
Abstract
1 Introduction
In exploratory analysis of observational medical data, many patterns of potential interest correspond to variations in event rates. Medical diagnoses, drug prescriptions and laboratory test results are all viewed naturally as discrete events. Sets of events may occur together more often (or rarely) than expected, or a given event may be unusually common or rare in a specific region, time period or age group, for example. The identification of excess co-reporting of certain suspected adverse drug reactions (ADRs) with specific medicines is at the core of post-marketing drug safety surveillance based on individual case safety reports.1,2 Several public health and individual patient safety issues have been first highlighted with statistical pattern discovery in this data.3,4 Recently, there has been increased interest in pattern discovery also for longitudinal patient records and medical claims.
Conceptually, patterns can be characterised as local structures that generate data with an anomalously high (or low) density relative to that expected under a global baseline model. 5 In the context of this article, we focus on the specific class of patterns that can be defined as contrasts between an observed and an expected number of events. The expected number is computed under an appropriate baseline model, and the choice of baseline model varies with the type of pattern under consideration. For pairs of events, the baseline model may be that events occur independently of one another; for measures of interaction, the baseline model may take into account lower order associations between pairs of events; and for patterns of temporal association a simple baseline model may be that the association between two events may be constant over person time.
An important consideration in selecting the measure of association for a given pattern discovery application is its relative emphasis on the strength of association versus the amount of data support. Measures based exclusively on statistical significance focus primarily on data support and are prone to highlighting weak associations of limited practical relevance. 2 The observed-to-expected (OE) ratio, on the other hand, focuses exclusively on the strength of association, but is volatile when the observed or expected numbers of events are low (in particular if the expected count is much lower than one). Shrinkage is a statistical approach to regularise a measure through moderation towards a null value, in the absence of enough data to support a deviation. For OE ratios, shrinkage towards 1 (no deviation) reduces the risk of highlighting spurious assocations while it retains emphasis on the practical relevance of any highlighted patterns. It has proven an effective compromise in a single measure between the strength of association and amount of data support in large-scale pattern discovery. 2 Shrinkage OE ratios have been used routinely for over a decade in pattern discovery of ADR surveillance data, 1 and have been shown useful in other applications including the analysis of international telephone call data. 6 A key rate limiter for their widespread adoption may have been the technical complexity of currently available shrinkage transformations, such as the complex set of priors in Norén et al. 7 and the bimodal five parameter prior distribution in DuMouchel 2 which can be challenging to implement, and hard to interpret for those responsible to clinically assess highlighted patterns. In contrast, we have recently implemented shrinkage OE ratios for higher order interactions 8 and temporal pattern discovery 9 using a simple shrinkage transformation which is more transparent and can be computed at the back of an envelope. In this article, we propose broader use of the simple shrinkage transformation and outline a range of patterns that are naturally viewed in terms of OE ratios.
2 OE ratios
Many measures of association for pattern discovery can be expressed in terms of contrasts between an observed number of events, and the expected number of events under an appropriate baseline model. In this section, we describe OE ratios for pairwise association, higher order interaction and temporal association. We also discuss how adjustment by stratification can eliminate the undue impact of other covariates on the OE ratio of interest, and the importance of visualisation.
2.1 Pairwise association
Most measures in large-scale pattern discovery are for pairwise association. This is true also for patterns involving more than two events, when the measure of association is based on grouping the events into two distinct subsets (e.g. a pairwise association between a medical diagnosis and the co-prescription of 
A simple OE ratio for the association between x and y relative to an independence baseline model can be computed based on the ratio of 

Relative risk-type measures such as the Proportional Reporting Ratio
10
provide a more distinct contrast between the observed and expected numbers of events by comparing 

An important limitation of (2) and (4) is that their ranges of possible values depend on the marginal frequencies of the events of interest. By definition, (1) cannot exceed 1/
The odds ratio is an alternative measure of association which can be estimated as:


Country variation in the reporting of

2.2 Contrasts
Contrasts expressed as ratios between OE ratios are OE ratios in their own right:

This is an attractive property that allows more sophisticated measures of association to be constructed. These derived OE ratios can be subjected to the same statistical shrinkage transformation, adjustment by stratification and visualisation, as simple OE ratios. They can be an effective basis to screen for variation in the strength of association across data subsets, and more specifically for interactions and temporal associations as described in Sections 2.3 and 2.4.
2.3 Interaction
The measures in Section 2.1 are for pairwise association only (whether between individual events or sets of events). Measures of interaction identify patterns of event co-occurrence that indicate an effect on the strength of association between two (sets of) events by a third (or more) event or covariate. Interaction can be measured as an OE ratio where the expected value is based on a regression model without the interaction term of interest.
6
Alternatively, interaction can be defined as a ratio of the pairwise OE ratio for x and y conditional on a third event z to the unconditional OE ratio for x and y (the measure is symmetrical in x, y and z).
7
For the OE ratio in (2):

Interaction as defined in (8) and with standard regression-based approaches, such as log-linear models and logistic regression, use a baseline model in which the individual effects of Schematic overview of an interaction between two conditions A and B relative to an additive baseine model. The bars correspond to the frequency of the event of interest (1) in the absence of both A and B, (2) with A but not B, (3) with B but not A, and (4) with A and B together. The shades correspond to: the marginal relative frequency of the event (lightest), the increased frequency attributable to A, the increased frequency attributable to B, and the increased frequency attributable to an interaction between A and B (darkest).
To illustrate the difference between these two types of baseline models for interaction detection, consider an event that is twice as common for women as for men, and twice as common for those above 65 years of age as for those below 65. In this case, the additive model predicts that the event should be approximately three times (1+(2−1)+(2−1)) as common for women above age 65 as for men below age 65 in the absence of interaction. Baseline models such as that for (8) on the other hand predict that the event should be approximately four times (1 · 2 · 2) as common for women above 65 years of age, because the relative risks essentially multiply for rare events. The additive baseline model has clear advantages as a basis for both individual decision-making and public policy-making. 13 Moreover, empirical results suggest that it is better suited to detect some patterns indicative of adverse drug interactions, at least in individual case safety reports. 8
2.4 Temporal association
Temporal patterns relating the occurrence of one event to another in time are of interest in the analysis of longitudinal patient records and medical claims. Elevated rates of a medical diagnosis relative to the prescription of a certain medicine may indicate a safety issue (if subsequent to prescription) or an indication for treatment (if prior to prescription). Lowered rates of a medical diagnosis can reflect beneficial effects (if subsequent to prescription) or contra-indications (if prior to prescription). Similarly, associations over time in the prescription of different medicines relative to one another may represent switching patterns. A framework for temporal pattern discovery in longitudinal observational databases based on OE ratios has previously been described.
9
It computes OE ratios for the number of times that one event (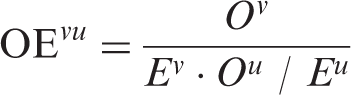
Traditional epidemiological designs can be leveraged to yield sophisticated OE ratios for the purpose of exploratory analysis, beyond the methodology described here. For example, some measures from cohort and self-controlled designs are directly interpretable as OE ratios and can be subjected to statistical shrinkage in order to provide robust but relevant effect measures in pattern discovery for patient records and medical claims.
2.5 Adjustment by stratification
In the analysis of observational data, events or covariates other than those of primary interest may distort the association under scrutiny. An association between a childhood vaccine and abnormal crying might, for example, be driven by the fact that both events are common in young children. Indeed, there may be no association, or an association in the opposite direction, if different age groups are studied separately. This is an example of confounding. Stratification is a simple but transparent approach to reduce the negative impact of suspected confounding by analysing subsets (as specified by the suspected confounders) of the data separately. An overall OE ratio adjusted for suspected confounders can be obtained as a weighted average of stratum-specific OE ratios in which the OE ratio for each subset is weighted by the corresponding expected number of events 
2.6 Visualisation
Shrinkage OE ratios are a natural basis for visualisation. They are especially powerful in combination with information on the underlying observed and expected counts, as these counts provide a direct link to the empirical basis of any observed pattern.
At the core of the temporal pattern discovery methods for patient records in Norén et al.
9
is a graphical statistical approach to visualising temporal association, referred to as the chronograph. Figure 2 provides an example from the analysis of electronic patient records. Its upper panel plots the log OE ratio with uncertainty intervals (subjected to the shrinkage transformation to be introduced in Section 3.1) for diagnoses of swelling in different time periods relative to prescriptions of an antihypertensive medicine. The lower panel depicts the corresponding observed and expected numbers of events. An asterisk depicts the rates for the day of the first prescription.
Visualisation of OE ratios over time, for the association in a collection of electronic patient records between first prescriptions of an antihypertensive medicine and diagnoses of swelling. The top panel displays the logarithm of the OE ratio (with shrinkage) over time. The bottom panel displays the underlying observed and expected numbers of events. Reproduced from Norén et al. [9] with permission from Springer.
The shrinkage OE ratio in the upper panel of the chronograph compensates for some systematic variability that may otherwise distort the analysis: it is not biased by the greater tendency of medical events to be recorded if they occur close in time to a prescription, or of truncation and censoring,
9
as reflected by a peak in the expected number of events around time 0 in Figure 2. The lower panel of the chronograph is more sensitive to systematic variability but highlights absolute differences between the observed and expected, and provides direct insight into the empirical basis for the upper graph. While limited to a specific pair of events, the chronograph spans a multitude of time intervals before and after the index event,
Figure 3 provides another visualisation of OE ratios – in this instance for the association between fluoxetine and neonatal withdrawal syndrome in the WHO Global Individual Case Safety Reports database, VigiBase. It illustrates the evolution over time as data accumulates on this safety issue first highlighted in Sanz et al.
3
Visualisation of the retrospective evolution over time of the OE ratio for the association between fluoxetine and neonatal withdrawal syndrome in the WHO Global Individual Case Safety Reports database, VigiBase. The top panel displays the logarithm of the OE ratio (with shrinkage) over time. The bottom panel displays the underlying observed and expected numbers of events.
3 Shrinkage
Statistical shrinkage is the regularisation of an estimate by evaluating several parameters simultaneously or by combining data with external information or assumptions. It is inherent in the Bayesian approach to statistical inference, where the posterior distribution provides a compromise between the observed data likelihood and an assumed prior distribution. However, shrinkage estimators were first proposed by Stein and colleagues as an approach to achieve lower quadratic loss in frequentist analysis. 15
From a practical perspective, shrinkage regularises a volatile measure by introducing a bias towards a null value in exchange for better variance properties. In large-scale pattern discovery, shrinkage of the OE ratio towards 1 provides protection against highlighting spurious associations. In Section 3.1, we present a simple shrinkage transformation applicable to any OE ratio. This transformation is a generalisation of the shrinkage previously applied to measures of interaction
8
and temporal association.
9
Like the EBGM measure, it is based on a Gamma-Poisson model,
2
but it uses a much simpler parametric form and allows, but does not require empirical Bayes re-estimation. It combines observed data with a prior assumption that the baseline model used to compute the expected count holds. For a given choice of parameter values, its properties are very similar to those of the more complex shrinkage transformations previously proposed for the
3.1 Simple shrinkage transformation
Consider an OE ratio with observed number of events 
Formally, (11) can be viewed as the Bayeisan posterior mean of a parameter μ under the assumption that
The logarithm of the OE ratio is a convenient measure of association in the sense that its sign indicates the direction of the association and its magnitude measures the strength of positive and negative associations on comparable scales – for the base 2 logarithm, every unit shift corresponds to a doubling or halving of the OE ratio. The above shrinkage transformation extends directly, so that shrunk log2 OE ratios can be computed as:



An approximate similarity between (12) with α1 = α2 = 1 and an earlier implementation of the
3.2 Variations
The appropriate choice of α1 and α2 will vary depending on the application. Higher α1 and α2 values provide stronger protection against highlighting spurious associations, and an α1/α2 ratio other than 1 will provide shrinkage towards a different null value, which may be motivated if there is prior information to suggest that two events are associated one way or the other (such as perhaps information from a pre-approval randomised controlled trial).
As an alternative to manually selecting the α values, an empirical Bayes approach can be used in which the prior distribution is fitted to the empirical distribution of unshrunk OE ratios for a large set of event pairs. 2 With such an approach, the prior will vary with the data set to be analysed, and will also vary for a given data set as it evolves over time. Some implementations have included only event pairs with observed counts greater than or equal to 1 in the fitting of the prior distribution, 2 but this will bias the prior towards higher values, since true negative associations are more likely than true positive associations to result in zero counts. If used as a basis for empirical Bayes estimation, the simple prior distribution in Section 3.1 will be easy to fit, robust to fluctuations in data (see the discussion of hyper-parameter identifiability in DuMouchel 2 ) and allow for a direct interpretation of the fitted parameters in terms of the strength and the direction of the shrinkage. The one-component Gamma distribution may not always fit the empirical distribution of OE ratios as well as the more flexible two-component Gamma distribution used in DuMouchel, 2 but this can be expected to have limited practical impact relative to the other distortions in large-scale pattern discovery in observational data.
4 Discussion
Patterns of pairwise association, higher order interaction, and temporal association, can all be quantified in terms of OE ratios. The OE ratio is conceptually intuitive and reflects the extent to which an observed pattern deviates from the assumed baseline model. Large relative differences between the observed and the expected tend to signify patterns of practical importance, and the OE ratio can be useful for comparing strength of association across different data subsets. A fundamental limitation of raw OE ratios is that they are sensitive to random variability. They are particularly volatile when the expected number of events is low, which is problematic for applications such as drug safety surveillance in which rare events can be critically important.
2
Statistical shrinkage reduces the negative impact of artificially low expected counts, and stabilises the OE ratio in their presence. In combination with uncertainty intervals, it reduces the risk of highlighting spurious associations. It does not explictly account for the multiple comparisons inherent in large-scale pattern discovery and will not control the familywise Type 1 error rate (the probability of
The absence of a complex statistical superstructure for the shrinkage transformation in Section 3.1 is a clear advantage over the computationally more sophisticated alternatives in Bate et al., 1 DuMouchel 2 and Norén et al. 7 The simple form of (11) retains a clear link to the underlying OE ratio, and makes explicit the reliance on the underlying baseline model. To further emphasise the importance of the empirical basis for highlighted patterns, we recommend that observed and expected numbers of events always accompany quoted OE ratios, as in the graphical displays of Figures 2 and 3. This reduces the risk that the shrinkage transformation diverts domain experts from careful consideration of alternative explanations to outstanding quantitative associations. As an example, in the presence of suspected duplicate data points that contribute to an observed count, 20 simple arithmetics will indicate to what extent duplication can explain a large OE ratio, whereas more complex methods may require the entire analysis to be repeated. 21
That said, there are patterns for which the OE ratio is not the most appropriate measure of association. For example, the practical relevance of highlighted patterns might in some applications be better measured in terms of absolute differences between the observed and expected numbers of events. 6 Confounding is a fundamental challenge in the analysis of observational data. Adjustment by stratification can under certain circumstances reduce the unwanted impact of a limited number of suspected confounders, as outlined in Section 2.5. However, it is most suitable for categorical variables, whereas for numerical covariates a discretisation is required that can be delicate and sometimes inappropriate. Moreover, adjustment by stratification is only appropriate in the absence of effect modification and is not feasible in the presence of moderate to large numbers of suspected confounders. Methods such as propensity scores that reduce the dimensionality of the suspected confounders can potentially offer some relief in those circumstances. Shrinkage regression is an alternative approach that has been successfully applied to the analysis of individual case safety reports in the presence of confounding by co-reported medicines.22,23 Its main advantage is that it can incorporate a large number of suspected confounders simultaneously and can naturally accommodate both discrete and numerical covariates. Its efficiency stems from the underlying model's assumptions of linearity (on some scale), which may not always be fulfilled. Regardless of the method for adjustment, confounding by unmeasured covariates remains a potential source of mis-interpretation that should always be considered in the analysis of outstanding reporting patterns.
There are clear advantages of using the same shrinkage OE ratio as the basis for a broad range of pattern discovery applications, as proposed in this article. It allows experience of the shrinkage transformation for one OE ratio to be benefited from by another. As highlighted in Section 2.1, the odds ratio can be re-expressed as an OE ratio and subjected to the simple shrinkage transformation in Section 3, thus adding effective protection against spurious associations to its list of desirable properties. Similarly, the adjustment by stratification first proposed for pairwise associations in DuMouchel 2 can be directly applied to the measure of interaction in Norén et al. 8 or to the temporal pattern discovery framework in Norén et al. 9