekly schedule. There is a huge literature on optimization formulations and decision support tools for rostering, staffing, or scheduling, which typically analyzes such problems from the point of view of a single decision maker or planner (Sampson 2004, May et al. 2011, Jung et al. 2019, Ou et al. 2010). Kreipl and Pinedo (2004) provide an excellent overview of the variety of scheduling problems that arises in and across organizations. For most of these problems, peoples’ private preferences matter. Surgeons have preferences for certain time slots for their operations (May et al. 2011), and workers have preferences for times of the day and free time (Burke et al. 2004). However, almost all of the scheduling literature assumes complete information about the participants’ preferences. The focus is on the mathematical solution of the resulting optimization problem, given that the true preferences are available. This might be a too strong assumption for most applications, but leads to a fundamental question: How can participants be incentivized to reveal their preferences truthfully?
Mechanism design investigates economic mechanisms with a focus on incentive‐compatibility. A mechanism is
Unfortunately, important scheduling problems cannot be addressed with auction mechanisms. First, monetary transfers are not allowed or desired. Second, cardinal utility and interpersonal utility comparison is too much to assume and we can only hope to get ordinal preferences. Finally, most scheduling problems are computationally hard and for realistic problem sizes an exact solution might not be tractable. However, the VCG mechanism requires exact solutions to the allocation problem.
Course assignment is a case in point. Students have preferences for different combinations of courses across the week. It is considered unacceptable to have students pay for course assignments in most environments, and we cannot expect from students the assignment of cardinal utilities to course bundles, only ordinal rankings of these bundles. Besides, the allocation problem is equivalent to a multi‐unit combinatorial auction as we show in Section 2.1, which is known to be NP‐hard (Lehmann et al. 2006). For larger problem sizes, such problems become intractable.
Currently, course schedules are often determined based on First‐Come First‐Served procedures (FCFS). As it is hard for students to influence whether they are first, second, or third in a row, this procedure is similar to random serial dictatorship (RSD), the only widely used and well‐studied mechanism that is incentive‐compatible and (Pareto) efficient. Students log on to the registration system at some time and select the best bundle of courses among the remaining course seats according to their preferences. Unfortunately, FCFS is not envy‐free (Mas‐Colell et al. 1995). Envy‐freeness is a central notion of fairness and ensures that a student prefers the matching she is faced with to that offered to other students. The fact that FCFS leads to substantial envy in course scheduling leads students to switch assignments until late in the semester, and the resulting schedules for students are undesirable because tutorials are scattered across the week. This has been a growing concern at the Technical University of Munich (TUM) due to increasing student numbers over the past 10 years.
The theory of matching under preferences analyzes mechanisms which set incentives for participants to reveal their preferences truthfully without monetary transfers. Since winning the Noble Prize in Market Design in 2012, the field has drawn significant academic attention, with important applications in the matching of residents to hospitals, in school choice, or in kidney exchanges (Manlove 2013). Until recently, this theory was largely restricted to problems where participants have unit demand (e.g., a single course seat). However, new approaches have been developed which allow for more complex preferences such as preferences for packages of course seats or schedules and other complex constraints (Budish et al. 2013, Kamada and Kojima 2017, Nguyen et al. 2016). Interestingly, randomization and approximation turned out to be powerful tools for designing new mechanisms with good properties such as efficiency, envy‐freeness, and incentives for truthful reporting in the presence of complex preferences (Nguyen et al. 2016). So far, such mechanisms have not been used in the field and the empirical performance of randomized mechanisms has not been studied. We analyze randomized approximation mechanisms in the context of course scheduling in the field and in the lab. Course assignment will be our focus in this study, but we discuss alternative applications at the end of this study.
Course Assignment and Distributed Scheduling
While some universities use matching mechanisms such as the deferred acceptance algorithm (Diebold et al. 2014, Gale and Shapley 1962) or course bidding (Krishna and Ünver 2008, Sönmez and Ünver 2010), in most cases scarce course seats are allocated via FCFS policies. Although many course assignment problems are similar to the widely studied school choice problems (Abdulkadiroğlu and Sönmez 2003, Ashlagi and Shi 2016) with students having private preferences for one out of many courses, often students are interested getting combinations of courses across the week, not just a seat in a single course. Assigning schedules of courses has been referred to as the
The need to assign course schedules rather than courses individually became apparent in an application of matching with preferences at the TUM that we will discuss. The TUM uses the deferred acceptance algorithm for two‐sided matching problems and RSD for one‐sided matching problems in situations where only one out of a single course seat is required (i.e., unit demand). These algorithms are used to assign students to seminars or practical courses, and every semester about 1500 students are being centrally matched.
However, in many situations, students’ preferences do not only concern a single course. For example, in the first three semesters of the study programs there are large courses with hundreds of students. These courses include a lecture and small tutor groups. Students need to attend one tutor group for three to four courses in each semester. These tutor groups should not overlap and they should be adjacent to each other such that students do not have a long commute for each of the tutor groups individually. For example, a student might want to have two tutorials in the morning and one after lunch on a particular day to reduce his commute time, and he would have a strong preference for this schedule over one where the tutorials are scattered across the week. In any case, students have timely preferences over course schedules that need to be considered, which makes it a combinatorial assignment problem.
While FCFS is widespread, the
The work was breaking new ground, but the A‐CEEI mechanism is also challenging. First, the problem of computing the allocation problem in A‐CEEI is computationally very hard (PPAD‐complete) and the algorithms proposed might not scale to larger problem sizes required in the field (Othman et al. 2016). The problems reported in Budish and Kessler (2021) already take 48 hours to solve on a compute cluster based on an elaborate implementation of the mechanism using various types of heuristics to speed up the solution time. There is no guarantee that somewhat larger problem sizes can still be solved. Second, it is not guaranteed that a price vector and course allocation exists that satisfies all capacity constraints, which leads to clearing errors. Third, students might not be able to rank‐order an exponential set of bundles, which is a well‐known problem (aka. missing bids problem) in the literature on combinatorial auctions (with money) (Bichler and Goeree 2017). The latter is a general problem in CAP not restricted to A‐CEEI, which we also focus on in our paper.
Randomization can be a powerful tool in the design of algorithms, but also in the design of economic mechanisms. Nguyen et al. (2016) recently provided two randomized mechanisms for one‐sided matching problems, one with cardinal and one with ordinal preferences for bundles of objects. The mechanism for ordinal preferences is a generalization of probabilistic serial (Bogomolnaia and Moulin 2001), called Bundled Probabilistic Serial (BPS). Nguyen et al. (2016) show that this randomized mechanism is ordinally efficient, envy‐free, and weakly strategy‐proof. These appealing properties come at the expense of feasibility, but the constraint violations are limited by the size of the packages. In course assignment problems, the size of the packages is typically small (e.g., packages with three to four tutor groups) compared to the capacity of the courses or tutor groups (around 30 seats or more). Even if capacities of a tutor group are violated by two or three seats, and this does not happen too often, tutors could cope with it by adding a few more seats. The mechanism does not have a need for prices or budgets, and only ordinal preferences are required from the participants. Computationally, the mechanism runs in polynomial time. Actually, even large instances can be solved in minutes, which makes the mechanism a practical alternative to FCFS that is easy to implement for university administrators with appropriate preference elicitation, as described in this study.
These properties make BPS a very attractive and fair (in the sense of envy‐free) alternative to the widespread FCFS or RSD mechanisms, which is of importance to operations management way beyond the course allocation applications, which we focus on in this study. In Section 6, we discuss alternative applications in production and operations management.
Contributions
We provide results of a mixed‐methods study including field and laboratory experiments, a survey, and simulations to analyze the BPS mechanism in the context of course assignment. The field experiments are based on a first implementation of this randomized scheduling mechanism in a large‐scale course assignment application. The evaluation of the field data from two initial pilots (with 1438 and 1778 students, respectively) led to the permanent adoption of the new system, the first real‐world implementation we know of.
Preference elicitation is a central challenge in mechanisms for the combinatorial assignment problem, which is why we discuss it in more detail. In contrast to preference elicitation in multi‐attribute decision making (Stewart 1995), it is the combinatorial explosion of possible packages of interest that leads to challenges for the decision maker. This problem has not received much attention in the literature yet. We introduce a new approach to rank the exponential set of bundle preferences a priori based on a domain‐specific scoring function and elicit parameters of this scoring function from the participants. The approach is able to capture the specifics of the students’ preferences in our domain, as we show.
The empirical analysis of BPS is the focus of our analysis. We ran two large‐scale field experiments and compare BPS to FCFS (i.e., a simulation as RSD). We focus on this comparison because RSD is the de facto standard in all application domains for this type of scheduling problem. 1 We report the size of the matchings (i.e., the number of students matched), the average rank of the bundle that a student got, the probability of being matched, the rank profile (i.e., how many students got their first, second, or third ranked bundle), and the popularity of BPS among students compared to FCFS (i.e., whether students would prefer the BPS outcome to FCFS). These properties are of central importance for the choice of mechanisms and important to understand beyond the theoretical properties of the mechanism.
The results of our field experiment show that BPS actually dominates FCFS in all of the empirical metrics introduced earlier in our field experiments. While the differences in most criteria are small, envy‐freeness turns out to be an important advantage of BPS. The level of envy that we find in FCFS is substantial in spite of the limited complementarities in student preferences, who are only interested in packages with at most four tutor groups.
These results are based on the assumption that participants submitted their preferences truthfully in the field experiments. In contrast to FCFS, BPS is only weakly strategy‐proof and the preferences elicited might not be the true preferences of bidders. We organized a laboratory experiment and conducted a survey with 80 students and found that students actually hide their least preferred bundles. Fortunately, such manipulation has little impact on the overall efficiency of the outcome, as we found in simulations where we even truncated the reports to only the top 10 or top 30 preferences of each student. The mechanism is robust as long as the top preferences reported reflect the true preferences of the students. The long tail of the preference reports primarily serves the purpose not to be assigned a random (and possibly very low preference) bundle in situations where none of the top preferences can be assigned.
In summary, our study shows that BPS is at least as good as FCFS in all criteria, and it clearly dominates FCFS as participants do not have envy in an expected sense. This advantage has to be traded off with the added complexity of preference elicitation and the fact that participants might manipulate or make mistakes, a risk that is much reduced in FCFS.
Our work is positioned at the intersection of operations management and information systems (Kumar et al. 2018). It is in line with a stream of research in information systems on multi‐unit and combinatorial auctions, where monetary transfers can be used to allocate goods efficiently (Adomavicius et al. 2012, Bapna et al. 2010, Goetzendorff et al. 2015). In operations management, there is substantial recent literature on scheduling (Diamant et al. 2018, Lee et al. 2018, Yu et al. 2020, Zhou et al. 2021). Typically, this research addresses mathematical models and algorithms to compute optimal schedules. In some applications preferences of participants play a role on top of hard scheduling constraints, but these preferences are assumed to be given (Lemay et al. 2017). Our paper contributes to this literature and discusses an economic mechanism that elicits ordinal preferences from the participants in a truthful manner.
Problem Definition and Design Desiderata
We now define the combinatorial assignment problem (CAP) in the context of course assignment applications, desirable properties, and randomized mechanisms.
Problem Definition
Assigning objects to agents with preferences but without money is a fundamental problem referred to as 
In the 


We can model feasible assignments with linear constraints. Thereby, bundles are described with binary vectors 

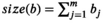




A 

For assignment problems with single‐unit demands (
Unfortunately, the Birkhoff–von Neumann theorem fails when bundles
Design Desiderata of Randomized Mechanisms
Stochastic dominance (SD) is the key concept among all of these definitions, as it provides a natural way to compare random assignments. Let Δ describe the set of all possible random matchings. With 

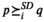







One desirable property of matchings is 




Ordinal efficiency comes from the Pareto ordering induced by the stochastic dominance relations of individual students. It can be shown that ordinal efficiency implies
Envy‐Freeness


An assignment mechanism is an algorithm, which computes a matching 

A 


An important property of a mechanism is
Let



Thereby, 

Let





In other words, an ordinal mechanism is strategy‐proof if for any agent, the allocation resulting from misreporting is weakly stochastically dominated by the allocation from truthful reporting, with respect to an agent's true preferences. Weak strategy‐proofness means that there may not be any student 

Randomized Mechanisms
We now discuss different randomized mechanisms for the combinatorial allocation problem that satisfy design desiderata discussed in the previous section. Much is known about assignment problems with single‐unit demand. RSD selects a permutation of the agents uniformly at random and then sequentially allows agents to pick their favorite course among the remaining ones. Gibbard (1977) showed that random dictatorship is the only anonymous and symmetric (i.e., equals are treated equally), strongly
However, RSD is not always ordinally efficient, only ex post efficient, which is somewhat weaker (Bogomolnaia and Moulin 2001). Zhou (1990) actually showed that no random mechanism for assigning objects to agents can satisfy strong notions of strategy‐proofness, ordinal efficiency, and symmetry simultaneously with more than three objects and agents. So, we also cannot hope for these properties in combinatorial assignment problems. RSD can also be applied to the combinatorial assignment problem. The Bundled Random Serial Dictatorship (BRSD) orders the students randomly and assigns the most preferred bundle which is still available to each student in this order. Although the package preferences take some toll on the runtime, it is still very fast.
First‐Come First‐Served (FCFS) can be interpreted as a serial dictatorship. Students log in during a certain registration time and then reserve the most preferred bundle of courses that is still available. Although the arrival process is not uniform at random, students have little control over who arrives first, which can be seen as a reasonable approximation of BRSD. While there is a certain time when the registration starts, hundreds of students log in simultaneously to get course seats and it is almost random who arrives first. We simulate FCFS via BRSD and run the algorithm repeatedly to get estimates for performance metrics of FCFS in expectation.
Probabilistic Serial (PS) (Bogomolnaia and Moulin 2001) is a mechanism for the assignment problem with unit demand, which has drawn considerable attention in the literature. PS produces an envy‐free assignment with respect to the reported unit‐demand preferences, and it is ordinally efficient, but it is only weakly
Informally, in BPS all agents 

Preference Elicitation
The BPS mechanism described in the previous section and its properties require that the designer has access to a strict preference relation ≽
Overall Process and Background
The Department of Computer Science at the TUM has been using stable matching mechanisms for the assignment of students (with unit‐demand preferences) to individual course seats in seminars and laboratories since 2014. The system provides a web‐based user interface and every semester almost 1500 students are matched to laboratory courses or seminars via the deferred acceptance algorithm for two‐sided matching.
First, the students specify their preferences for a set of courses in the upcoming semester until a certain deadline. Then the students are assigned to courses via the deferred acceptance algorithm and informed about their assignment via e‐mail. Since the resulting outcomes of the deferred acceptance algorithm are envy‐free, attempts to change to another course are very limited. Only a few students drop out before the semester starts and overall the assignment procedure has proven very stable in practice. The software did not support combinatorial assignments until 2017. Therefore, the web‐based software was extended with BPS, the lottery mechanism for decomposing fractional solutions, and BRSD, which were described in the last section.
The overall process for the combinatorial assignment followed that of the standard matching process (with unit demand) that was in use since 2014. A few numbers from the initial field experiments should provide a background and information about the scale of the application. During the summer term in 2017, 1439 students in their second semester of computer science and information systems participated in the matching and they could choose tutorial groups from several courses, including linear algebra, algorithms, software engineering, and operations research. A computer science student could have preferences for up to 5760(=10·24·24) bundles 2 and an information systems student could have preferences for up to 5184(=9·24·24) bundles. 3 A computer science student in the winter term could have even more than 700,000 different bundle preferences. 4 To rank order such a long list of preferences, students need decision support.
Automated Ranking of Packages
A naive approach to preference elicitation would be to let the students rank bundles on their own by choosing the time slots they want to have in their preference list. It would take a significant amount of time to rank even a small subset, and the students would only be able to rank order a few course bundles leading to a substantial missing bids problem. At most, one could expect students to rank their top 10 or 20 preferences manually. However, there is no guarantee that they actually receive one of their top ranked bundle. Without a ranking of all preferences, students face the risk of either getting a random assignment or no assignment at all. The problem how to elicit ordinal preferences for an exponential set of course bundles has not received much attention, and we are only aware of one related paper by Budish and Kessler (2021) that we will compare with in Section 4.3.
We propose a new approach to address the missing bids problem. This approach is based on a domain‐specific scoring function. After discussions with students, it turned out that a few obvious aspects matter for students. The students’ preferences for the tutorials mainly concern their commute and the possibility of having free, large contiguous blocks of time (e.g., a day or a half‐day) that they can plan for other activities (e.g., a part‐time job). When they register for tutorials, they do not know the name of the tutor, so only timely preferences matter. In larger cities, the time that students spend in commuting is significant and students want to minimize the commute time. Also, long waiting times between courses are perceived as a waste of time, as it is often hard for them to work productively in several one‐ or two‐hour breaks. The minimal length of the break and recovery time differed, however, as well as the maximum number of tutorials a student wanted to have per day or the times of the day available on each day. After the interviews, it was clear that after eliciting only a few parameters such as the minimal length of the breaks, the acceptable times of each day, and the maximum number of tutorials per day, one could define a scoring function that ranks all possible packages automatically. Students could inspect the resulting ranking, revise the parameters of the scoring rule or individual ranking results.
Figure 1 shows screen shots of the overall process. First, students choose the lectures and tutorials they are interested in. The selected lectures will be considered in the bundle generation as constraints, that is, if a time slot of a tutorial for one lecture overlaps with the time of another selected lecture, then it will no longer be considered in order to allow students to participate in the lecture. In the second step, the student marks available time ranges in a

Process to Rank‐Order Packages [Color figure can be viewed at
A student can set a minimal amount of time for a lunch break and a minimal amount of time between two events (default value is 15 minutes). We also allow students to provide weights {1, …, 5} for the different days. That is, the students can express preferences over the days. With this information from students, we parameterize a scoring function to rank order the different combinations of course bundles.
An algorithm first generates bundles that satisfy all constraints and then ranks them based on the scoring functions. Bundles are generated one by one for all students. Finding the bundles that do not violate constraints of the students (e.g., lectures to be attended) can be cast as a constraint satisfaction problem. After the feasible bundles are generated, the bundles are scored. The score considers How many days a student needs to come to the university per week, The preference ordering over the days, The total time a student has to stay at the university each day, and The length of the breaks between courses.
The score for a bundle 
This score is scaled between 0 and 27.5 at a maximum and it considers how well the day is utilized with courses based on the preference parameters specified by the student. The time spent at the university per day
A second component in the daily score (
Students enter their preferences into a database in parallel or sequentially during the preference elicitation phase and before the BPS algorithm is executed. After one of the students enters his preferences and generates a ranking of bundles, he might not be happy with the resulting rank order of bundles. In this case, he can manually rearrange the bundles in the ranking or he can go back and score again with different parameters (see Figure A.5 in the online companion). The first page shows the 30 top‐ranked bundles. Note that ≈90% of the students received one of their top 10 ranked packages and only very few students received a package with a rank larger than 30. So, if a student manually inspects and confirms the ranking of the first 10–30 packages, this covers the most important quantile of the overall ranking list. This exercise can be done in a few minutes based on the generated ranking.
Of course, there are different ways of how such a scoring function can be specified. Obviously, any scoring function is only a heuristic helping students determine the strict ranking which is required by BPS, and any attempt to score and rank a large set of bundles can also be challenged (see discussion in Section 5.6). We have conducted extensive tests with students to understand how well the resulting ranking reflects their preferences. The feedback in these tests and that of the survey organized after the matchings was very positive, emphasizing the flexibility that it provides in specifying preferences.
The details of the scoring function are specific to our course assignment application. We argue, however, that one can find a reasonable scoring rule to help participants rank order in most application domains. For example, when assigning packages of time slots to carriers in retail logistics, these packages could simply be rank‐ordered by computing the round‐trip times for the various acceptable tours and rank by shortest time (Karaenke et al. 2019). Timely preferences, such as in our application, could also play a role in allocating surgeons to operating rooms, etc.
Challenges of Course‐Level Scoring
Ranking an exponential set of packages is a general issue in course assignment problems, and one might ask for alternative methods. The only related work by Budish et al. (2017) that we are aware of will be discussed next. Budish et al. (2017) describes the preference elicitation used at the Wharton School of Business for the A‐CEEI mechanism. Students could report cardinal item values on a scale of 1 to 100 for any course they were interested in taking. In addition, they could report adjustments for pairs of courses, which assigned an additional value to schedules that had both course sections together. Courses were then scored and transformed into an ordinal ranking over feasible schedules. The authors argue that they felt that “adding more ways to express non‐additive preferences would make the language too complicated.” Wharton also provided a decision support tool listing the 10 most‐preferred bundles, which allowed students to inspect top‐ranked schedules and modify the cardinal values. The authors write that “if the preference language given to students is not sufficiently rich … then Course Match may not yield desirable results.” Assigning course‐level scores is fast and simple, but two problems make this method challenging to apply in our domain.
First, the ranking is sensitive to minor changes in the weights, which is a well‐known issue in multi‐criteria decision making with additive value functions. Evaluation is characterized by a substantial degree of random error, and the amount of error tends to increase as the decision maker attempts to consider an increasing number of attributes (or courses in our case) (Bowman 1963, Fischer 1972). Difficulties in the calibration of scores for each course can lead to substantial differences in the resulting ranking. It is very hard to precisely calibrate such weights in general.
Second, and more importantly, significant non‐linearities arise due to the timely preferences of students in the assignment of tutorials in our course assignment application, making it impossible to describe the preferences via a course‐level utility function as proposed by Budish et al. (2017). Even if three tutorials get a high number of points, this does not mean that their combination is preferable by a student as these tutorials might be on different days or have long breaks in between. To see this, we translated the ranking of packages into a set of inequalities with weights (

We had preferences ranking 4000–12,000 bundles for the courses of the winter term. None of these settings could be solved with objective value zero, that is, the generated preference lists are not representable with a linear model with adjustment‐terms used by Budish et al. (2017). Even if it was possible to find such a vector of course‐level weights, it would probably be very difficult to parameterize by students. Overall, eliciting preferences for hundreds of bundles is a challenging problem and needs to be tailored to the application, but the quality of any mechanism for combinatorial allocation problems depends heavily on this input, which is the reason why we discussed this issue in more depth.
Empirical Evaluation
We now provide the results of our empirical mixed‐methods study. First, we discuss the empirical metrics used. Second, we provide results from our field experiments. We take the preferences elicited for BPS in the field, compute another matching with BRSD with these preferences, and compare the various metrics for BPS and BRSD. As indicated in Section 3, BRSD is used as a proxy for the results of FCFS. Although BPS is weakly SD‐strategy‐proof, we do not know from the field experiment whether students indeed report their true preferences. Therefore, we organized a laboratory experiment with induced preferences. This laboratory experiment was complemented by a survey where we explicitly asked students how well they were able to specify their preferences and whether they were intentionally manipulating their induced preferences or not. The results of both the laboratory experiments and the survey indicate that students truncate their least preferred packages, that is, the ones including days for which they have a very low preference. In Subsection 5.5, we report results of simulations, where we truncate the original preferences to the top 10, 20, or 30 only, in order to understand how robust the efficiency results are against manipulation or imprecisions in the preferences of higher ranks.
Metrics
In this subsection, we introduce empirical metrics that allow us to compare BPS and BRSD in our experiments. The size and the average or median rank can be used as efficiency metrics. The
The
Let 
Aside from efficiency, fairness, and strategy‐proofness, 

A random assignment

Field Experiments
The overall process of the field experiment and how students submitted preferences was explained in the Section 4. Table 1 provides the main evaluation metrics, not only for the initial two field experiments in the summer term 2017 and the winter term 2017/18, but also those for the subsequent two years in which the combinatorial assignment was carried out. Taking the preferences for bundles of tutor groups elicited for the BPS allows for a comparison with BRSD on equal footing. To really compare the result of BPS and BRSD, we actually would have to run the BRSD for all permutations of the students. A single run is clearly not sufficient, as we need to compare probability distributions. Note that computing probabilities of alternatives in RSD explicitly is a computationally very challenging (#
Summary Statistics for all Instances
The computation times were negligible for BRSD (0.007 seconds per run). BPS required 0.12 seconds computation time with an additional 6 minutes for the lottery algorithm in the summer term 17, for example. This shows that BPS is a practical technique even for large assignment problems, which can be run on standard computers. In contrast, solving deterministic scheduling problems of this size as integer problems would typically be intractable. Also, the A‐CEEI mechanism and the Course Match system that is used for related applications is computationally very demanding (Budish et al. 2017).
In terms of average rank, average size, and the probability of being matched to one of the first 100 ranks, BPS is better than BRSD in all four instances, but not by much. The AUPCR is sometimes slightly higher for BPS, sometimes for BRSD. In addition, Table 2 reports the probability of being matched to one of the top 10 ranks and the AUPC in percentage for BPS and BRSD. Differences in these metrics are minimal.
Rank Profiles for all Instances
Our field experiments confirm the theoretical result that BPS is (strongly)
A positive popularity score as described in Definition 1 means that BPS is more popular than the BRSD outcome and the score for BPS is 2.97 for the summer term 17 and 3.09 for the winter term 17/18, for example. In all four instances, BPS is more
Laboratory Experiments
In order to study whether students submit their preferences truthfully, we report results of a laboratory experiment. The experiment was conducted from June 8, 2020 until June 16, 2020 at the TUM. The participants were able to participate in the experiment online within a period of nine days. In total, 91 students participated. Eleven students either did not complete the matching or the survey, which is why they were excluded, resulting in 80 participants that were evaluated. The students were all studying computer science or information systems, which is representative for the type of students that usually participate.
After having sent out the link to the experiment platform with an individualized authorization code, participants could start the experiment by logging into the experiment's platform. The platform we used for this experiment was provided by soscisurvey.6 We ensured an anonymous treatment of participants’ data at all times. Furthermore, the authorization code, allocated by the platform, allowed for an anonymous processing as well as stopping and continuation of a student's progress in the experiment if necessary. At the beginning, participants could download instructions, which explained the experimental setting, the procedure, and rules of the experiment (see online companion D). On top of that, watching an additional instruction video was mandatory for being able to continue the experiment. In the video, we gave an overview of the instructions and explained the functionality of the matching tool.
Before students could start working with the matching tool, they had to take a quiz so that we could make sure that they understood the environment and the task. After they participated, they had to fill in a survey, which we discuss in the next subsection. Budish and Kessler (2021) argue that, at least in the setting of preferences over course topics, no monetary incentive is needed because most participants will take decisions as seriously as in a real setting. However, monetary incentives increase the external validity of the experiment, which is why we introduced a winning lottery. The reward mechanism was such that, the better the outcome of the matching fit the induced ranking of bundles, the higher the participant's chances of winning in a lottery of five times 40 EUR. This mitigated the risk of participants submitting random input.
The experimental design was simple. The only treatment in our experiments was the variation in preference profiles (see Figure 2). These were modeled after preference profiles we found in field data. In the analysis, we were only interested in the degree to which students reported their induced preferences truthfully.

Perference Profiles with Weights for Individual Days of the Week. A Higher Weight Means a Higher Preference
The results of the experiment showed a clear pattern. Students often omitted the least preferred day in her induced preferences when reporting, as can be seen in Table 3. By least preferred day, we define the day or days in the preference profile with the lowest preference weight.
Number of Omitted Days Per Preference Profile in Total. Boxed Entries Mark the Least Preferred Day in the Respective Profile. The Right Column Denotes the Number of Students who were Assigned this Profile
Aside from omitting a day altogether, students could also reduce the number of hours acceptable on a day. We state that a day is de‐emphasized by choosing a time interval of less or equal than 2 hours, although a student would be available all day. Table 4 shows those days that were either omitted or de‐emphasized. These simple descriptive statistics show a very clear profile that students truncate their reports and do not report low preferences. These findings were supported by a survey we took among the students participating in the laboratory experiment.
Number of de‐emphasized and omitted days per preference profile in total. Boxed entries mark the least preferred day in the respective profile. The right column denotes the number of students who got this profile assigned
Survey Results
The survey was taken right after students submitted their preferences but before they learned the results such that the results do not influence the survey results in Table 5. The responses indicate that the majority of the students responding found the system easy to use and that they could express their preferences well. While 76.2% of the participants had no difficulties selecting time intervals in the weekly schedule (Question 1), 59.9% found it easy to rearrange the ten pre‐ranked bundles (Question 2). Also, 69.9% of participants found their given preferences to be realistic (Question 6). This is in accordance to the finding that 73.7% of the respondents could infer their preferred tutorials from their given preferences (Question 7). A high proportion of participants (86.2%) could express their day priorities with ease (Question 9).
Survey Results, Values in % for “Strongly Disagree” (1) to “Strongly Agree” (5)
As the given preferences were clearly visible on the same scale as the day priorities, 91.2% of the participants indicated that they expressed their preferences in the matching tool in accordance with the given day priorities (Question 10). We furthermore see that 98.7% of participants perceive their preference reporting as being truthful (Question 11). However, 27.5% of the students report that they were hiding the least preferred time slots (Question 13). According to students’ self‐reporting, manipulation is mainly done by de‐emphasizing least preferred days in the input of time slots (Question 14).
Sensitivity Analysis with Truncated Preferences
The fact that a part of the students indicate that they did not report low preferences truthfully is concerning. In FCFS, students only provide their single best package at the point in time when they log in. This is simple, intuitive, and obviously strategy‐proof. This property has to be traded off against the level of envy in FCFS. So, the question is how truncation of the reports (omitting the least preferred bundles) impacts the overall results. We ran simulations where we took into account only the top 10, 20, or 30 bundles in the preference relations of all participants. This can be considered an extreme case of truncation. In our notation, BPS‐10 reports the statistics for those instances, taking into account only the top 10 preferences. The resulting summary statistics can be found in Tables 6 and 7. Table C.8 in Appendix C in the online companion shows the rank profiles with and without truncation for all instances.
Summary Statistics for all Truncated Instances SS17 and WS 17/18
Summary Statistics for all Truncated Instances WS 18/19 and WS 19/20
Interestingly, the impact of truncation is low. This is due to the fact that most students could be matched to one of their top 30 preferences. If we take into account only the top 10 preferences, the expected rank improves at the expense of the number of people matched. In other words, if a student is not assigned at all, this leads to less competition for the highly ranked bundles and to higher average ranks overall. With respect to popularity, more students prefer the results with truncated valuations. Except from WS19/20 BPS‐30, students SD‐prefer the version with truncation of the preferences to that with all preferences taken into account.
Discussion
In theory, the comparison between BRSD (as a proxy for FCFS) and BPS is clear: BRSD is obviously strategy‐proof, efficient, but not envy‐free. In contrast, BPS is weakly SD‐strategy‐proof, SD‐envy‐free, and ordinally efficient. An empirical analysis allows us to consider various empirical metrics to measure the quality of the matching beyond efficiency. Also, lab experiments help us understanding whether participants are indeed truthful in a mechanism that is weakly SD‐strategy‐proof.
Overall, we find that BPS dominates BRSD on most empirical metrics in our empirical evaluation (such as rank, size, and probability of being matched), but that the differences are very small. For the profile curves (AUPCR) there is no clear winner, which is interesting given the fact that only a small number of preferences per student are considered via BRSD.
There are a number of reasons that help in explaining the close performance of BPS and BRSD in these metrics. First, Che and Kojima (2010) have found that RSD and probabilistic serial become equivalent when the market becomes large, that is, the random assignments in these mechanisms converge as the number of copies of each object type grows and the inefficiency of RSD becomes small. Our empirical results suggest that differences might also be small in large combinatorial assignment markets with limited complementarities.
Second, ordinal preferences do not allow expressing the intensity of preferences. Suppose there are two students who both prefer course 




Third, an earlier comparison of FCFS with a deferred acceptance algorithm by Diebold et al. (2014) in environments with unit demand for a single course seat also showed that FCFS yielded surprisingly good results. While the average rank of FCFS was worse, the size of the matching resulting from FCFS was significantly larger compared to that from the deferred acceptance algorithm. For the combinatorial assignment problem, BPS also had a slightly larger average size. It is important to understand these trade‐offs for applications of matching in practice.
A central theme of this study is that care needs to be taken in how preferences are elicited in any form of combinatorial assignment. Although our sensitivity analysis shows that the top preferences matter most, oversimplified scoring functions might not reflect the real preferences of participants and lead to bad outcomes for individuals. Our laboratory experiments provide empirical evidence that students attempt to provide their preferences truthfully. However, they might make mistakes and they frequently truncate their least preferred bundles. In contrast, preference elicitation for FCFS is as simple as possible.
Conclusions and Managerial Implications
Many organizations have distributed scheduling problems where ordinal and private preferences of participants matter. Designing incentive‐compatible, efficient, and envy‐free mechanisms for such problems without monetary transfers appeared impossible until recently. RSD is the de‐facto standard for such types of scheduling problems, but it is not envy‐free, which often leads to concerns. Bundled Probabilistic Serial uses approximation and randomization and satisfies randomized notions of efficiency, strategy‐proofness, and envy‐freeness.
We have studied randomized approximation mechanisms in the context of course assignments, which allowed us to run large‐scaled field experiments. The informational requirements of BPS about student preferences are challenging, because a strict rank‐ordering of exponentially many bundles is needed. As in many scheduling applications, student preferences in our course assignment application are about times of the week. We introduced a way to rank order the many possible schedules based on a few parameters. The feedback of students was that this automated ranking met their preferences well and we argue that this is a good way to address the missing bids problem in similar applications. Of course, other domains might have different requirements and the way how preferences are elicited needs to reflect the domain specifics. We argue that for most domains it will be possible to define a good scoring function that helps participants finding an initial ranking. Together with the possibility to manually rearrange the top ranked bundles, this is a practically viable approach to address the preference elicitation problem in the combinatorial assignment problem with time‐dependent and ordinal preferences.
Although BPS provides a powerful new alternative to scheduling problems with private preferences, there are trade‐offs. First, in contrast to FCFS, the BPS mechanism is not obviously strategy‐proof and a part of the students in the survey already indicated that they hid their least preferred time slots strategically. This might partly be due to the fact that students were unexperienced with this new mechanism. Second, the assumption of strict preferences is strong in the presence of exponentially many bundles. Unfortunately, extending PS or BPS to preferences with ties is not without loss. On the one hand, Katta and Sethuraman (2006) extended PS to preferences with indifferences and showed that it is not possible for any mechanism to find an envy‐free, ordinally efficient assignment that satisfies even weak strategy‐proofness, as in the strict preference domain. On the other hand, with indifferences and random tie‐breaking efficiency cannot be guaranteed. Our preference elicitation technique generated a strict and complete ranking of course bundles based on a few input parameters and is one way to address these issues.
Implementing and testing new artifacts in organizations is challenging and we are grateful for the opportunity to run a large‐scale field experiment at the TUM. Such pilots are very valuable but also hard to organize in most organizations. This is particularly true for a non‐standard mechanism such as BPS, which involves optimization and randomization. We report the results of field experiments with Bundled Probabilistic Serial for course scheduling, and show that it performs well on a number of criteria including average rank, average size, and the probability of a matching. The matching based on BPS is also more popular than the one resulting from FCFS on average based on the preferences submitted for BPS.
Most importantly, however, the level of envy in FCFS is significant, even though the size of the packages that can be submitted is limited to the number of classes (three to four groups per package) in our course assignment application. This has actually always led to complaints from students in the past. Many students wanted to change course seats with peers, which led to administrative overhead and complaints about bad course schedules for students. These complaints vanished after the BPS mechanism was adopted. The BPS mechanism is now an accepted tool among students to deal with the assignment of multiple tutor groups, and its introduction is considered a success as expressed by a letter from the Head of Academic Programs.
The study has implications for the broader field of production and operations management because many other applications share similar characteristics: participants have private and ordinal preferences for packages of objects, and monetary transfers are either not allowed or not desired. For example, in a recent paper an auction mechanism was used for the allocation of time slots at warehouses to carriers in retail logistics (Karaenke et al. 2019). Congestion at loading ramps is a significant problem in practice and it deteriorates the efficiency in retail logistics. It is well known that this is due to a lack of coordination among carriers, who all plan their routes independently. BPS could provide an alternative to FCFS that is envy‐free and does not require monetary transfers. The problem is related to the literature on scheduling truck arrivals (Ou et al. 2010), and more generally to timetabling or conference scheduling (Sampson 2004). Similarly, various types of workforce scheduling share similar characteristics. This includes the assignment of nurses or doctors to shifts or crews to flights of airlines. In summary, if envy‐freeness matters, the elegant BPS mechanism has a number of attractive properties, which otherwise suffer from computational hardness of the allocation problem and strategic manipulation. The results of this study provide useful insights to other organizations that want to adopt distributed scheduling mechanisms in lieu of simple FCFS heuristics.