
Abstract
Keywords
Introduction
Achieving good speech intelligibility is one of the prioritised goals in designing the acoustics of rooms. Despite being a critical factor in room acoustics design, speech intelligibility can be easily compromised when the space is noisy due to auditory masking. 1 Nevertheless, the human hearing system has various countermeasures to address the issue. 2 The benefit of binaural hearing, that is, hearing sound by two ears, enables us to capture spatial acoustics, which characterises the spatial properties of sound propagation in the space. While binaural hearing brings significant benefits in understanding speech in noise such as the effect of spatial release from marking,3,4 the benefits it brings are also subject to the spatial acoustics of environments. Many previous studies have investigated how the spatial acoustics of environments would affect the benefits.5–8
Although it is a common practice in speech and hearing research to conduct subjective listening tests for measuring speech perception in noise, the tests have to be conducted under controlled and reproducible settings. Such requirements are normally satisfied by undertaking the test in a laboratory such as an anechoic chamber or acoustically treated/insulated listening booth. However, when the focus of the study is in investigating the effect of spatial acoustics of environments, it is infeasible to conduct the test in these laboratory settings because the acoustics of environments has to be varied widely to cover various acoustical environments typically seen in real-world. Historically, studies looking into the effect of room acoustics on speech perception are typically conducted using stimuli by adding artificially simulated acoustical effects (e.g. Rogers et al. 9 and Masuda 10 ), which does not necessarily represent real acoustical environments.
Over the last few decades, spatial sound reproduction 11 has emerged which allows users to virtually experience various acoustic environments without visiting the actual sites. Using spatial sound reproduction has various benefits to address the challenge in speech and hearing research thanks to their ability in delivering realistic but also controllable and reproducible spatial acoustics experience to the participants. 12 Several recent studies have adopted this methodology and conducted subjective listening tests examining the effect of varying room acoustics on the intelligibility of speech in noise using state-of-the-art spatial sound reproduction.7,13,14 However, a question regarding reproducibility remains; “How accurately would the results collected under reproduced acoustic environments replicate the results collected in the real environment (had it been ever feasible)?” To answer this crucial but non-trivial question, a previous study 15 compared speech intelligibility in noise between a real room and its reproduced acoustic environments realised by Ambisonics technology. 16 Ambisonics is one of the most commonly used technologies to realise spatial sound reproduction where the original sound environment is described by the spherical harmonics (We call such technology spherical harmonics-based spatial sound reproduction hereafter.). 17 The technology is implemented by measuring the sound in the original environment using an array of microphones encoded by spherical harmonics, and then the sound field in the original environment is reproduced by rendering the recordings processed by a decoder from either a headphone or loudspeaker array. In the previous study, 15 a 64-ch loudspeaker array was used for rendering sound while recording was achieved by either numerical simulation or practical measurement of the room impulse response (RIR) in the real room using a 52-ch spherical microphone array. The study found the results collected in reproduced acoustic environments that used the measured RIRs provided the highest match to the results collected in the real environments. Another study 18 investigated the differences in speech perception between real and reproduced acoustic environments by recruiting both normal hearing and hearing impaired listeners. The study also used the same 64-ch loudspeaker array with a 32-ch microphone array for recording the RIRs.
While these previous studies have provided great insights into the validity and limitations of the methodology using spatial sound reproduction in speech and hearing research, the microphone and loudspeaker arrays used in these studies are often not accessible for many researchers due to their high cost. With spherical harmonics-based spatial sound reproduction, the reproduction accuracy of the acoustics in the original space strongly depends on the order of spherical harmonics the implemented system can realise, 19 which is governed by the number of microphones used for recording sound as well as the number of loudspeakers used for rendering sound. Fortunately, more varieties of equipment designed for implementing spherical harmonics-based spatial sound reproduction are available in the recent market, some of which are much more affordable and accessible. For microphones, many products use only four microphones, typically arranged in a tetrahedral shape, being able to realise only up to first order spherical harmonics, known as first order Ambisonics (FoA) microphones. Other equipment uses many more microphones to enable higher order spherical harmonics, known as higher order Ambisonics (HoA) microphones, however, such equipment is often less affordable than the FoA counterparts. Likewise for rendering, the most commonly used technique is binaural rendering via headphones because of their affordability for most users. However, their reproduction accuracy may be compromised when it is used with Ambisonics microphones because the recordings would not allow accurate modelling of the directivity pattern of human ears. Compounded with the fact that the sound recorded by the Ambisonics microphones is already an approximation due to the limited spherical harmonics order, the technique would suffer from low reproduction accuracy. In addition, it also relies on the average head related transfer function (HRTF) measured by a head and torso simulator, which is often different from individual’s HRTF. An alternative to address these issues is using an array of loudspeakers, which physically reproduces the sound field measured in the original environment inside the loudspeaker array where listeners are seated. However, the system is not as accessible as binaural rendering since it requires dozens of loudspeakers installed in an anechoic chamber. These differences in recording/rendering techniques imply the results collected under reproduced acoustic environments implemented with different recording/rendering techniques would vary and may not eventually match well with the results collected in the real acoustic environments. For example, a few previous studies investigated the spatial release from masking under reproduced acoustic environments realised by as low as first order spherical harmonics and by rendering sound via headphone 20 or loudspeaker array.15,21 However, no previous study has compared speech intelligibility under reproduced acoustic environments realised by different means of audio recording/rendering techniques, for example, headphone versus loudspeaker array, as well as against that in real acoustic environments.
The present study investigates the differences in speech intelligibility in noise, including the benefit from spatial release from masking focussed in the previous studies, measured under spherical harmonics-based spatial sound reproduction implemented by various means of recording/rendering techniques. The study discusses the reproducibility of data collected in the real environments using spherical harmonics-based spatial sound reproduction by comparing the results from reproduced acoustic environments and real rooms. The study will answer the research question: (1) “How do varying implementations of spherical harmonics-based spatial sound reproduction differ in replicating speech intelligibility in noise in real rooms?” In addition, the study will also investigate: (2) “How does the effect of spatial acoustics on speech perception vary under different implementations?” Here, “implementation” refers to the recording/rendering equipment rather than the technology for realising spatial sound reproduction itself such as the order of spherical harmonics used for recording or the algorithms used for rendering. We hypothesise that the implementation using HoA microphone with loudspeaker array, which is able to deliver more accurate reproduction of the original acoustic environment using higher order spherical harmonics without suffering from the limited channel number/HRTF mismatches, would deliver the best matching results to that collected from the real acoustic environments including the effect of spatial acoustics. While the present study utilises SPARTA suite (https://leomccormack.github.io/sparta-site/), an open-source state-of-the-art spatial sound reproduction plugin available online, as an example of spherical harmonics-based spatial sound reproduction technique because of its high accessibility, the study does not intend to discuss the difference of performance between various spatial sound reproduction techniques. Through findings from the current study, we rather aim to allow users of spherical harmonics-based spatial sound reproduction for speech and hearing research to make an informed decision on the choice of their implementation design.
Methodology
Subjective listening tests were conducted to measure speech intelligibility in noise under spherical harmonics-based spatial sound reproduction implemented by different combinations of recording and rendering techniques. To acquire baseline data, the same test was also conducted in real (original) rooms the acoustics of which was reproduced. The results collected from both the real rooms and reproduced acoustic environments were compared. This section summarises the design of the listening tests along with the details of the spatial sound reproduction implemented in this study.
Venues and their acoustics
To cover acoustic environments with broad conditions seen in real-world, two venues with varying acoustics were used in this study, which were the seminar room (#405-430) and the MacLaurin Chapel (#107-G03), both at the University of Auckland, New Zealand, shown in Figure 1. The listening tests in real rooms were conducted in these venues. The tests under reproduced acoustic environments were conducted in the anechoic chamber of the Acoustics Laboratory at the University of Auckland (Figure 2) by replicating the acoustics measured in the seminar room and chapel by using the selected implementations of spatial sound reproduction discussed in the next section. The seminar room has a moderate reverberation, with the reverberation time (

Venues used in the current study for conducting the listening test in real room as well as measuring the room impulse responses to virtually replicate their acoustics using spatial sound reproduction: (a) seminar room (#405-430) and (b) MacLaurin Chapel (#107-G03).

The first author seated at the centre of the 32-ch loudspeaker array installed in the anechoic chamber at the University of Auckland.
Acoustics at the centre of the rooms when the sound source was located at one of the eight positions in the rooms (4 angles
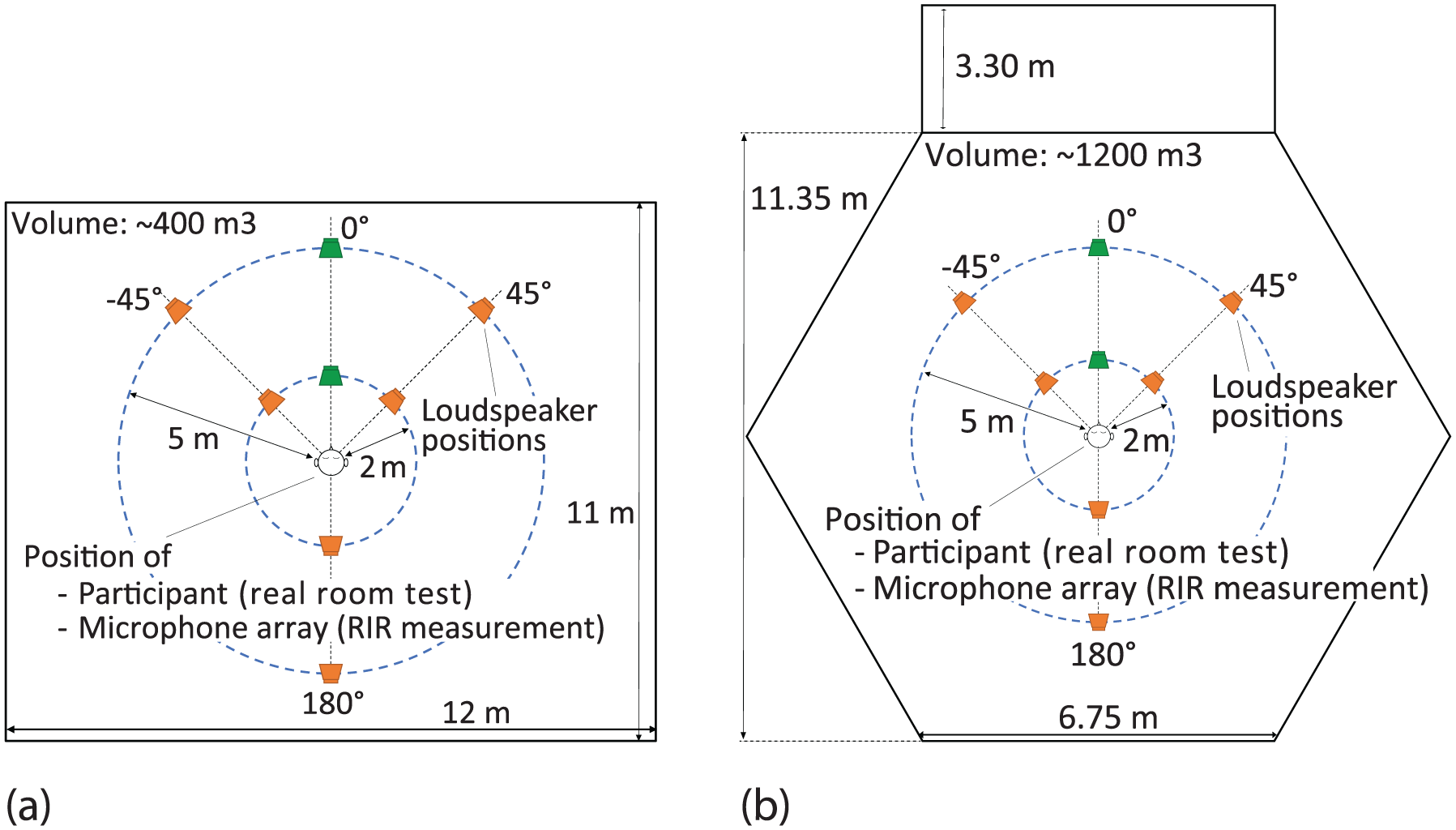
Dimension and volume of the rooms used in the current study with the positions of sound sources and participants. The location of the target speech was fixed at one of the green loudspeaker icons, whereas the location of the noise source was varied between the locations of both green and orange loudspeaker icons. The distance of the target speech and noise was kept the same, that is, either 2 m or 5 m. (a) Seminar room and (b) chapel.
Spatial sound reproduction implementation
The study adopted the SPARTA suite as an example of spherical harmonics-based spatial sound reproduction. It was implemented by combinations of two different recording and rendering techniques with varying accessibility, resulting in four different implementations as summarised in Table 1. Among the four implementations, F-Bi would be the most accessible technique realised by a FoA microphone and a headphone whereas H-Spk would be the most costly setup requiring large numbers of microphones and loudspeakers. Details of the techniques used for recording and rendering are summarised below.
Reproduced acoustic environments tested in the experiment by varying implementation techniques.

Recording
Same as the previous studies,15,18 recording of room acoustics was realised by measuring the room impulse responses (RIRs) of the targeted venues. Two types of microphone array were used for measuring the RIRs: (i) FoA microphone (Røde NT-SF1) and (ii) HoA microphone (MH acoustics Eigenmike em32). NT-SF1 is a tetrahedral microphone array with four unidirectional microphones, which is able to record only the first order spherical harmonics signals (frequency response: 20 Hz–20 kHz, equivalent noise level: 17 dBA). Eigenmike em32 has 32 microphones embedded on a rigid sphere, which is able to describe recorded sound by up to the fourth order spherical harmonics (frequency response: 30 Hz–20 kHz, equivalent noise level: 15 dBA).
The RIRs were measured by playing a swept sine signal from the loudspeaker (Genelec 8020D) located at one of the eight positions in the rooms while recording the sound by the microphone array located at the centre of the rooms (Figure 3; The measured RIRs are available from https://doi.org/10.17605/OSF.IO/ZWPF3). The length of the measured RIRs was 2 s for the seminar room and 2.5 s for the chapel. Figure 4 shows the energy decay curves
22
of the RIRs measured by the FoA and HoA microphones in each room (To remove the effect of microphones’ directivity, the 0th order spherical harmonics (equivalent to omni-directional) of the full-band RIRs were used to calculate the decay curves.). The measured RIRs were then transformed to spherical harmonics signals (called
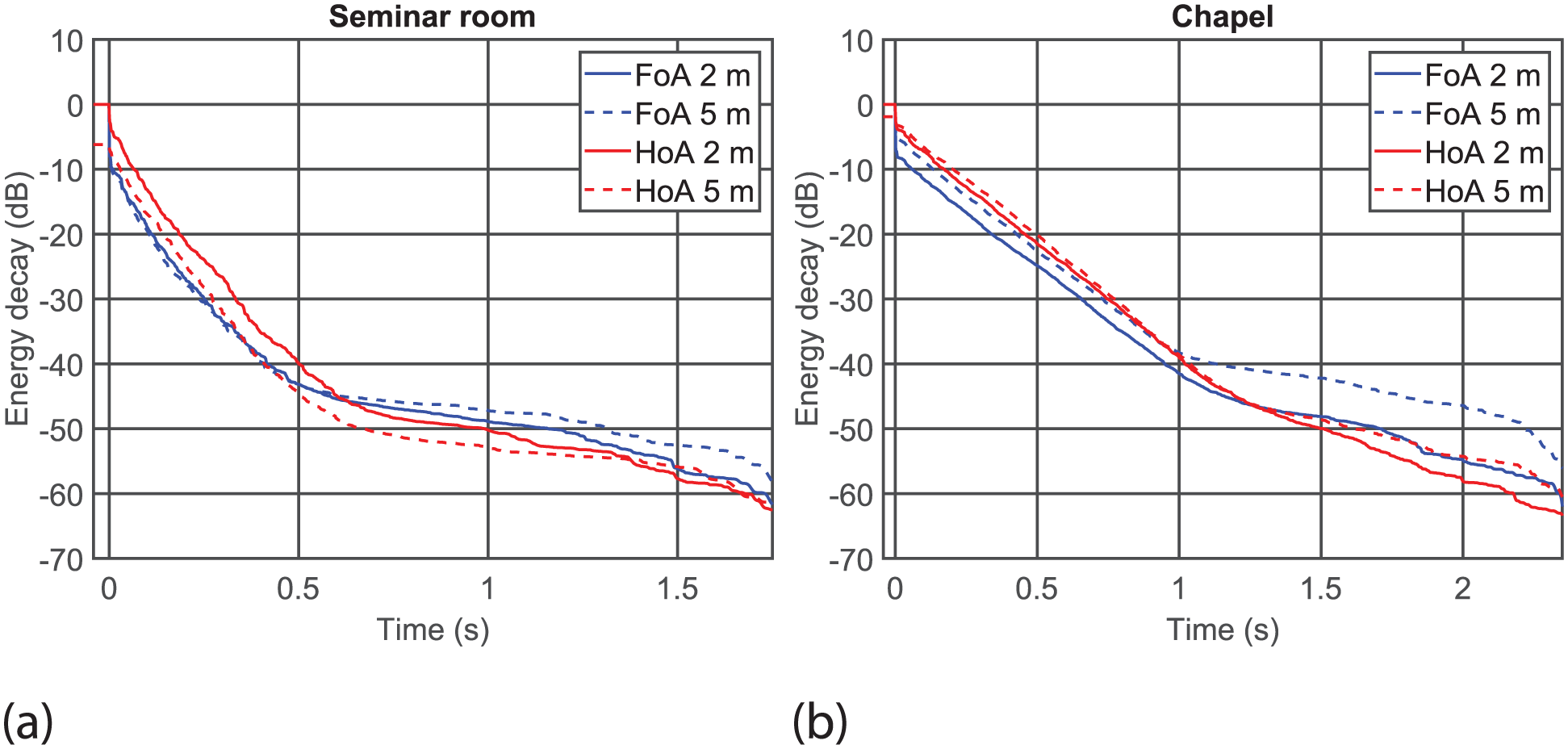
Energy decay curve of the room impulse responses (full-band, source angle 0°) measured by the FoA and HoA microphones converted to the 0th order spherical harmonics signal (omni-directional). The energy of direct sound propagating from sources located at 2 m is normalised to 0 dB. Solid lines: 2 m, dashed lines: 5 m, blue lines: FoA microphone, red lines: HoA microphone. (a) Seminar room and (b) chapel.
Rendering
Two rendering techniques were utilised: (i) binaural rendering using a headphone (Sennheiser HD800S) and (ii) rendering from a 32-ch loudspeaker (Genelec 8020D) array. For binaural rendering, the spherical harmonics RIRs were decoded into binaural RIRs by the SPARTA plugin AmbiBIN with the magnitude least-squares (MagLS).
24
A preset HRTF wrapped in the plugin was used. The stimuli used in the listening test were generated by convolving an arbitrary sound source with the binaural RIRs, which were then played through the headphone via an audio interface (Roland OCTA-CAPTURE). The loudspeaker array was configured as shown in Figure 5 and installed in the anechoic chamber (Figure 2). Similar to binaural rendering, the spherical harmonics RIRs were decoded by SPARTA plugin HO-SIRR
25
into 32-ch RIRs corresponding to each loudspeaker by using the coordinates of the loudspeakers as a parameter. The resultant RIRs were then convolved with an arbitrary sound source to generate the stimuli. The rest of the loudspeaker array’s implementation was the same as that reported in Hui et al.
14
For both rendering techniques, the sampling rate of the stimuli was set to

Configuration of the 32-ch loudspeaker array.
Stimuli
The stimuli used in the test comprised of target speech and noise, which were rendered simultaneously to replicate noisy speech. The target speech was chosen from the Bamford-Kowal-Bench et al. (BKB) sentence lists
26
in the Speech Perception Assessments New Zealand (SPANZ) corpus
27
and the noise was the babble noise from the NOISEX-92 corpus.
28
The target speech and noise were played at 50 dBA and 53 dBA (
Participants
In total 76 participants were recruited in Auckland, New Zealand, for the listening test, consisting of the following five groups.
• Group 1 (
• Group 2 (
• Group 3 (
• Group 4 (
• Group 5 (
All participants were native listeners of English familiar with New Zealand English and self-reported that they had normal hearing.
Procedure
In the listening test, participants were asked to transcribe speech sentences they listened to under noise through the graphical user interface displayed on a monitor located in front (
The participants typed in their responses through a keyboard while looking at the monitor in front of them (
Marking and statistical analysis
To quantify speech intelligibility, the participants’ responses were marked according to the marking schedule recommended in the SPANZ corpus
27
by scoring the root of the word as opposed to the whole word. Details of the marking process followed that used in the previous study.
14
The resultant intelligibility scores normalised from 0 to 1, called
Results
Figures 6 and 7 display the speech intelligibility scores (proportion correct) predicted by the linear mixed effect models in terms of speech-noise separation split by the source distance and implementation, respectively. For the seminar room, two-way interaction was found between speech-noise separation and implementation (

Linear prediction of proportion correct in terms of speech-noise separation split by sound source distance. Error bars show 99% confidence intervals: (a) seminar room and (b) chapel.

Linear prediction of proportion correct in terms of speech-noise separation split by implementation. Error bars show 99% confidence intervals: (a) seminar room and (b) chapel.
Effect of implementation
From visual inspection of Figure 6, overall the speech intelligibility under reproduced acoustic environments is lower than that in the real room and varied between implementation when the amount of reverberation is moderate (seminar room). When the amount of reverberation is high (chapel), the speech intelligibility scores are mostly similar between the real room and reproduced acoustic environments. These observations are confirmed by Tables 2 and 3, which show the pairwise contrast of proportion correct between implementations for the seminar room and chapel, respectively. From the contrast between the real room and reproduced acoustic environments (top four blocks of the tables), in the seminar room, the difference in speech intelligibility under reproduced acoustic environments is mostly significantly lower than that in the real room regardless of implementation except F-Spk, some cases from F-Bi (
Pairwise contrasts between implementation for the seminar room.

Pairwise contrasts between implementation for the chapel.

Among the reproduced acoustic environments (bottom six blocks of Tables 2 and 3), while no explicit trends can be observed in both rooms, no significant pairs are detected between F-Spk and H-Spk in the chapel, suggesting both implementations performed similarly in terms of replicating speech intelligibility. This trend is not clearly observed in the seminar room, where a significant difference is observed at
Effect of speech-noise separation
The effect of speech-noise separation can be used to quantify the effect of spatial release from masking
4
by inspecting the “dip” caused by the difference of proportion correct between
Tables 4 and 5 display the pairwise contrast of proportion correct between
Pairwise comparisons of contrasts between speech-noise separation for the seminar room.

Pairwise comparisons of contrasts between speech-noise separation for the chapel.

For the difference between
Effect of source distance
From Figure 7, clear separation can be seen between source distance (2 m or 5 m) regardless of implementation or the venue. In both the seminar room and chapel, the difference in speech intelligibility between source distance is significant in all implementations of reproduced acoustic environment as well as in the real rooms, as reported in Tables 6 and 7, respectively. These results suggest that speech intelligibility improved regardless of implementation or speech-noise separation when the sound source was closer to the listener.
Pairwise contrasts between distances (2–5 m) for the seminar room.

Pairwise contrasts between distances (2–5 m) for the chapel.

Discussion
As discussed in Introduction, the current study aims to answer the research questions: (1) “How do varying implementations of spherical harmonics-based spatial sound reproduction differ in replicating speech intelligibility in noise in real rooms?” and (2) “How does the effect of spatial acoustics on speech perception vary under different implementations?” We hypothesise that speech perception under the implementation using the HoA microphone and loudspeaker array (H-Spk) would provide the results closest to that observed in the real room because such an implementation is able to describe sound field more accurately with signals of higher spherical harmonics order without being affected by the disadvantages of binaural rendering. For the same reason, it is hypothesised that the implementation using lower spherical harmonics and binaural rendering (F-Bi) would be the least accurate in terms of replicating speech perception in the real room. Hence, we expect the results from H-Spk would assimilate the results in the real room the best whereas the results from F-Bi would deviate the most from the real room data. This section discusses the results to test these hypotheses and answer the research questions.
Reproducibility of speech intelligibility in real rooms
To answer question 1, we first look into how the speech intelligibility scores (proportion correct) collected from reproduced acoustic environments assimilate with the results in the real rooms. In the results, the trend is somewhat different between the rooms, hence we discuss the results for each room separately.
In the seminar room, according to the post-hoc test results (Table 2), the proportion correct between the real room and reproduced acoustic environments is significantly different in most cases regardless of implementation. The only exception is F-Spk where no significant difference was observed at every speech-noise separation angle examined. Among the reproduced acoustic environments, all implementation pairs observed significant differences at some speech-noise separation angles, indicating the implementation affects the reproducibility of speech intelligibility. Contrary to the hypothesis, only F-Spk successfully replicated the speech intelligibility in the real room (i.e. provided proportion correct not significantly different from that of the real room). From Figure 6(a), both H-Bi and H-Spk show larger drop of proportion correct in
This trend suggests the extent of reduction in speech intelligibility when the target speech and noise are co-located/located front-and-back was exaggerated under reproduced acoustic environments using HoA microphone. It is also notable that, according to the magnitude of the estimate values in Table 2, deviation from the results in the real room is smaller when the 32-ch loudspeaker array is used for rendering with the same recording technique (F-Bi vs F-Spk and H-Bi vs H-Spk) at all tested angles. While further study is required to draw a solid conclusion in terms of the effect of recording technique, the results suggest implementations using the 32-ch loudspeaker array for rendering would be superior to using binaural rendering based on Ambisonics recording for replicating speech intelligibility measured in a moderately reverberant environment (seminar room).
On the other hand, in the chapel, the post-hoc test results (Table 3) show that F-Spk and H-Spk observed no significant difference from the real room in terms of proportion correct whereas F-Bi and H-Bi observed significantly lower score at
Overall, these observations indicate that the hypothesis in terms of implementation with the best reproducibility was partially supported in the highly reverberant environment (chapel) where H-Spk (along with F-Spk) replicated the speech intelligibility in the real room without significant difference. Contrary, the hypothesis was not supported in a moderately reverberant environment (seminar room) where only F-Spk replicated the speech intelligibility in the real room accurately. On the other hand, in terms of implementation with the worst reproducibility, while both F-Bi and H-Bi suffered from deviation from the real room results regardless of the room, surprisingly, in most angles/distances the extent of the deviation was larger in H-Bi than F-Bi. Hence, the hypothesis that F-Bi would be the implementation with the worst reproducibility was not supported.
Although the deviation from the real room was not significant with F-Spk in both rooms, the extent of the deviation was mostly larger in the seminar room compared to the chapel according to the magnitude of the estimate values (see F-Spk – Real room contrast in Tables 2 and 3). The same trend can be seen in reproduced acoustic environments using other implementations, which resulted in significantly different proportion correct between the real room and reproduced acoustic environments in many conditions. The larger deviation observed in the seminar room may have been caused by the length of the RIRs (2 s) being much longer than the reverberation time of the room (0.7 s). Typically a measured RIR includes noise which hinders replicating the energy decay of very late reverberation due to the effect of noise floor. 34 As can be seen in Figure 4, there is clear noise floor in the decay curves especially in the seminar room RIRs after around 0.6 s. This noise floor is likely caused by the ambient noise present in the rooms when the RIRs were measured, and/or the internal noise in the equipment used for the RIR measurements. While the level of noise floor in the RIRs were relatively low mostly below −40 dB, the noise floor at the tail of the RIRs may have appeared as additional reverberation in the stimuli after convolving the RIRs with speech. This could have eventually made the reproduced environment more reverberant than it was supposed to be resulting in degraded speech intelligibility due to reverberation.35,36 While further research would be required to confirm this, implementing methods that remove the effect of noise floor in the measured RIR such as truncating the RIR 37 may reduce the large deviation observed in the seminar room, which is open to future studies.
Reproducibility of the effect of spatial acoustics
The answer to question 2 is sought by investigating the effect of spatial acoustics, that is, speech-noise separation and source distance, on the results. To test if the aforementioned hypotheses are supported, we particularly investigate if the same effect is consistently observed between the real room and reproduced acoustic environments.
Speech-noise separation – Spatial release from masking
As previously discussed, the effect of spatial release from masking can be evaluated by measuring the depth of the dip between
On the other hand, under reproduced acoustic environments, previous studies have found that the effect of spatial release from masking is observed under environment represented by even first order harmonics signals (i.e. recorded using FoA microphone). It has been observed both under binaural rendering in anechoic environment 20 and under loudspeaker array rendering in various reverberant spaces with the source distance being 2.5 m. 21 In the current study, the effect is found at both source distances in the seminar room for H-Bi and H-Spk. In the chapel, the effect is observed for every implementation at 2 m but only for F-Bi at 5 m. Although direct comparison to the previous studies cannot be made due to the acoustic conditions and the spatial sound reproduction techniques not being identical, overall the results from the current study are aligned with that of the previous studies by finding the effect under reproduced acoustic environments.
In terms of agreement of the results regarding replicating the effect of spatial release from masking between the real room and reproduced acoustic environments, the result from H-Spk perfectly matches with that from the real room regardless of the room while H-Bi does so only in the seminar room. These facts suggest reproduced acoustic environments using HoA microphone and loudspeaker array rendering (H-Spk) would replicate the effect of spatial release from masking in the real rooms most accurately. The implementations using FoA microphone (F-Bi and F-Spk) suffered from mismatch (from the real room results) in the seminar room at 45° as well as in the chapel at 5 m. This supports the hypothesis that H-Spk has the most accurate reproducibility in terms of the effect of spatial release from masking observed in the real room. It is a plausible finding because sound reproduction using higher order spherical harmonics is able to provide better localisation accuracy especially around
Another interesting aspect in terms of speech-noise separation is the difference between
Source distance – Speech clarity (C50)
Source distance is another key factor in spatial acoustics that affects the intelligibility of speech. In an enclosure with reverberation, the level of direct sound exponentially decays by increasing the source distance while the level of reverberation remains relatively homogeneous across the space, resulting in speech intelligibility degradation at far source distances. The direct-to-reverberation ratio (DRR) 39 is a metric that quantifies this phenomenon by calculating the energy ratio between direct sound and reverberation, which shows a strong correlation with speech intelligibility. This has resulted in developing the commonly used speech clarity (C50) metric, a variant of DRR, as one of the objective metrics of speech intelligibility. 40 Based on this, in the current study, it is expected that the proportion correct between 2 and 5 m would be significantly different especially when the space is highly reverberant, that is, chapel.
According to the results in Tables 6 and 7, in the real rooms, the degradation of speech intelligibility by increasing source distance is clearly observed at all speech-noise separations both in the seminar room and chapel. This result clearly matches with the reports in previous studies undertaken in real reverberant acoustic environments, for example, Bradley. 41 Under reproduced acoustic environments, on the other hand, exactly the same trend was observed in both rooms; the proportion correct being significantly different between distance under all implementations, speech-noise separation and rooms. Hence, the effect of source distance on speech intelligibility can be accurately reproduced by any of the implementations tested.
Limitations
There are some limitations in the current study that need to be addressed in future studies. Firstly, the findings from the current study are limited to the specific hardware utilised to implement the spatial sound reproduction. The study also does not evaluate the technologies for realising spatial sound reproduction itself such as the order of spherical harmonics used for recording or the algorithms used for rendering. Also, due to the limitation on the number of stimuli tested by each participant to avoid fatigue as well as the logistical challenge of conducting experiments in real rooms, the study focussed only on two venues with two distances. Including more variety of acoustical environments in the experimental design may uncover more nuanced insights into the interaction between room acoustics and implementation of spatial sound reproduction. Similarly, due the number of participants in each group was relatively small, the results of the statistical analysis should be interpreted with caution.
Another limitation of the current study is its restricted scope by examining only a specific design of spatial sound reproduction and using only specific type of noise and venue, all due to time constraint that each participant could spend for the subjective listening test. Although the spherical harmonics-based spatial sound reproduction techniques23–25 used in the current study are well established, conclusions may vary if the same test was conducted under environments reproduced by different sound reproduction techniques. We note that the accuracy of spherical harmonics-based sound reproduction is subject to the order of spherical harmonics. Given that the order of spherical harmonics is finite, other commonly used techniques that are free from this restriction, such as using HRTF measured by head and torso simulator for binaural rendering, might deliver higher reproducibility than the implementations investigated in this study. For the noise type, the previous study 15 tested both speech and noise interferers and found that the interferer type interacts with the interferer location (corresponds to speech-noise separation in the current study). Further study involving varying types of noise is needed to investigate how noise type interacts with implementation. Similarly, another study focussing on the effect of varying room acoustics by conducting tests in various rooms would also provide insights on how room acoustics and implementation would interact with each other. These points remain as open questions to future studies.
Conclusion
The current study has investigated the speech intelligibility in noise measured under varying implementations of spherical harmonics-based spatial sound reproduction. To examine the reproducibility the results were compared against the data collected in the real rooms the acoustics of which was reproduced. The study hypothesised that the implementation using HoA microphone with loudspeaker array (H-Spk) would deliver the best matching results to that collected from the real rooms.
In terms of reproducibility of speech intelligibility, it was found that the hypothesis was partly supported in a highly reverberant environment, with both the F-Spk and H-Spk implementations having successfully replicated speech intelligibility observed in the real room. In the moderately reverberant room, however, the hypothesis was not supported by observing only the F-Spk implementation reproduced speech intelligibility in the real room. These results suggest that implementations using the 32-ch loudspeaker array for rendering would be superior to using binaural rendering. For recording, Based on the results of this study, higher reproducibility may be achieved by using the applied FoA microphone than the applied HoA microphone when the room is moderately reverberant. Nonetheless, further study by addressing the limitations of the current study would be required to confirm this. Overall, the study has found the technique used for rendering (binaural or 32-ch loudspeaker array) has more significant effect on the reproducibility of speech intelligibility than the technique used for recording (FoA or HoA microphone).
For the reproducibility of the effect of spatial acoustics, the study has proven that the hypothesis was supported where the H-Spk implementation correctly replicated the effect of spatial release from masking observed in the real rooms. In terms of the effect of speech-noise separation, the study found that the technique used for recording (FoA or HoA microphone) had more significant effect on the results than the technique used for rendering (binaural or 32-ch loudspeaker array), which is opposite to that observed in the reproducibility of speech intelligibility. The study has found the effect of source distance can be reproduced correctly regardless of implementation.
While the current study has some limitations, these findings would provide insights if Ambisonics microphones are applied for the implementation of spatial sound reproduction techniques used for speech and hearing research that focuses on the effect of spatial acoustics in rooms.
Footnotes
Acknowledgements
The authors thank Mr Geoffrey Zhu for his help to conduct the experiment in the real rooms, Mr Dhruv Jagmohan and Mr Hong Kit Li for helping collect the results from Group 3 and Prof Suzanne Purdy for letting us use the SPANZ speech corpus. Also our thanks should go to all the participants who undertook the experiments of this study.

Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This research was partly supported by the Engineering Faculty Research Development Fund.
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.