
Abstract
Keywords
Introduction
The Bayesian information criterion (BIC) is one of the most commonly used model evaluation criteria in social research, for example, for categorical data (Raftery 1986), event history analysis (Vermunt 1997), or structural equation modeling (Lee and Song 2007; Raftery 1993). The BIC, originally proposed by Schwarz (1978), can be viewed as a large sample approximation of the marginal likelihood (Jeffreys 1961) based on the so-called unit information prior. This unit information prior contains the same amount of information as would a typical single observation (Raftery 1995).
The BIC has several useful properties. First, it can be used as a default quantification of the relative evidence in the data between two statistical models. Second, it can straightforwardly be used for evaluating multiple statistical models simultaneously. Third, it is consistent for most well-behaved problems in the sense that the evidence for the true model converges to infinity (Kass and Wasserman 1995). Fourth, it behaves as an Occam’s razor by balancing model fit (quantified by the log likelihood function at the maximum likelihood estimate [MLE]) and model complexity (quantified by the number of free parameters). Fifth, it is easy to compute using standard statistical software: Only the MLEs, the maximized loglikelihood, the sample size, and the number of model parameters are needed to compute it. All these useful properties have contributed to the popularity and usefulness of the BIC in social research.
Despite the general applicability of the BIC, it is not suitable for evaluating statistical models with order constraints on certain parameters. In a regression model, for instance, it may be expected that the first predictor has a larger effect on the outcome variable than the second predictor, and the second predictor is expected to have a larger effect than the third predictor. This can be translated to the following order-constrained model,
The reason that the BIC is not suitable for testing models with order constraints is that the number of free parameters does not properly capture the complexity of a model. In the above model M1, all three
Testing order constraints is particularly useful because effect sizes can only be interpreted relative to each other in the study and relative to the field of research (J. Cohen 1988). An effect size of, say, .3, of educational level on attitude toward immigrants might seem substantial for a sociologist, while .3 might not be interesting when it quantifies the effect of a medical treatment on the amount of pain of a patient. Thus, instead of interpreting the magnitudes of effects by their estimated values, it may be more informative to interpret them relative to each other, as is done using order-constrained model selection. This would allow us to assess which effects dominate other effects in the study. Further, order-constrained model selection is useful when testing scientific expectations that can be formulated using order constraints. Examples will be presented in the second section in sociological applications, but there is also an increasing body of literature on this topic (e.g., Böing-Messing et al. 2017; Braeken, Mulder, and Wood 2015; de Jong, Rigotti, and Mulder 2017; Hoijtink 2011; Klugkist, Laudy, and Hoijtink 2005; Kluytmans et al. 2012; Mulder and Fox 2019; Mulder and Pericchi 2018; van de Schoot et al. 2012). By testing order-constrained models, we can quantify the evidence in the data for one scientific theory against others. Order-constrained models are also naturally specified when one is interested in the effect of an ordinal categorical variable on an outcome variable of interest.
It is also important to note that the inclusion of order constraints results in more statistical power. This can be explained by the smaller subspace for the parameters under an order-constrained model compared to an equivalent model without the order constraints. The order constraints make the model “less complex,” resulting in a smaller penalty for model complexity, and thus in more evidence for an order-constrained model that is supported by the data.
In this article, we explore how the BIC can be extended to enable order-constrained model selection. First, a unit information prior is considered that is truncated in the order-constrained subspace. This results in a BIC that may not properly incorporate the relative complexity of an order-constrained model. For this reason, an alternative local unit information prior is considered which is centered on a null value. This prior results in a BIC that properly incorporates the relative fit and complexity of order-constrained models. The R package “
To our knowledge, there have been two other proposals for the BIC for evaluating models with order (or inequality) constraints by Romeijn, van de Schoot, and Hoijtink (2012) and Morey and Wagenmakers (2014), and we will compare our proposal to theirs. The article is organized as follows. We motivate the evaluation of statistical models with order constraints on the parameters of interest in the context of the European Values Study in the second section. In the third section, we discuss BIC approximations of the marginal likelihood under an order-constrained model. Fourth section provides a numerical evaluation of the methods, while fifth section describes software to implement the methods. Sixth section explains how to apply the new method for testing social theories in the European Values Study, and seventh section discusses the results.
Order-constrained Model Selection in Social Research
In this section, we present two situations where order-constrained model selection is useful. First, theories often make an assumption about the relative importance of certain predictors on an outcome variable. This can be formalized by specifying order constraints on the effects of these predictor variables. We will show this in Application 1 using Ethnic Competition Theory (Scheepers, Gijsberts, and Coenders 2002). Second, a researcher may have an expectation about the direction of an effect of a predictor variable with an ordinal measurement level. When modeling this ordinal predictor variable using dummy variables, the expected directional effect can be translated to a set of order constraints on the effects of these dummy variables. This will be shown in Application 2 by considering Inglehart’s Generational Replacement Theory.
Application 1: Assessing the Importance of Different Dimensions of Socioeconomic Status
In most European countries, the majority of immigrants are located in the lower strata of society. For this reason, lower-strata members of the European majority population who hold similar social positions as the ethnic minorities, having a relatively low social class, low educational level, or low-income level will on average compete more with ethnic minorities than will other citizens in the labour market. Therefore, Ethnic Competition Theory (Scheepers et al. 2002) would predict that higher social class, educational level, or income level would result in a more positive attitude toward immigrants. Furthermore, it is likely that social class (which reflects the type of job a person has) has the largest impact because one’s social class is directly related to the labour market. The effects of education are less direct, and therefore, it is expected that one’s educational level has a lower impact on attitude toward immigrants than social class. Finally, it would be expected that the effect of income would be the lowest but still positive. This expectation will be formalized in model M1 which is provided below.
Alternatively, due to the importance of education in shaping one’s identity (A. K. Cohen et al. 2013; van der Waal, de Koster, and ten Kate 2015), it might be expected that education is the most important factor explaining one’s attitude toward immigrants, followed by social class and income for which no specific ordering is expected (formalized in M2). A third hypothesis is that all three dimensions have an equal and positive effect on attitudes toward immigrants (M3). Finally, it may be that none of these three hypotheses is true (M4).
To evaluate these expectations, we first write down the linear regression model where the attitude toward immigrants is the outcome variable, and social class, educational level, and income are the predictor variables while controlling for age. The

for
The four expectations given above can be formalized using competing statistical models with different order constraints on the standardized effects, namely,

where
Note that nuisance parameters (e.g., effects of control variables) are omitted in the above formulation of the models of interest to simplify the notation. Further note that additional competing constrained models could be formulated in this context as well. For the current application, however, we restrict ourselves to these models.
Application 2: The Importance of Postmaterialism for Young, Middle, and Old Generations
Experiences in preadult years are known to have a crucial impact on the development of basic values in later life. Due to the increase in welfare in recent decades, Generational Replacement Theory predicts that the values of younger generations are different from those of older generations. In particular, postmaterialistic values, such as the desire for freedom, self-expression, and quality of life, are expected to have increased for younger generations as a result of improved economic standards in Western countries (Inglehart and Abramson 1999; Welzel and Inglehart 2005).
In the European Values Study, generation was operationalized using an ordinal variable with three categories corresponding to a young, middle, or old generation. Similarly, postmaterialism has been measured on an ordinal scale as well, having three categories. When setting the younger generation as the reference group and using dummy variables for the middle and older generations, Generational Replacement Theory can be translated to an order-constrained model (M1). We contrast it with a model that assumes no generation effect on postmaterialism (M0) and with a complementary model that assumes neither an increased effect nor a zero effect (M2).
The models of interest can be summarized as follows:

Furthermore, we hypothesize that the inclusion of order constraints on the generational effects of interest results in an increase of statistical power in comparison to testing the classical alternative, say,
BIC Approximations of the Marginal Likelihood
In this section, extensions of the BIC are derived for a model with order (or inequality) constraints on certain model parameters. Consider an order-constrained model M1 with
For example, the order-constrained model
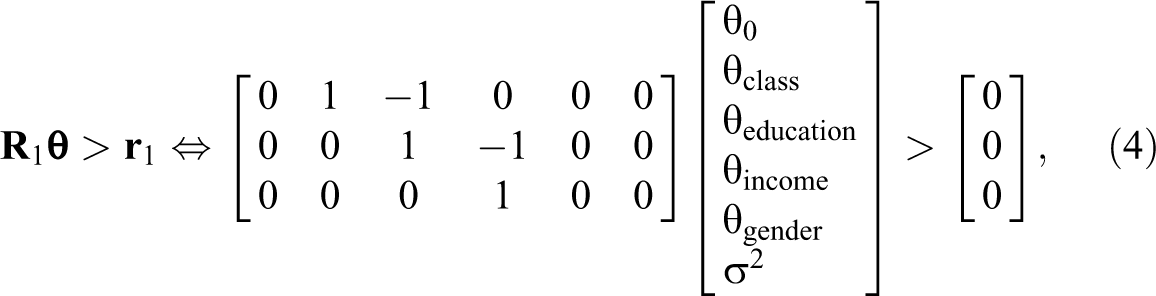
where the first element of
The likelihood function under M1 is a truncation of the likelihood under an unconstrained model, that is,
Truncated Unit Information Prior
First, we assume that the unconstrained posterior mode, denoted by

where
Hence, the only difference with the original derivation is that the resulting approximation also includes the posterior probability that the order constraints of M1 hold under the larger unconstrained model M

As was pointed out by Raftery (1995), certain terms cancel out when plugging in the so-called unit information prior (see also Kass and Wasserman 1995). The unit information prior has a multivariate normal distribution with mean equal to the MLE and variance equal to the inverse of the expected Fisher information matrix of one observation, that is,

where the prior probability serves as a normalization contant so that the truncated unit information prior integrates to one, that is,

Evaluating the logarithm of the unconstrained unit information prior at the unconstrained MLE yields

The corresponding order-constrained BIC is then obtained by multiplying the logarithm of the approximated marginal likelihood by

where the first two terms form the ordinary BIC of model M1 without the order constraints (i.e., M
Next, we consider the case where the unconstrained posterior mode does not lie in the inequality-constrained subspace of M1, that is,
Because of the exponential tails of the normal distribution, a first-order Taylor expansion of


Plot of the log of prior times likelihood,
The marginal likelihood can then be approximated as follows:

Hence, instead of the normal distribution which is used to compute the integral in the case of a second-order Taylor expansion, an exponential distribution is used to compute the integral using this first-order Taylor expansion. The approximated line is also plotted in Figure 1 (green line).
The figure suggests that the second-order Taylor approximation at the unconstrained posterior mode is less accurate than the first-order Taylor approximation at the boundary point. This suggests that the approximated marginal likelihood under the inequality-constrained model will generally be better using first-order approximation at the boundary point in the case that the inequality constraints are not supported by the data. In the remainder of this article, however, we shall use the second-order Taylor approximation at the unconstrained posterior mode both when the posterior mode does and does not lie in the subspace of the inequality-constrained model under investigation.
When the order constraints are not supported by the data, the crudeness of the approximation is less important because the order-constrained model will not be selected because of the bad fit. Instead another, better fitting model will be selected for which the approximated marginal likelihood can be accurately estimated. Another reason for working with the second-order Taylor approximation is that it can easily be computed using equation (7), also for more complex systems of inequality constraints on multiple parameters, for example,
It has been argued that data-based priors, such as the unit information prior, may result in Bayes factors that do not function as an Occam’s razor when evaluating inequality-constrained models (Mulder 2014a, 2014b). To see that this is also the case for the unit information prior, the approximated Bayes factor of an inequality-constrained model M1 against an unconstrained model M

This follows automatically from equation (7).
Now in the case of overwhelming evidence for M1, that is,
Truncated Local Unit Information Prior
Due to the behavior of the unit information prior when evaluating order-constrained models, we consider a “local” unit information prior with a mean that is located on the boundary of the inequality-constrained space (we borrow the term “local” from Johnson and Rossell 2010). Note that the boundary space is equal to the parameter space under the null model
We set the mean of the local unit information prior equal to the MLE under the null model, denoted by

By applying equation (14) in Kass and Raftery (1995), changing the unit information prior to the local unit information prior results in an approximated logarithm of the marginal likelihood of

Consequently, the approximated Bayes factor based on the local unit information prior of an inequality-constrained model against an unconstrained model is given by

Now in the case of overwhelming evidence for M1, in the sense that
Instead of working with equation (9), we consider a slightly cruder approximation where the third term, which quantifies prior fit, is omitted. This yields

The rationale for omitting this term is that we are not interested in quantifying prior misfit. Another reason is that equation (11) can be combined with the ordinary BIC approximation for an unconstrained model (i.e., “
The terms on the right-hand side of equation (11) have the following intuitive interpretations. The first and second term can be interpreted as measures of model fit and model complexity of the unconstrained model where the inequality constraints are excluded (similar to the ordinary BIC approximation based on the unit information prior). The third term, which is the approximated posterior probability that the inequality constraints hold under the unconstrained model, can be interpreted as a measure of the relative fit of an order-constrained model M1 relative to the unconstrained model M
Thus, equation (11) will behave as an Occam’s razor when evaluating order-constrained models by balancing the fit and complexity of the order-constrained model. The corresponding order-constrained BIC based on the local unit information prior then yields

Comparison With Other BIC Extensions
The order-constrained BIC in equation (12) shows some similarities with the BIC extensions proposed by Romeijn et al. (2012) and Morey and Wagenmakers (2014). In the proposal of Romeijn et al., the prior can be chosen by users allowing a subjective quantification of the relative size of the constrained space. Although this may be useful in certain situations, the BIC is typically used in an automatic fashion, and thus, it may be preferable to also let the prior probability be based on a default prior. The advantage of using the local unit information prior for this purpose is that it results in a reasonable default measure for the relative size of an order-constrained parameter space because the prior is centered on the boundary of the constrained space (unlike the [nonlocal] unit information prior). For example, when considering a univariate one-sided constraint,
Furthermore, Romeijn et al. set the posterior probability that the order constraints hold to 1 in the case the MLE is in agreement with the constraints and 0 elsewhere. This additional approximation step follows directly from large sample theory: When the sample size goes to infinity, the posterior probability converges to 1 if the true parameter value is an interior point of the order-constrained subspace and 0 if it is an interior point of the complement of this subspace. Thus, for extremely large samples, the prior-adapted BIC of Romeijn et al. may perform similarly to the order-constrained BIC in equation (12).
For small to moderately sized samples, however, setting the posterior probability to either 1 or 0 may result in crude approximations of the posterior probability. As will be shown in the empirical application in Application 1: Assessing the Importance of Different Dimensions of Socioeconomic Status subsection, for example, the posterior probabilities that two competing sets of order constraints hold under an unconstrained model are equal to .50 and .18. Setting these probabilities to 1 and 0, respectively, would result in an unnecessarily crude estimate of the marginal likelihood. Instead, we recommend using the actual posterior probability that the order constraints hold based on the unconstrained approximated posterior (the third term in equation [12]).
In the proposal of Morey and Wagenmakers (2014), the prior probability that a specific ordering of
Numerical Analyses
The behavior of approximated Bayes factors based on the unit information prior and the local unit information prior will be investigated in a numerical example of the linear regression model,
Statistical Evidence for Order-constrained Models
To better understand how the approximated Bayes factors quantify statistical evidence for order-constrained models, we computed the approximated Bayes factors for data with
The logarithm of the approximated Bayes factors can be found in Figure 2. Based on the approximated Bayes factors of M1 versus M

The logarithm of the approximated Bayes factors based on the unit information prior
The evidence for M1 against M
Error Probabilities
Next, we investigate the probabilities of selecting the true data generating model when including order constraints in the alternative model or not. First, we consider testing the null model,
Figure 3 displays the error probabilities as a function of the sample size (on a log scale). All the criteria show consistent behavior in the sense that the error probabilities go to 0 as the sample size grows. Furthermore, we see that when M0 is true (upper left panel), the error probabilities are very similar and the ordinary BIC in test 1 results in the smallest errors. In the case of a true effect in the direction of the order constraints of M1, we see that the order-constrained BIC based on the local unit-information prior results in considerably smaller errors than the other criteria.

Probability of selecting the wrong model when using the ordinary Bayesian information criterion (BIC) for testing
The error probabilities of the order-constrained BIC based on the local unit-information prior were only slightly larger in the case of a nonzero effect. This is partly a consequence of the design of the test having three instead of two models under investigation. We conclude that overall, the order-constrained BIC based on the local unit-information prior performs best in terms of error probabilities.
Approximation Errors of the Order-constrained BICs
Finally, we investigated the relative approximation errors of the order-constrained BICs by comparing them to nonapproximated counterparts, for example,
The results can be found in Figure 4. As can be seen from the left panel, the relative error goes to 0 fast when the effects are in agreement with the order constraints of model M1. When the effect are not in agreement with the constraints (right panel), we see that the relative error does not go to zero. This is a consequence of the somewhat crude approximation we already observed in Figure 1 (red line). The approximation error, however, is not large enough to be a serious practical problem. Other settings resulted in qualitatively similar results.
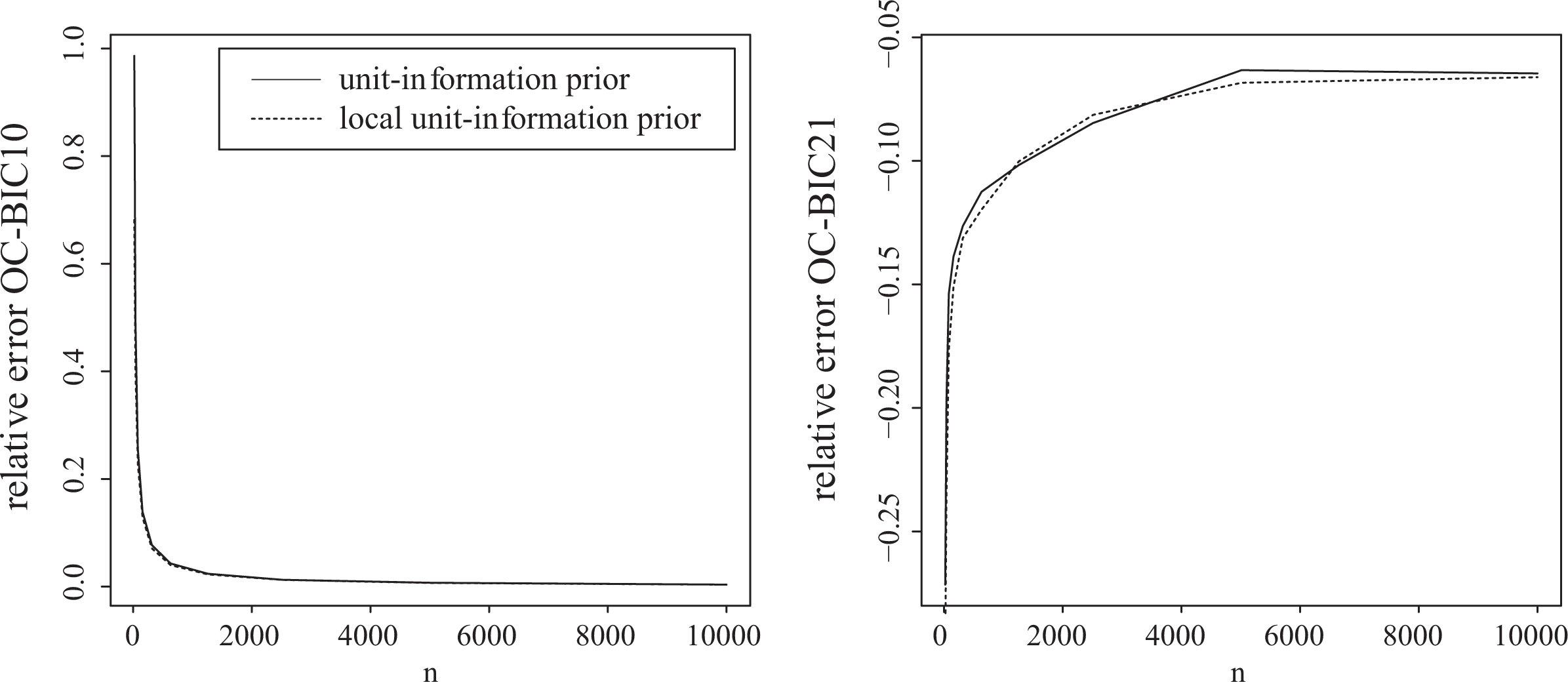
Left panel: Relative approximation error of the order-constrained Bayesian information criterion (BIC) of
Software
The
For example, in the case of a regression model with three predictors, say,
The use of the function will be illustrated in two empirical applications in the next section.
Empirical Applications Revisited
The models from the applications in the second section are evaluated using the order-constrained BIC based on the local unit information prior using the
Application 1: Assessing the Importance of Different Dimensions of Socioeconomic Status
Model 1 can be fitted in
The estimated coefficients of interest were
The order-constrained BIC for model
This resulted in a BIC of 3,918.46. The function also provides the posterior probability that the constraints hold under the unconstrained model, which was equal to .50. Next, the BIC for model
The resulting order-constrained BIC was 3,921.98. For this set of constraints, the posterior probability under the unconstrained model equaled .18.
The BIC for model

where
The order-constrained BIC can then be computed based on the resulting fitted model:
This resulted in a BIC of 3,917.84.
Finally, to compute the BIC of the complement model
This resulted in a BIC of 3,926.13. The BIC values are summarized in Table 1. From these values, we can conclude that model M3 receives most support, but the evidence is negligible in comparison to the evidence for the order-constrained model M1, given the BIC difference of .62. 4 The evidence for M2 and M3 is considerably lower than for M1 and M3.
Order-constrained BICs and Posterior Model Probabilities for the Competing Models in Application 1.

For interpretation purposes, it can be useful to translate the BICs to posterior model probabilities. A posterior model probability quantifies the probability of the data having been generated by one of the models considered, after observing the data given certain prior model probabilities. This probability is conditional on the data having been generated by one of the models considered.
In this application, we assume equal prior probabilities for the models. The posterior model probabilities can be computed from the BIC values using the “
Application 2: The Importance of Postmaterialism for Young, Middle, and Old Generations
Because the outcome variable “postmaterialism” has an ordinal measurement level with three categories (“low,” “medium,” and “high”), an ordinal regression model can be fitted using the
In the fitted model, the “young” generation is the reference group, and dummy variables are created for the “middle” and “old” generation. These variables are called “
Thus, the order-constrained BIC of model
The resulting BIC equaled 3,154.82.
Next, the BIC of the null model
The resulting BIC was equal to 3,177.69.
Finally, the BIC of the complement model was computed. Similarly to the previous example, this can be done as follows:
This resulted in a BIC of 3,170.15. The BICs and respective posterior model probabilities can be found in Table 2. Clearly, there is overwhelming evidence for M1 which implies that postmaterialism has increased for younger generations.
Order-constrained BICs and Posterior Model Probabilities for the Competing Models in Application 2.

Finally, we show that the inclusion of order constraints in the alternative model results in more evidence against a null model if the order constraints are supported by the data. First, note that the BIC for the order-constrained model, M1, against the null model, M0, equals
Discussion
We have presented two extensions of the BIC for evaluating models with order constraints on certain parameters of interest. In the first extension, a truncated unit information prior was considered under the order-constrained model, and in the second extension, a truncated local unit information prior was considered. Theoretical considerations and numerical analyses revealed that the local unit information prior resulted in better model selection behavior than the nonlocal unit information prior for order-constrained model selection.
The new order-constrained BIC based on the local unit-information prior can easily be computed using the new