
Abstract
Keywords
1. Introduction: Screenshots And Social Semiotics
Screenshots, also known as ‘screen captures’ or ‘screen grabs’, are still images that replicate the contents of a computer or mobile device screen. The concept of a screenshot arose in the 1960s as a visual convention which ‘allowed the experience of using an interactive computer to be described and distributed’ before the concept of digital interactivity had been naturalized and people had learnt how to read these kinds of images as meaningful (Allen, 2016: 664). This article considers a more recent development in the meaning potential of screenshots as visual images, exploring their role in social media discourse. It focuses on how screenshots are legitimated as visual evidence and used to propagate certain kinds of social values. By embedding screenshots in social media posts, these images can be recontextualized beyond their original setting for many purposes, such as substantiating online activity, making personal encounters public, or archiving digital events. Even though screenshots can be easily manipulated via image editing software, they are often interpreted as true copies of content (Jaynes, 2020). This has the potential to fuel misinformation and disinformation practices. Misinformation is false information which is
Research into screenshots on social media is a relatively new area of study. Screenshots remain ‘neglected in public debate’ because we tend to ‘look through them’, rather than perceiving screenshots themselves as media objects (Frosh, 2018: 62). However, critical analysis of the meaning-making practices involved in producing and sharing screenshots is important for ‘examining the assumptions embedded in their form and function’ (Moore, 2014: 141). There has been some ethnographic work undertaken on everyday use of screenshots by teenagers which has noted their evidentiary role in ‘reaffirming friendships and resolving or igniting conflict’, subject to ethical codes for sharing, particularly when used in group chats (Jaynes, 2020: 1381).
In terms of research into the manipulation of screenshots, ‘evidence collages’ in media manipulation campaigns have been examined from an ethnographic perspective (Krafft and Donovan, 2020). These collages incorporate screenshots as a form of visual evidence that function as ‘a key strategic element in the formation and spread of disinformation’ (Krafft and Donovan, 2020: 205). Screenshots have also been studied as technologies for public shaming. For example, a qualitative thematic analysis of news media articles about the cases of Amanda Todd, a Canadian teenager who was cyberbullied and blackmailed with screenshots taken of her without her consent leading to her taking her own life, and Anthony Weiner, a US Congressman whose political career ended when screenshots were revealed of his extramarital flirtations, highlighted how screenshots are entangled between the notions of permanence and ephemerality, and the boundary violations that occur when the private is made public (Corry, 2021). Some studies have noted the role of screenshots in the propagation and visibility of racist discourses where ‘platform collapse’ and ‘mediated spillover’ occurs, as screenshots are shared across various social media platforms without users understanding their proper context (Bigman et al., 2022: 4). Whilst there is some positive potential for screenshots to call out social media users who engage in a ‘tweet and delete’ culture of harassment, this needs to be weighed against their potential negative impact in proliferating hateful content, for instance by amplifying racist content (Bigman et al., 2022: 11). On the other hand, screenshots may act as a tool for sousveillance, an effective form of visual persuasion, whereby organizations such as Racism Watchdog draw attention to online injustices (Jenkins and Cramer, 2022).
This issue of how to theorize the social functions of screenshots is also critical to understanding their visual meaning-making potential. Cramer et al. (2022: 6) have developed a four-quadrant conceptual model to understand the function of screenshots as either bookmarking or containing information for an individual’s own use in both the online or offline worlds, or disclosing and reframing information for alternative audiences. The study suggested that screenshots fulfil interpersonal needs and are examples of ‘networked sociality’ (Papacharissi, 2010: 316), in the sense that screenshots easily move across different social media platforms and architectures (Cramer et al., 2022). Švelch (2021) has also drawn attention to the need to develop a critical literacy of screen capture practices. In particular, they distinguish between ‘screen captures’, as any visual record of a screen, ‘photographic screen captures’, as a photographic record of the screen, and ‘screenshots’, as a screen capture that is a digital file created within the same device as the one that displayed the original screen capture (p. 559).
The multimodal approach adopted in the present study is complementary to this existing research into screenshots as it offers a way of understanding the social significance of screenshots by exploring how they make meaning and legitimate values. While studies have identified the motives of users and viewers in sharing screenshots (Jaynes, 2020) and how screenshots have been discussed in news articles (Corry, 2021), there is a lack of multimodal research that considers both their linguistic and visual use in instances of misinformation and disinformation. There is also a lack of work on the affiliative potential of the screenshot in terms of the role it can play in aligning people into shared communities who consider certain kinds of evidence to be legitimate. Instead, social media research has tended to focus on issues of polarization and misinformation (Dunaway, 2021) from media ecology and cognitive bias perspectives. There has been some previous work using legitimation to investigate political fake news (Igwebuike and Chimuanya, 2020) and delegitimation via internet memes (Ross and Rivers, 2017); however, none of this work has focused on screenshots. In order to add to this body of literature on screenshots, the key research questions guiding this study are:
R1: How are screenshots manipulated as legitimation and affiliation strategies in social media discourse?
R2: How can a multimodal semiotic framework be re-orientated to foreground these strategies discovered in social media discourse?
This article begins by detailing the dataset used in the case studies and the sampling strategy employed. The method section then introduces the social semiotic theoretical framework and explains the multimodal discourse approach to analysing screenshots using two frameworks: affiliation (Martin and White, 2005; Zappavigna, 2018), for understanding the social bonds and values at stake in the screenshots and legitimation (Van Leeuwen, 2007), for understanding how these values are positioned as valid, to be valued, or as believable. The results section discusses the importance of
2. Dataset And Sampling Strategy
The present study forms part of a larger project studying misinformation and disinformation in a dataset of 30 videos in terms of both the visual and verbal discourse manifest in the videos and in their respective comment feeds (see Inwood, 2021; Inwood and Zappavigna, 2021; Inwood and Zappavigna, 2022a; Inwood and Zappavigna, 2022b). It was motivated by the high frequency of screenshots observed in the dataset, suggesting that their use was a visual pattern worthy of attention. For a manual analysis, this is considered a large dataset as 1,674 frames were manually analysed according to visual and verbal discourse.
Two case studies of screenshot use in YouTube videos about the 2019 Notre Dame Fire Cathedral and the Momo Challenge Hoax were selected for this study as they represent both political and non-political discourse and both received significant engagement on YouTube. As such, they offered the potential to examine different genres of ‘information disorder’ (Wardle and Derakhshan, 2017): the ‘Notre Dame Fire’ conspiracy is an instance of politically motivated hate speech, whilst the ‘Momo Challenge’ is an example of a mostly apolitical internet hoax related to moral panic about children and technology. The Notre Dame Fire videos in the dataset represent a range of conspiracies about the fire, including white supremacist discourse falsely implicating Muslims and immigrants. The Momo Challenge videos are about an internet hoax regarding a threatening figure contacting children on WhatsApp or being spliced into YouTube Kids videos.
The data collection and sampling procedure for this study involved several steps. A theoretical sampling approach was used to collect the YouTube videos, using YouTube Data Tools (Rieder, 2015). These videos were selected on the basis that they were in English, had more than 10,000 views, had comments enabled and, for the Notre Dame Fire videos, were created in the 24-hour period after the Notre Dame Fire. This resulted in a dataset of 272 Notre Dame Fire and 195 Momo Challenge videos. From this set, 15 videos were then selected for each case study. For the Notre Dame Fire, this was on the basis that they were under 15 minutes (as some videos were livestreams that lasted several hours), featured conspiratorial or false content about the fire and had the highest number of views. Conspiratorial or false content was defined as content that stated the fire was deliberately created, in contrast to the official statement by French prosecutors that determined the fire was an electrical accident. For the Momo Challenge, the videos were selected to represent the various macro-genres observed across the dataset: news reporting, entertainment, commentary, education and clickbait. The transcripts and visual content (a frame representing each second of video) were collected for each video.
3. Method
This study adopts a multimodal social semiotic approach interested in how language and other modes of communication make meaning when used in social contexts (Halliday, 1978). The analytical method integrates two social semiotic frameworks: affiliation (developed within Systemic Functional Linguistics) and legitimation. The affiliation framework is used to understand the key social bonds enacted through the use of screenshots together with the spoken verbal text of the YouTubers. It considers the values that the YouTuber projects onto the screenshots in order to forge alignment with the ambient audience of the video. The legitimation framework is used to understand how these bonds are legitimated. This involves exploring how credibility is verbally and visually constructed in the videos. The following subsections will explain the affiliation and legitimation analysis undertaken in the study.
3.1 Affiliation and social bonding analysis
According to the SFL affiliation framework, social bonds are realized in discourse as values, instantiated as evaluations targeted at entities, phenomena and activities (Martin and White, 2005; Zappavigna, 2018.). The present study draws on the Appraisal framework (Martin and White, 2005), a discourse semantic framework for analysing evaluative language, to systematically analyse the evaluative language used in the video transcripts. The focus was on the attitude system which describes three main regions of meaning: affect (feelings and reactions to behaviour), judgement (ethically assessing a person or behaviour) and appreciation (valuing an object or phenomenon). The affiliation analysis involved exploring the construction of ideation–attitude ‘couplings’ in the dataset. These are theorized in the framework as the discursive realization of the social ‘bonds’ (Knight, 2013) that align personae into communities of values (Zappavigna, 2018). Ideation-attitude couplings are represented throughout this article in square brackets, using the following annotation strategy with the ideation underlined (what is being evaluated) and the attitude (how it is being evaluated) presented in bold font: This [ideation: video/ attitude: negative
Technical appraisal terms are displayed in
The resource of visual salience was important in order to understand the relation of the visual elements in the screenshots with the social bonds realized by the values identified in the transcripts. From a multimodal perspective, visual salience refers to the elements in an image/video that are depicted as the worthiest of attention, formed, according to Kress and Van Leeuwen (2006: 202), through one or more of the following dimensions:
–
–
–
–
–
–
–
–
–
In this study, visual salience is adapted to the affiliation framework in order to understand how YouTubers situate themselves in relation to screenshots via implicit membership categorizations (shared understandings of particular social media platforms) or if they distance themselves from the screenshot (a focus on subjectivization). As we will see, many of the salient visual elements observed in the video frames can be interpreted as ‘bonding icons’, that is, symbols that embody particular values which people rally around (Stenglin, 2008; Tann, 2012; Zappavigna, 2014a; Zappavigna, 2014b). These dimensions of visual salience and affiliation will be unpacked further in the Results section.
3.2 Legitimation analysis
Legitimation refers to how discourses establish authority and credibility through ‘specific linguistic resources and configurations of linguistic resources’ (Van Leeuwen, 2007: 92) and via particular multimodal resources (Van Leeuwen, 2008). In this article, we consider both legitimation and de-legitimation as construed in language and images, drawing on the work of Van Leeuwen (2008). Broadly, (de)legitimation in Van Leeuwen’s original framework can be divided into four categories with further sub-categories:
Moral Evaluation: Legitimation of value systems via evaluation, abstraction, or comparison.
Rationalization: Legitimation via institutionalized social action or the knowledge society has constructed, in terms of theoretical legitimation (how knowledge is constructed in terms of the experiential, scientific, definition, explanation or prediction) or instrumental legitimation (focusing on institutionalized social action via the means, goals or effects of actions).
Mythopoesis: Legitimation conveyed through narratives and future projections. For example, via moral tales, cautionary tales, single determinations (that represent stories in a straightforward way) or overdeterminations (that represent stories via inversion or symbolisation).
A theoretical contribution of this article is in extending the legitimation framework via the
– Laws, Rules and Regulations: This sub-category incorporates the original definition of impersonal authority by Van Leeuwen (2007), that is how references to laws, rules and regulations construct authority.
– Technological authority: Credibility established via technological means, e.g. screenshots, online articles and references to video links or Google searches.
– Traditional Media: Legitimation formed by referring to newspapers and television as evidence.
– Technologies: Legitimation formed by referring to technologies (in the case of this study the only technologies referred to were aircraft, e.g. drones and UFOs). This can be expanded and refined in future studies to encompass new technologies.
These refinements to the legitimation framework are shown in Figure 1. It should be noted that these refinements were created in relation to the dataset for this study through an inductive methodology.

Authorization sub-system of the legitimation framework (adapted from Van Leeuwen, 2007).
3.2 Coding strategy
The affiliation and legitimation analyses for this study are presented according to conventions shown in Figure 2. The video frame is presented at the top of the diagram, with the salient elements in the frame annotated with a red rectangle (which will be further explained in the analysis sections). Salient visual semiosis contributing to the realization of social bonds is shown via circular callouts, with corresponding visual legitimation strategies identified underneath the frame. A downward arrow symbol is used to indicate instantiated features. The transcript text (the YouTuber’s verbal text when the screenshot appears) is presented in a speech bubble. Underneath the transcript are the key bonds realized by the ideation-attitude couplings in the transcript (ideation

Convention for presenting the multimodal analysis of affiliation and legitimation.
4. Results
The results of this study will be discussed according to the key types of screenshots and screen recordings that emerged from this qualitative research. Across the 30 videos, every example of a screenshot mentioned either verbally or visually was firstly identified. These were then categorized according to their verbal or visual attributes, and also taking into consideration the broader context of each screenshot and its interaction with other elements in the video. A summary of the types of screenshots, categorizations and frequencies across both case studies is shown in Tables 1 and 2. As these tables suggest, the most frequent screenshot visual structure was use of the split screen, followed by unaltered and emulated screenshots. The sections which follow explore each of the screenshot structures and types in terms of their key legitimation and affiliation patterns, with quotes also provided in verbatim.
Frequencies and categorizations of screenshots in datasets.

Frequencies of verbal references to screenshots in datasets.

4.1 Unaltered screenshots of online and traditional media
The most common forms of

Screenshots of social media posts from the Notre Dame Fire dataset.
The dynamism of the scrolling video also contributes to
In the Momo Challenge dataset, screenshots of social media posts also served a legitimation function, drawing on

Screenshots of social media posts from the Momo Challenge dataset.
In terms of the source of information, screenshots of online articles were also employed in the dataset as evidence to support deceptive and conspiratorial claims. Typically, these screenshots were cropped in order to focus upon the particular headline of the article, often editing the screenshots so that several could be shown at once, mimicking the material characteristics of newspaper cut-outs. This type of editing forms social bonding around an interest in forensic media production and consumption. For instance, the Notre Dame Fire dataset included a video featuring an article from the

Online articles from the Notre Dame Fire dataset.
In the Momo Challenge case study, screenshots of online articles are used as evidence for the claim that the Challenge has resulted in the death of children. These articles are often from local media or non-mainstream media outlets or are cropped in such a way as to only highlight the title without further context. In Figure 6, Momo is again the salient image drawing the viewer’s attention. The voice-over realizes a ‘Dangerous Momo bond’ by negatively

Online articles from the Momo Challenge dataset.
4.2. Enacting technological authority with split screen videos
Screenshots were frequently incorporated into split screen videos, adding additional layers of
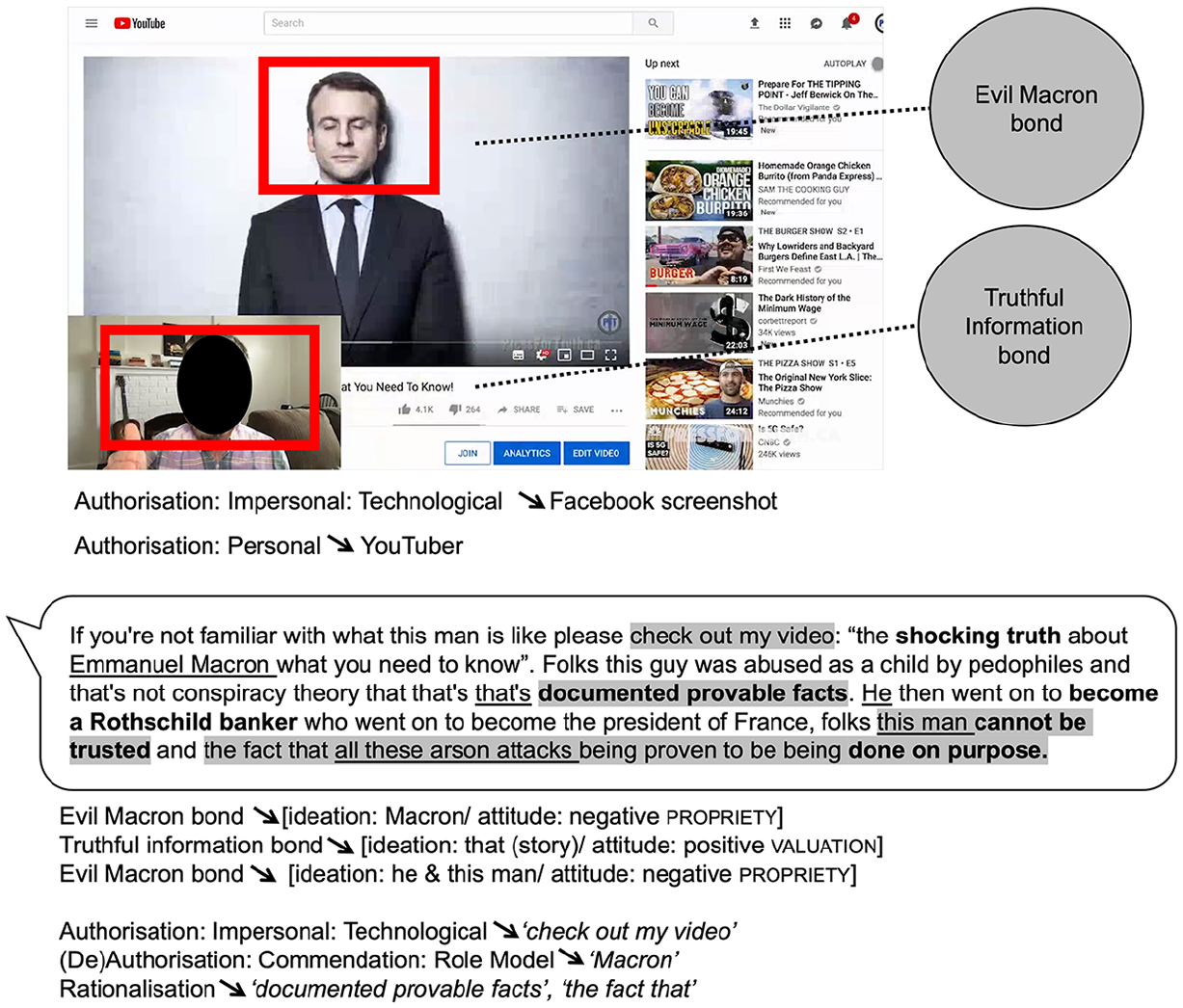
Split screen video from the Notre Dame Fire dataset.
The screenshot functions to emphasize two key bonds construed by the linguistic couplings shown in Figure 7: an ‘Evil Macron bond’, realized in the heading ‘The Shocking Truth about Macron’, and a ‘Truthful Information bond’, realized by the title of the YouTube video
Split screen screenshots had a similar legitimating function in the Momo Challenge dataset. This dataset also contained examples of an inverse split screen structure, with the YouTuber in the dominant visual position and the screenshot of a supposed interaction with Momo in the top right corner (Figure 8). Whilst the YouTuber and their reaction to the content in the screenshot takes prominence, the screenshot remains a bonding icon promoting a ‘Truthful Information bond’. In the voice-over, Momo is the target of negative

Split screen video from the Momo Challenge dataset.
4.3 Screenshots as evidence collages
Across both datasets, there were examples of ‘evidence collages’, that is, ‘image files that aggregate positive evidence’ employed as direct proof of an issue/fact (in contrast with circumstantial proof which refers to evidence not drawn from direct observation) (Krafft and Donovan, 2020: 205). These collages incorporated collections of multiple screenshots displayed simultaneously on the screen. In the Notre Dame Fire dataset, evidence collages typically consisted of multiple visually adjacent tweets used to suggest that multiple sources had provided the same evidence. For example, in Figure 9, the two adjacent tweets both state that churches have been attacked and include images of damaged churches. These images function as bonding icons, evoking negative interpersonal meanings about the destruction of French culture, contributing to a ‘Destroyed Western History bond’ because the Notre Dame Cathedral and churches in France have been co-opted by far-right YouTubers as a symbol of Western cultural superiority. The reference to ‘multicultural France’ links this to anti-immigration stances. The inclusion of multiple screenshots as sources is also a legitimation strategy. The voiceover’s reference to ‘links’ also contributes to a ‘Truthful Information bond’ via

Evidence collage from the Notre Dame Fire dataset.
In the Momo Challenge dataset, mobile phone screenshots in particular, were used as evidence that the YouTuber had engaged with Momo. For example, in Figure 10 three screenshots of Momo (two of calls and one of an exchange of messages with Momo) are presented side-by-side, documenting people’s supposed interactions with Momo. Again, the succession of images creates a stronger sense of

Evidence collage from the Momo Challenge dataset.
4.4 Emulated screenshots
Emulated screenshots encompass screenshots that were not actually taken by someone but are instead imitations of screenshots that have been heavily edited or created entirely from scratch. These functioned to provide

Emulated screenshot 1 from the Momo Challenge dataset.

Emulated screenshot 2 from the Momo Challenge dataset.
The video voice-overs provide further insight into the kinds of meanings being made with these emulated screenshots. The Momo challenge is negatively evaluated, realizing an ‘Evil Momo challenge bond’ (Figure 11). This matches the visual content with the salient image of Momo signalling danger. The reference to leaving behind a ‘video on her phone’ also aligns with the emulated screenshot trying to recreate, as a form of
In the second example, the voice-over negatively evaluates parents for not watching over their children, tabling a ‘Careless Parents bond’ (Figure 12). The Momo Challenge is also negatively evaluated for being associated with the child’s death, contributing to an ‘Evil Momo bond’. The claim by the voiceover that the parents ‘read text messages from his classmates exchanging suicidal thoughts’ again presents the semiotic entity ‘text messages’ as a legitimate source via the legitimation strategy of
4.5 Annotated screenshots
There were examples where screenshots and screen recordings were edited by the YouTuber in the Notre Dame Fire dataset in order to cast doubt on the recordings and help align the footage with the conspiracy theory that the YouTuber was attempting to promulgate. In one example from the Notre Dame dataset, the videos consist of recorded footage from a CBSN live stream that has been annotated by the YouTuber (Figure 13). These annotations consisted of hand-drawn red arrows pointing to the Cathedral, with commentary questioning visual features of the image (e.g. ‘One fireman with one hose?’) and casting doubt on the reporting. The live stream is also used as

Annotated screenshot from the Notre Dame Fire dataset.
4.6 Absence of visual screenshots
Across the entire dataset, three out of the 30 videos did not feature visual screenshots but invoked the presence of screens in the linguistic verbal text. These three videos are from the Notre Dame Fire dataset and instead employed the vlog macrogenre (i.e. a YouTuber directly speaking to the camera). The YouTuber refers to content present on a screen (an article discussing churches being destroyed across all of France) as a form of

Absence of visual screenshots: Example 1 from the Notre Dame Fire dataset.
In another video employing
5. Discussion And Conclusion
YouTube videos can spread conspiratorial and hateful content in sophisticated ways, and screenshots contribute to the believability and virality of misinformation and disinformation. This study has demonstrated how a social semiotic approach can illuminate the affiliative and legitimation function of screenshots in deceptive YouTube videos. The addition of
As part of the inductively developed methodological approach of this research, six different ways screenshots can be visually structured have been conceptualized: evidence collages, split screens, emulated or annotated screenshots, and unaltered screenshots. Screenshots can also be referenced in the linguistic verbal text. These different options can all function to legitimate certain social bonds via
Overall, the empirical findings from the two case studies revealed intriguing insights about how legitimation strategies work both visually and linguistically. With the Momo Challenge dataset, there was a focus on news stories and experts, using other YouTube videos and social media content as evidence for making claims about the Momo Challenge, and spreading moral panics about the Momo Challenge by providing warnings to parents and criticizing YouTube. While incorporating expert opinion and using evidence to back-up claims is considered good journalistic practice, the videos analysed often incorporated these practices deceptively, e.g. manipulating content to make it appear as a trusted source. With the Notre Dame Fire dataset, the analysis of the transcripts and visual content revealed how affiliation and legitimation strategies work in tandem through social bonding and shared ideational targets in verbiage and visual content. The social bonds adopted by the YouTuber were used to legitimize or delegitimize people and ideas. Across this particular dataset,
In terms of future research, the issues raised in this article might be expanded to consider different digital artefacts and different case studies across the broad spectrum of false information, ranging from misinformation to disinformation. This research could also be complemented with further studies that interview users who engage with screenshots and question their motives for creating and sharing screenshots, particularly in breaking news contexts. Jaynes (2020) provides an example of how interviewing teenagers who engage with screenshots reveals rich findings. These insights could reveal further details about how social bonding occurs in relation to screenshots and the changing cultural meanings of screenshots across time. Whilst this current study has remained explorative in terms of focusing on new methodological insights, rather than providing frequency information regarding the affiliation and legitimation strategies explored across large datasets, future studies might attempt to quantify these patterns across visual and verbal modes and consider the extent to which the visual and the verbal meanings coordinate with each other.