
Abstract
Introduction
Moving toward a data-driven society triggers new demands for data analysis. Although we have evolved in our data analysis capabilities, data preparation is still a challenging part of this process. This activity is frequently mentioned as laborious and time-consuming.1–8 According to Dasu and Johnson 9 (p. IX), “the tasks of exploratory data mining and data cleaning constitute 80% of the effort that determines 80% of the value of the ultimate data mining results.”
We can observe variations in which tasks are considered part of the data preparation and how they are indicated in a data analysis process. 8 However, in general, data preparation is the process “to transform the raw input data into an appropriate format for subsequent analysis” (Tan et al., 2 p.3). As part of this process, several different strategies, methods, and techniques are used for data understanding, for example, similarity and dissimilarity between data objects, and for data transformations, for example, aggregations and normalization or standardization of variables. This set of activities is identified in this work as preprocessing, but this term is also referenced in the literature as data wrangling, 3 data cleaning, or scrubbing. 10
Data quality problems are present in most datasets, due to misspellings during data entry, missing information, or other invalid data. Moreover, when multiple data sources need to be integrated, the need for preprocessing increases. 10 Although automated processes are fundamental and accessible in this context, the data analyst’s participation in the decision of how this data should be transformed is still critical in many cases.1,4,6,11,12 To support the cases when the “human in the loop” is vital to data preprocessing, the use of visualization techniques can play an essential role in data analysis while providing meaningful insights4,13,14 since one of the strengths of visualization is enabling users to quickly identify erroneous data. 15
Nevertheless, most of the works in the scope of visualization are focused on supporting just the last phases of the data analysis process. Even though we can find studies proposing visualization methods to assist with preprocessing, they are predominantly focused on data transformation activities, for example, Kandel et al.,3,16 or limited to particular scenarios or data types, for example, time series data Bernard et al. 17 and Gschwandtner et al. 18 Thus, we can still observe opportunities, such as (a) alternative visualizations to explore data quality issues; (b) visualizations to support the evaluation of the preprocessing impacts in further phases; and (c) creating a list of guidelines to support novel visualizations in the context of preprocessing.
Additionally, for many Visual Analytics (VA) processes, such as in Keim et al. 19 and Sacha et al., 20 the preprocessing phase is not acknowledged as important as Data, Visualization, Models, or Knowledge phases. Furthermore, the preprocessing is described as part of a batch or waterfall approach inside one of the existing phases, and its activities, when detailed, are basically with regards to data transformation. However, as discussed by Krishnan et al. 6 and Milani et al., 8 preprocessing activities should be considered part of the entire process, not only because these activities require multiple interactions through the whole data analysis process but also due to their impact on the other phases.
This paper aims to raise awareness of these issues seeking to answer the research question:
A list of nine guidelines to be considered by VA solutions to incorporate preprocessing in the analysis life-cycle, presenting different examples found in the literature;
A conceptual process, named
Further research opportunities in the scope of preprocessing, visualization, and VA for advancing the area.
We use the term
The structure of this paper follows the order of steps taken in the development of this work. First, in the
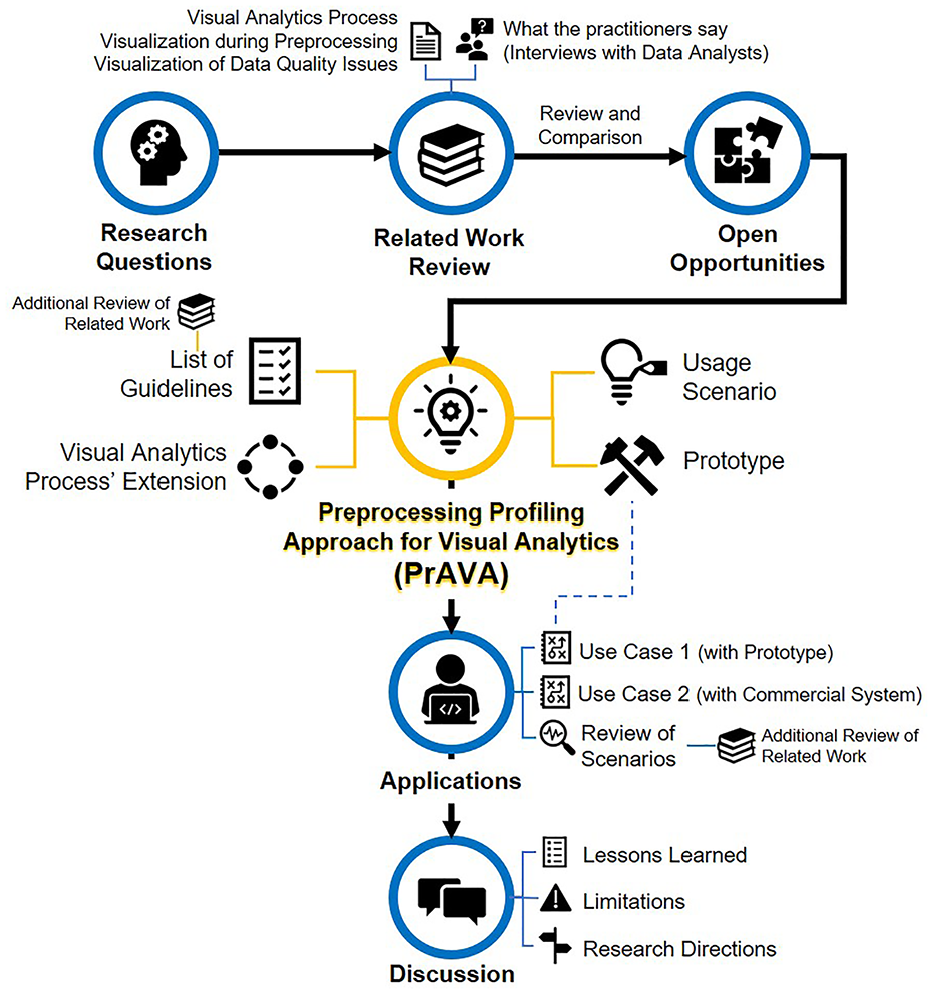
Overview of this work.
Related work
This section covers related work that serve as background and, at the same time, influenced the Preprocessing Profiling Approach for Visual Analytics (PrAVA). These works are grouped in four subsections according to their focus on Visual Analytics process, visualization during preprocessing, visualization of data quality issues, or interviews with practitioners. Finally, we present a review and comparison of the selected related work.
Visual analytics process
As part of the Visual Analytics (VA) discussion, Keim et al. 19 contribute with an overview of the different phases in the VA process. Their process (Figure 2) combines automatic and visual analysis methods with human interaction to gain insights and promote knowledge generation. Despite their notorious relevance to the VA area, their process does not detail the importance of the preprocessing activities. Also, the representation of their process such as a waterfall flow does not allow interactions related to data preprocessing.

The Visual Analytics process based on Keim et al. 19 . Each node (colored rectangle) corresponds to a different phase, and their transitions are represented through arrows.
As an extension of Keim et al., 19 Sacha et al. 20 presents a new model for Knowledge Generation (Figure 3) that includes a high-level description of the human work process in the visual analytics integrating this model with different frameworks. Next, other works emerged inspired by these previous works, such as Ribarsky and Fisher 22 addressing the human-machine interaction loop complementary to Sacha et al. 20 and Federico, Wagner et al. 23 explaining the role of explicit knowledge in the analytical reasoning process when proposing a conceptual model for knowledge-assisted visualizations. These three references share the focus on the “Human” side, that is, cognitive science and knowledge generation aspects. Thus, despite Sacha et al. 20 also being one of the works that most describes the “Computer” side, the discussion about the data profiling and preprocessing challenges are still existent.
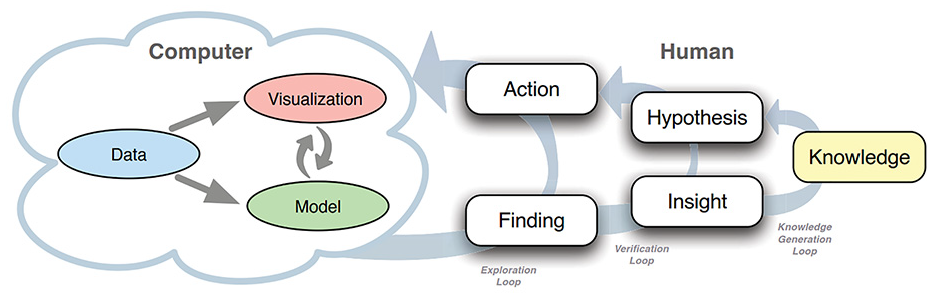
The knowledge generation model for VA proposed by Sacha et al. 20
Although limited to a subarea of VA, we can identify studies that contribute toward our discussion by showing preprocessing activities as part of their VA process description. For instance, Lu et al. 15 and Lu et al. 24 while introducing the Predictive Visual Analytics pipeline, and Sacha et al. 7 during their proposal of an ontology for VA assisted Machine Learning.
Visualization during preprocessing
In the existing literature, we observed few visualization studies concerned with data preparation activities. Also, the use of VA for the preprocessing phase is least reported in general. The same observations are also reported by other authors, for example, Kandel et al., 4 Sacha et al., 7 Seipp et al., 25 Lu et al., 15 Bernard et al., 17 and Lu et al. 24
Some studies in the context of VA and preprocessing can be found, for example, Bernard et al. 17 and Gschwandtner et al., 18 but they are focusing in time series data and do not provide a comprehensive discussion for preprocessing with different types of data. Likewise, we can find studies explaining how they are handling preprocessing during a VA process, for example, Krause et al. 26 and Sacha et al. 27 However, these studies are still not entirely dedicated to cover preprocessing problems. Nevertheless, their observation of how shifting the attention from visual analysis to visual preprocessing can improve the analytical processes contributes to our discussion’s relevance.
In this context, few relevant works can be cited with a broader coverage in visualization in preprocessing. One of them is the Predictive Interaction framework for interactive systems, developed by Heer et al., 28 that covers general design considerations for data transformations. As the main discussion, the authors propose that the data analyst can decide the next steps of data transformation by highlighting guidelines of interest in visualizations, instead of specifying details of their data transformations. With that, they expect to avoid a variety of data-centric problems related to the technical challenges of data analysts during programming. Similarly, Wrangler 3 is introduced as a system for interactive data transformations, which includes an interface language to support data transformation with a mixed interface of suggestions and user interaction on visual resources. Both papers provide primordial techniques in the scope of preprocessing, but they are limited to the data transformation activities.
Regarding visual data profiling, von Zernichow and Roman 29 propose an approach to use visual data profiling in tabular data cleaning and transformation processes to improve data quality. As part of their study, they also evaluate the usability of their implemented software prototype, which brings considerations under the usability issues and suggestions for further research, such as exploring visual recommender systems.
One of the most comprehensive proposals about preprocessing is Profiler, 16 an integrated statistical analysis, and visualization tool for assessing data quality issues. Profiler uses data mining methods to support anomaly detection. However, there is still the opportunity to explore different ways to view frequent data issues, for example, missing values in a dense-pixel display.
Visualization of data quality issues
There is comprehensive literature available on how to diagnose and handle data errors, for example, Kim et al, 1 Wickham, 5 Rahm and Do, 10 Chandola et al., 30 and Wang et al. 31 Among the different types of data quality issues, the missing data are one of the most frequently referenced.4,6,8
Templ et al. 32 criticize that no matter how well the classification mechanism for missing data has been planned, they still have limitations such as the difficulty to accurately identify the cause of the value being missing while working with multivariate data. Subsequently, they argue for the importance of visualization to solve the related questions, and they introduce Visualization and Imputation of Missing Values (VIM). In an empirical study to evaluate the best design for interpretation of graphs with missing data, Eaton et al. 33 observe that data interpretation is negatively impacted when there is a poor indication of the missing values. Additionally, more recent studies such as Sjöbergh and Tanaka 34 and Song and Szafir 35 endorse the importance of developing different ways of visualizing missing values as an attempt to avoid misleading interpretations resulting from the way the visualization procedure was developed. Similarly, McNutt et al. 36 claim that dirty data or bad user choices can cause errors in all stages of the VA process, and a superficial visualization without a closer re-examination can lead to misleading or unwarranted conclusions from data (what they call visualization mirage).
What the practitioners say
In addition to the research related to visualization techniques and the VA process, it is also important to understand the current practice of enterprise professionals with data preprocessing and how visualization supports this process. However, few works can be found sharing the experiences of the practitioners in the scope of data analysis and visualization, for example, Batch and Elmqvist, 37 Kandogan et al., 12 Kandel et al., 38 and Milani et al. 8 At the same time, other interview studies are focusing on interactive data cleaning, such as Krishnan et al. 6 When combined, these works bring light on practitioners’ reality on different perspectives, supporting a broader view of the practice and the current needs.
In the most recent of these works, Milani et al., 8 we interviewed thirteen enterprise data analysts and compiled a list of 10 insights for new visualizations in preprocessing scope. We compared our findings to the other interview studies to compile the final list, which brings confidence that this list of insights can be used as a consolidated set of requirements based on what the practitioners report. Moreover, these insights improved the reliability of our findings and provided background, helping in the definition of the guidelines presented in the next section.
Review and comparison
To better organize our discussion on the related work and to facilitate the comparison with the scope of our work, we defined six items to guide this effort. The results are summarized in Table 1, and further comments for each item are provided. We did not add all related work to the table, but only those we considered closer or more relevant to our discussion.
Is the work presenting details on the following items?

Regarding
Next,
Complementing the previous,
While evaluating
Multiple works3,8,16,29,32–36 cover the content of
In conclusion, besides the relevant contributions of these works, we can still observe opportunities to be discussed. From that, the following items receive less attention than the others:
Preprocessing as an equally important phase in the VA process.
Alternative visualizations to cover the same data quality issue by different perspectives.
Visualizations to support the evaluation of the preprocessing impacts in further phases.
List of guidelines to support novel visualizations in the context of preprocessing in a data analysis process.
To continue this discussion and support filling these gaps, we are proposing the Preprocessing Profiling Approach for Visual Analytics, which is described in the next sections.
Preprocessing profiling approach
In this section, we present the Preprocessing Profiling Approach for Visual Analytics (PrAVA), illustrated in Figure 4. First, we outline the nine guidelines that we identified as important to be observed while planning new solutions in compliance with our proposed approach and considering preprocessing an equally important phase in the VA workflow. Second, we explain the PrAVA process and its relation to the guidelines.

The Preprocessing Profiling Approach for Visual Analytics (PrAVA) is an extension of the VA process proposed by Keim et al. 19 . We added the Preprocessing Profiling phase and new transition options: Dataset Understanding, Data Preparation Understanding, Visualization of Preprocessing, Model Testing, and another Feedback Loop. The new objects are represented in blue color for the text font and dashed lines.
Guidelines
We identify nine guidelines for consolidating preprocessing in the VA process, composing the foundation for the proposed PrAVA extension. These guidelines were identified based on the current relevant literature (
List of nine guidelines to be considered as part of the Preprocessing Profiling Approach for Visual Analytics (PrAVA). For each guideline, we describe their meaning, motivation, and some examples of implementations in the context of VA or Visualization.

We also indicate additional work or software solutions that we consider related to each guideline. In other words, that can illustrate its possible implementations. It is pertinent to note that some of the suggested references may cover more than one guideline, or they may not fully cover even one guideline. Moreover, some of them do not have the preprocessing as an ultimate purpose. However, in their presentation, we can observe how they use the VA or Visualization during preprocessing tasks.
The structured list of guidelines aims to guide the design of new solutions in adherence to the PrAVA. At the same time, the insights gained during the examination of these guidelines supported us in devising the PrAVA process, which is explained in the next subsection.
Process
PrAVA is formalized as an extension of the VA process (see Figure 2), in which we include a new phase called Preprocessing Profiling, and new possible transitions among the phases. An overview of the PrAVA process is shown in Figure 4. Even though we recognize the importance of human cognitive activities in the VA process (see Figure 3), we decided to continue using Keim et al. 19 representation aiming for simplicity to illustrate the VA process; therefore, this decision allowed us to focus on the Preprocessing Profiling transitions.
By adding Preprocessing Profiling as a phase, we put activities such as the data profiling and the evaluation of preprocessing strategies before Model Building in the critical path, that is, as an equally important phase. However, preprocessing activities planned in the original Data phase as part of the Transformation transition (Data ↔ Data) can still occur since, for example, the dataset input may require data cleaning and normalization before proceeding with any analysis. Also, the other four original phases and their transitions remain the same. Next, we focus on explaining only the new transitions. Furthermore, we are indicating how the guidelines presented in Table 2 can be associated with this process.
The new transition
Another new transition is
All the transitions leaving the Preprocessing Profiling phase have a way back on the same connection (i.e. the arrows in Figure 4). Different from the original VA process (see Figure 2), which can be read as one-way direction, such as a waterfall approach, PrAVA considers the possibility of multiple interactions between two phases during the same process. Thus, we also added a new
However, the model proposed by Sacha et al.
20
(see Figure 3) better describes the different loops in this scope of knowledge generation and should be used as a reference for the subject. In summary, they define three different usage loops: (1) the exploratory loop, where finds are discovered; (2) the verification loop, where insights are generated by interpreting the findings; and finally (3) the knowledge generation loop, where insights are converted into verified hypotheses and data is transformed into knowledge. Our proposed
Big Data scenarios are the concern behind
In reference to
The VA process described in PrAVA includes cases in which data adjustments are identified in several phases of the data analysis process. These are not limited to the first time data are selected and transformed. We also advocate the advantage of using visualization techniques during the preprocessing, and not only to generate the final visualizations. Ultimately, our proposal with PrAVA considers the Preprocessing Profiling as a prominent phase, which deserves to have its transitions explicitly extended in the VA process.
Among our rationale for this novel approach, we can indicate a couple of reasons. First, even though Keim et al.
19
covered Data activities, as previously explained, it was not covering all the preprocessing activities as we are proposing in this work. We also do not consider Preprocessing Profiling a sub-phase of Data because we understand that the complexity related to data preparation has evolved over the years. These processes have been overlooked by the visualization research community as reported in our
Usage scenario
In this section we present a usage scenario with PrAVA. We implemented a prototype solution, first, to assist with this usage scenario, and later, with other possible applications of PrAVA. This solution is described in Subsection
Prototype
Since our primary goal is to describe a conceptual VA process (PrAVA), and not a system, we introduce in this subsection just the information that we consider relevant to the prototype’s overall understanding as it is referenced in the next subsections. The developed prototype solution generates two dynamic reports:
The
The
As a final observation, the developed prototype is functional, but it cannot be considered an end-to-end VA System. Additionally, not all the guidelines were implemented.
Tim and the Iris dataset
In this hypothetical usage scenario, we present a persona named Tim, a biology student. In Figure 5, we illustrate the pathways performed by Tim during his activities.

Usage scenario – The pathways took by Tim:
Tim is searching for strategies on how to solve the taxonomic problems of his current research. He has collected data about a group of Iris flowers, and he is interested in identifying the Iris species by the attributes measured from a morphological variation of the flowers. Tim’s dataset contains 186 samples (36 more than the original Iris dataset) 62 from three different species of Iris, namely, Iris Setosa, Iris Virginica, and Iris Versicolor. For each sample, four attributes were measured in centimeters: sepal_length, petal_length, sepal_width, and petal_width. Additionally, a fifth attribute informs the corresponding class of each sample. However, Tim was not able to get all the data for the new samples; as a result, his dataset has data quality problems, that is, the dataset contains outliers and missing values.
Tim is familiar with the Python programming development environment. To begin, he tries to run a classification model using his dataset without any data transformation. However, he could not move forward since an error message is returned informing him the classification algorithm cannot proceed due to missing values in the dataset. This attempt is shown in Figure 5 as
Dataset profiling
Tim starts by running descriptive statistics using Python. However, many lines of code and outputs with plain text would be required to generate all the information he wants. Consequently, he decides to use PrAVA’s prototype integrated into his development environment to create the first report for his analysis. With
Tim decides to explore each variable of his dataset (still part of Figure 5–
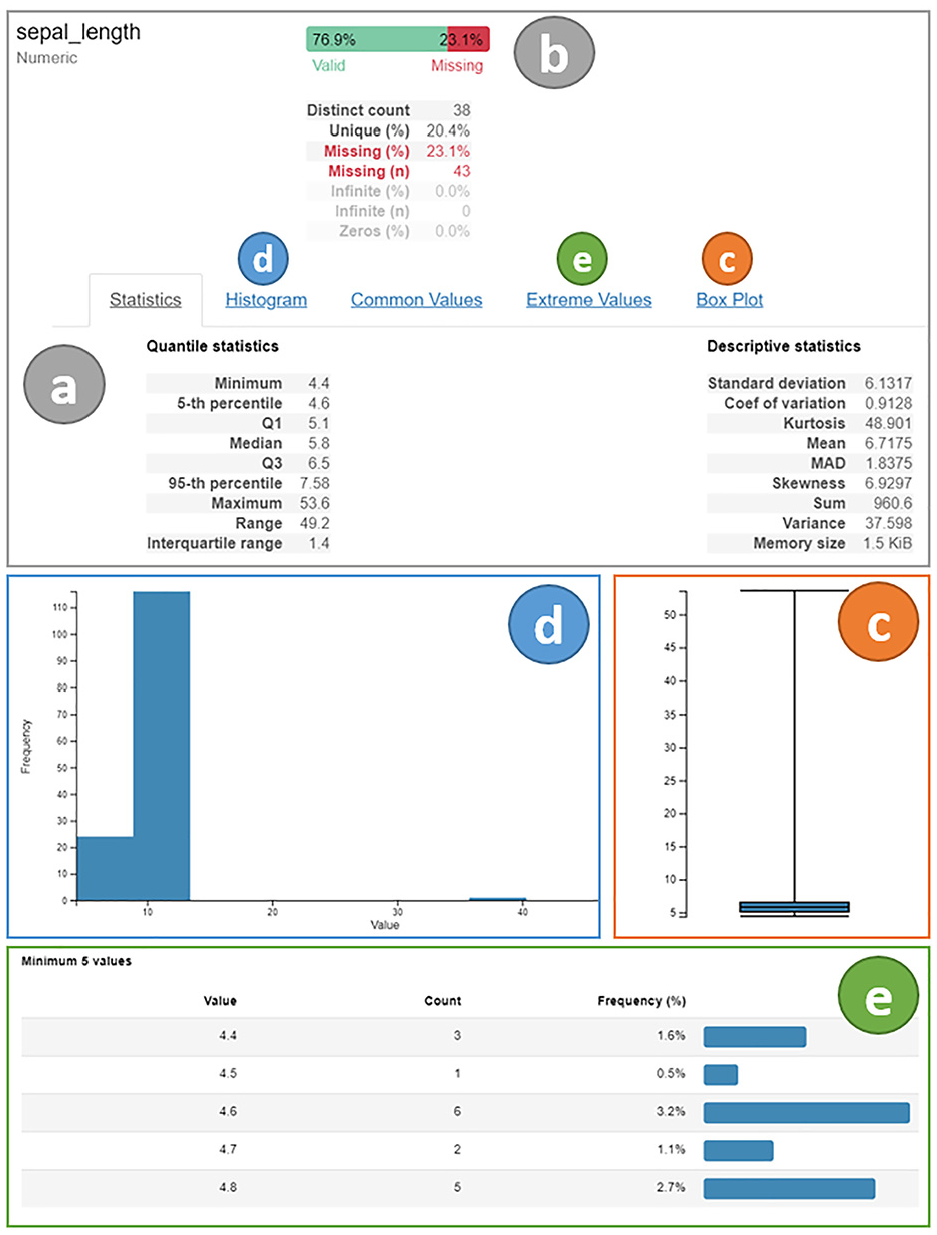
Preprocessing profiling
Tim moves to the analysis of the impacts of the preprocessing strategies on his classification problem after the completion of his activities in understanding the data. Tim informs his dataset as input to the
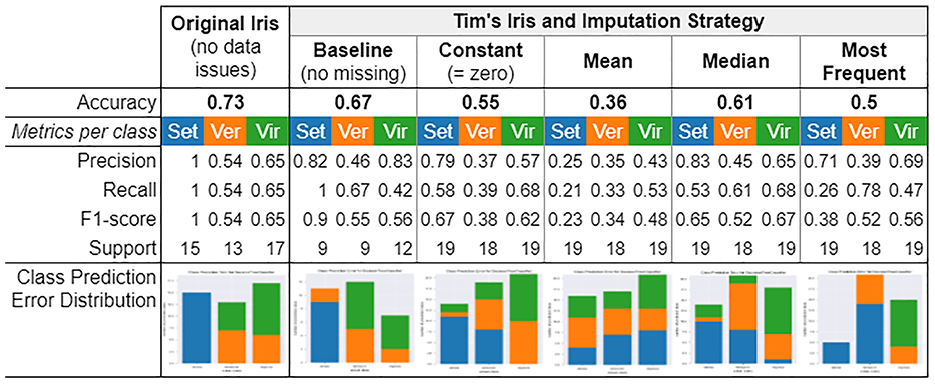
Classification results for one round of testing using the attributes sepal_length and sepal_width and different preprocessing strategies. First column refers to Original Iris dataset (without data issues). From second to sixth column refer to Tim’s Iris dataset and the corresponding imputation strategies performed. The classes are identified as “Set” in blue for Iris Setosa, as “Ver” in orange for Iris Versicolor, and “Vir” in green for Iris Virginica. In the last row, the Barplots also follow this order (Set,Ver,Vir).
Although the classification results varied in each round, Tim is still able to notice differences among the imputation strategies for all rounds performed. For example, the class of Iris Setosa was initially clear to classify (Figure 7, first column, class in blue). However, with the presence of data issues and the need to perform imputation strategies, the classification results are negatively impacted. Tim also observes a significant variation on the accuracy metric for the
Furthermore, while comparing the
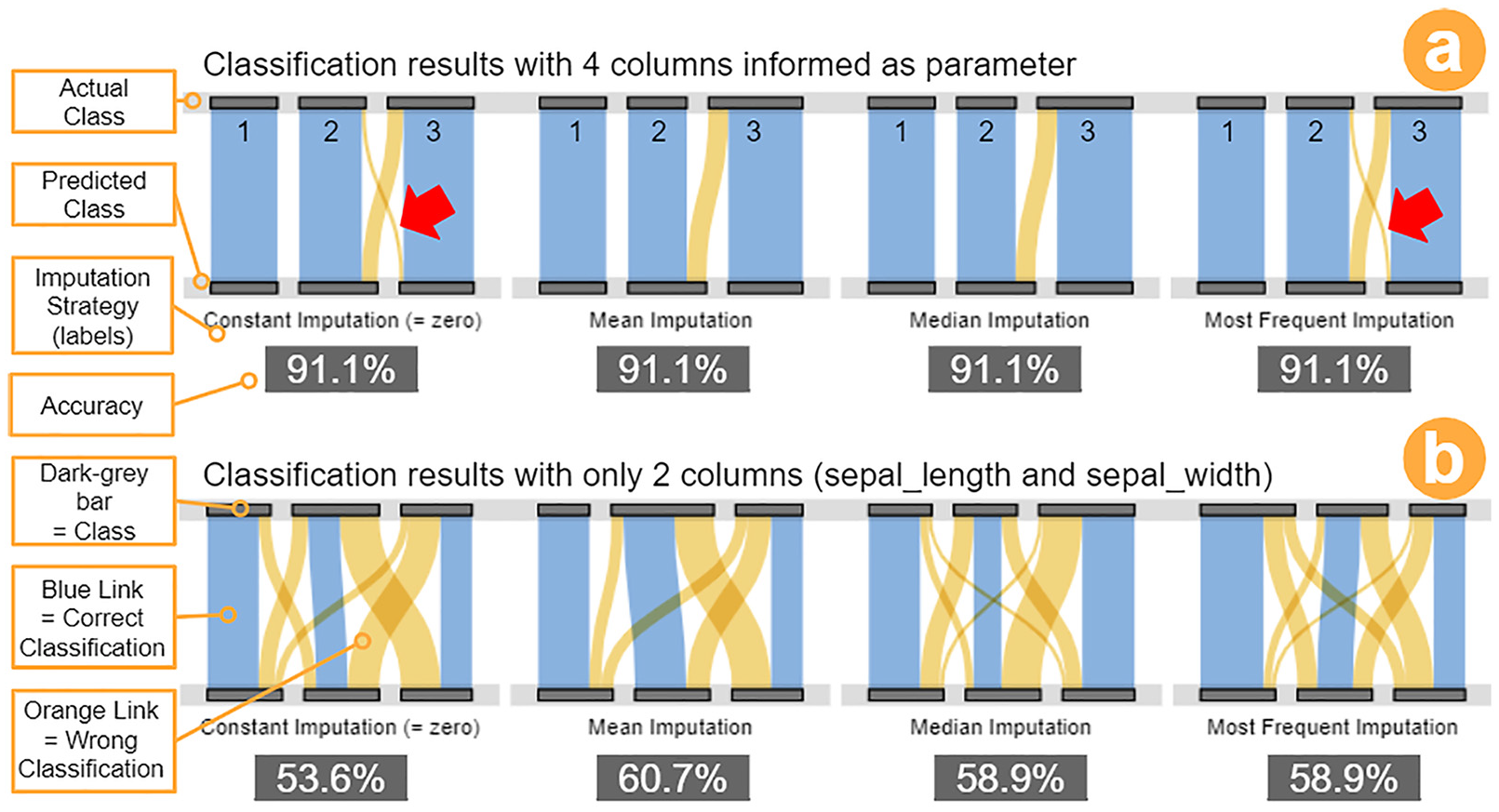
Preprocessing profiling report. Classification results for different missing values imputation strategies: (a) four columns informed into the classification model, and (b) only the two columns related to Sepal attribute were informed. The visualization Flow of Classes is used in both representations (inspired by Sankey diagrams).
Under these circumstances, he considers it essential to have different views for the same classification results, mainly when using a dataset with data quality issues. In conclusion, Tim takes these insights as reinforcement of the importance of exploring data transformation strategies before moving to further phases in the VA process or any data mining process. This process is shown in Figure 5 as
Applications
To showcase the possible advantages of using PrAVA, we created two application scenarios to describe the efforts made to understand datasets with tabular data. We looked into online repositories for open datasets that could be used in the scope of classification problems, and we selected two datasets that we did not have any previous knowledge of. In Subsection
Mammographic mass dataset
We selected a dataset from the UCI Machine Learning Repository related to the breast cancer screening method. 64 This dataset contains the discrimination of benign and malignant mammographic masses based on BI-RADS variables and the patient’s age. We decided to start by running our prototype to collect information about the dataset for understanding it.
First, while reading the information available on the

We explored the
Additionally, we explored the
As a final step, we consulted the documentation available for the dataset to confirm some of our findings and assumptions. For the
We completed the initial understanding of the dataset, and we decided to move to the evaluation of the missing value imputation strategies. We used the entire original dataset, except column 0 (
Through this scenario, we show some capabilities of using PrAVA, mainly during the data understanding of a new dataset, facilitated when accessing summarized information at a glance, and details on demand. Within minutes, we acquired an overview of the dataset. Furthermore, PrAVA effectively supported the comparison of the results for the different preprocessing strategies, not only because
Cervical cancer dataset
In this second application, we describe the efforts made to understand the cervical cancer dataset that has been acquired from the UCI Machine Learning Repository. 65 We want to know, based on the dataset, which conditions suggest a higher probability of a patient having cervical cancer. To help in the task, we use Tableau, 53 Tableau Prep Builder, 51 and Python programming. Note that when we perform an action that represents a new transition introduced by PrAVA (i.e. the blue dashed lines in Figure 4), we highlight in parentheses the transition that was made.
We decide to load the dataset in Tableau Prep Builder, which should allow us to analyze the missing values and find other issues to address the simpler ones quickly. The visualizations provided by Tableau Prep Builder (Figure 10-a) show the distinct values of every column and, for each value, the number of rows with the same value. Immediately, we can notice that not all variable types were inferred correctly (
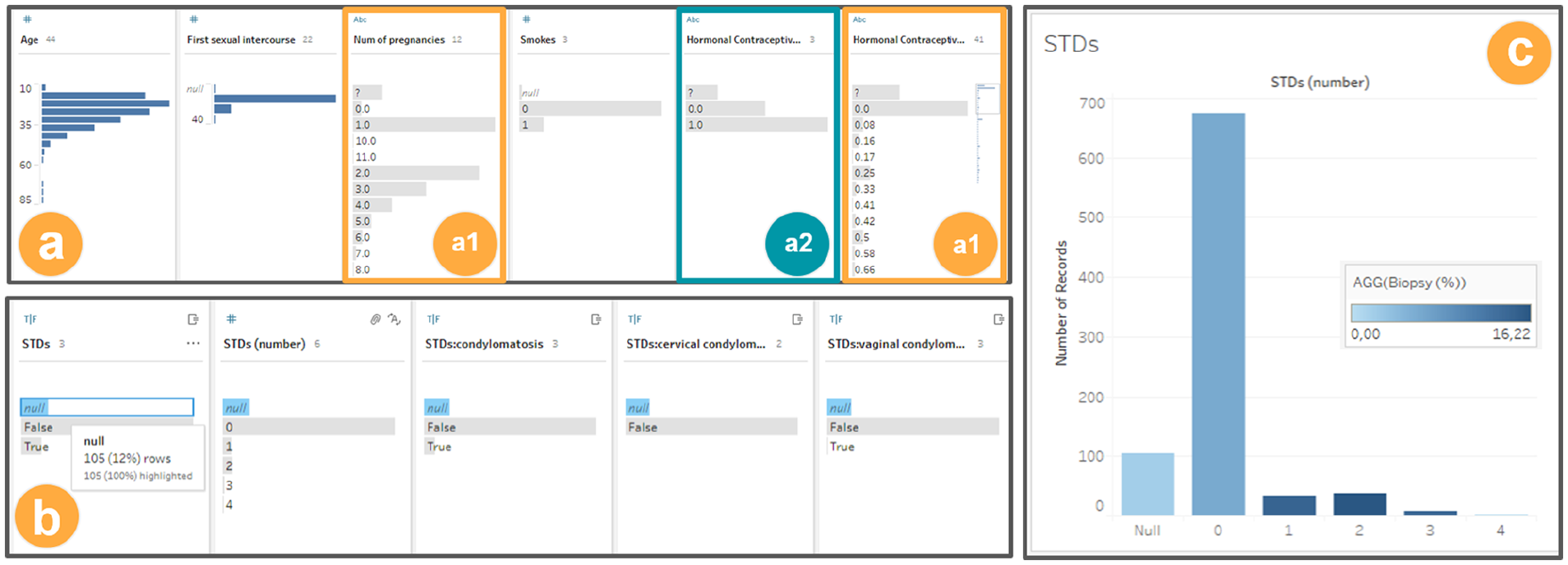
(a) and (b) Exploring the dataset with Tableau prep builder, and (c) histogram generated with Tableau. Both are using the cervical cancer dataset.
After correcting simple problems, we evaluate strategies to deal with the missing values. We examine again the visualizations provided by Tableau Prep Builder, as shown in (Figure 10-b). When a value is selected, for example, “null,” the same value is highlighted in the other columns. This helps us to observe that there is missing value correlation between several columns (
Wondering what the meaning of the discovered correlation might be, we transition from Tableau Prep Builder to Tableau and create a histogram of the
After analyzing the histogram, we reach a few conclusions. There is a positive correlation between
To validate this hypothesis, we choose the practical approach of using the Machine Learning Python library.
66
We create a second version of the dataset (
We proceed to train and test using a decision tree model with each dataset (
These results contradicted our expectations because no significant improvement of the results is noticed when changing the
As an alternative visualization for this case, we generated the Nullity Matrix in Python based on Bilogur,
41
which allows us to confirm the correlation among columns with missing values (
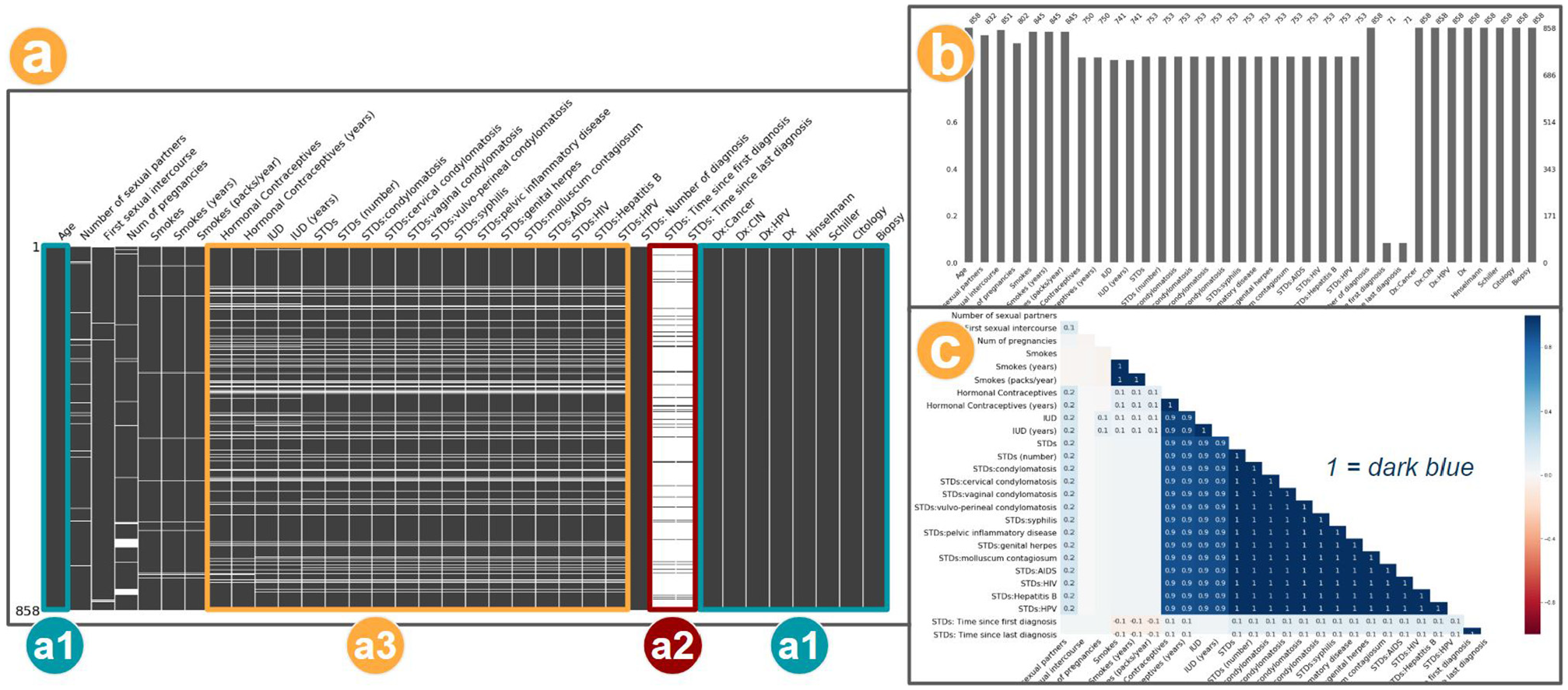
Three visualizations to explore the missing values: (a) matrix (a data-dense display), (b) barplot, and (c) heatmap for variables correlation. This output was generated based on cervical cancer dataset, and using Missingno. 41
Moreover, other visualizations provided by the same library consolidate the observed patterns (
Finally, after some additional testing, using combinations of different imputation strategies (
This use case serves as representation of how the use of PrAVA supports the process of data analysis. This is an example of how the use of a variety of visualization techniques promotes a better understanding of the data under analysis and the impacts of preprocessing. Also, we were able to save information of this process (metadata), which enhances the data preparation understanding itself, that is, the Preprocessing Profiling (
Review of scenarios
In this subsection, we present a discussion on how other studies are reporting preprocessing activities as part of their process. To conclude, we summarize how the PrAVA’s guidelines are related to the tools used during the application scenarios presented in this section.
How is preprocessing reported?
We did an exploratory search for recent works citing the two datasets used in this section. A total of 20 papers were considered: 11 for the mammographic mass dataset, and 9 for the cervical cancer dataset. This exercise supported us to validate our use cases process choices described in this section. We present in this subsection some points observed on the processes involving the preprocessing activities of these works.
The works using the mammographic mass dataset tend not to describe the preprocessing steps in detail. This may happen because of the influence of the work (Elter et al.) 67 for which the dataset was created that used a model capable of handling missing values. Two exceptions are Shobha and Savarimuthu 68 and Azam and Bouguila, 69 which elaborate automatic preprocessing techniques.
Other works that use the cervical cancer dataset tend to describe the preprocessing step in more detail, for example, Ahishakiye et al., 70 Ahmed et al., 71 and Ijaz et al. 72 The two primary data quality issues are (a) the missing values and (b) the unbalanced class distribution. The most common preprocessing choices for (a) include removing columns with high missing value ratio, removing rows with missing values, and imputation (mostly with the average and the most frequent value). For (b), the preprocessing strategy is the oversampling.
Most of the other works that use the mammographic mass dataset choose different ways of dealing with data quality issues, including models that accept missing values and automatic preprocessing. These techniques are not the focus of this paper as it is centered around human decision making. Meanwhile, the preprocessing methods we used on the cervical cancer dataset are similar to the mentioned works. Overall, we could not identify any work using visualization to support their process. Therefore, our use of PrAVA exemplifies the possibility of better-informed decisions and a less time-consuming decision process when using the appropriate tools.
As a final remark, we could find observations such as “unstandardized dataset sometimes affects the performance of some of the algorithms” (Ahishakiye et al., 70 p.10). That supports the value of the preprocessing strategies evaluation and its impacts to further steps of the process.
What is the relation with the guidelines?
In Table 3, we present the list of PrAVA’s guidelines (Table 2), their status regarding the implementation in each tool used during the application scenarios, and some examples of implementations. In other words, we highlight which guidelines were met by each used tool. The status appears as  to indicate an implemented guideline,
to indicate an implemented guideline,  to indicate not implemented guideline, and
to indicate not implemented guideline, and  indicates a limited or partially implemented guideline.
indicates a limited or partially implemented guideline.

Even though Tableau
53
and Tableau Prep
51
are widely used, there are still opportunities to implement further guidelines that should facilitate the preprocessing activities in a VA process, for example,
It is noteworthy that we do not intend to compare the developed prototype with any commercial software. Rather than that, we aim to show that PrAVA can be used independently of a particular tool. In conclusion, this list of guidelines should be reckoned as a set of practices to evidence the activities executed in the Preprocessing Profiling phase during a VA process. The more these guidelines are considered as part of the developed solution, the more effective the solution will be.
Discussion
In this section, we organize a final discussion of our findings during PrAVA’s design and its validation (Subsection
Lessons learned
The main findings observed during our literature review were explained in Subsection
Critical but less discussed
Preprocessing is recognized as a critical phase to the data analysis process, due to the data preparation time-consuming nature or its impacts on the final results. Contradictorily, it is still a subject that receives less attention from the VA and visualization communities.
Implementing all the guidelines is not a trivial task
During the scenario coverage planning, we realized that there are many combinations to consider to set up all the required components under a new solution in compliance to PrAVA. We may need definitions of questions as
Simplicity of the visualizations
Although most of the visualizations used in the usage scenario (Subsection
The value of an integrated tool
Through practicing on a developed prototype, three main advantages can be mentioned. First, considering we have the dataset loaded in the Python programming environment, with one command line to import the library and another to call the report, we can generate detailed and relevant information to support preprocessing activities. Consequently, we contribute to simplify the working procedures of data analysts, which is a big concern since it is reported as one of the most laborious tasks.
9
Second, as the reports present several metrics and visualizations by default, metrics that could be neglected by the data analyst due to unawareness, difficulties in applying, or limitation of time, can now be incorporated as part of their analysis. Third, this detailed information about the dataset and data preparation can be used as metadata for the preprocessing profiling phase. It helps build the principle of transparency on the activities performed, aligned to initiatives such as the European Union General Data Protection Regulation (https://ec.europa.eu/info/law/law-topic/data-protection/eu-data-protection-rules_en). As mentioned earlier, a system nor a tool is the focus of this work; however, during the usage scenario, the value of an integrated tool in this process was evidenced, which is aligned with
Awareness-raising
The actual VA process (Figure 2) can continue as-is since it covers confirmatory analysis cases, or when the dataset is well-known and automated methods for preprocessing are in place. However, its current representation conceals the importance of preprocessing. Thus, PrAVA better positions the critical components of preprocessing efforts. That is especially relevant in scenarios where the decisions made during preprocessing are crucial to the further phases of the process, and active participation of the data analyst is required. Moreover, other studies have explored the role of uncertainty as part of the VA process,25,75,76 and they emphasize that uncertainty in data can often be propagated during preprocessing activities. Thus, the efforts to develop alternatives to increase the awareness and trust of the data under analysis will contribute to a more reliable VA process.
Limitations
We identified four limitations in the current work that we consider important to explain.
Problem instance
As stated by Munzner 77 (p. 3), “Vis systems are appropriate for use when your goal is to augment human capabilities, rather than completely replace the human in the loop.” Hence, our scope considers the cases when the “human in the loop” is vital to the preprocessing. That means, the data analyst is still evaluating and formulating the questions about the data under analysis. For other cases, when the quality of the data is not a concern, the dataset properties are known, or all the needed preprocessing tasks are already mapped; thus, most of this process can be automated, and there will be no applicability to the approach we are discussing.
Guidelines’ list
To allow the extension of PrAVA to a variety of scenarios, and to facilitate its adoption, we have tried to design our approach as general and as simple as possible. As a consequence, if on the one hand, PrAVA may cause a first impression that some of the guidelines are quite obvious. On the other hand, it may not explicitly indicate all the complexity behind preprocessing. However, using the guidelines will result in solutions in which preprocessing is consistently considered. It is hard to assert that all potential scenarios are covered and new guidelines may emerge in the literature over time or from different types of applications that were not considered. Overall, we still consider helpful keeping the nine proposed guidelines structured for a consolidated reference.
Usage scenarios
We have not intended to present a detailed description of the types and strategies applied to the preprocessing scope, since we consider it a subject to another dedicated work (see Subsection
Applications
We decided to proceed with the use cases (considering the definition from Ward et al.
14
) to support the PrAVA validation strategy instead of using empirical methods with the participation of data analysts or domain experts. As part of the mitigation for the risks in not covering a realistic scenario, as explained in Subsection
Research opportunities
Interesting research directions in the scope of preprocessing and visualization were introduced by Kandel et al. 4 Although this work contains the perspective of a decade ago, its discussion is still relevant. Shall this be explained by the fact preprocessing as an object of study has received less attention from our community? In any case, to advance the discussion, we are indicating promising directions for further research.
Preprocessing + Visualization taxonomy
A comprehensive and up-to-date taxonomy of data quality issues related to preprocessing strategies and visualization techniques is needed. This effort should include the type of data quality, the issue description, the detection methods, the preprocessing transformation methods, and visualization techniques that can be used to assist in this process. To illustrate, a good start could result in an enhanced combination of the discussion presented in Kandel et al. 16 (preprocessing + visualization) and Kim et al. 1 (taxonomy of data issues).
Complementary to the previous point, the exploration of the preprocessing strategies considering the challenges of application domains, for example, fraud detection or public health, and data mining scope. Moreover, besides the perspective of the data analyst, other perspectives can be explored as well. For instance, in healthcare, the preprocessing tasks are often done by the domain expert.
Visualizing data issues
We can consider two main groups of new visualizations to be explored. One is related to the understanding of data issues in raw data. Providing different views for the same data issue may allow discoveries that could not be noticed using just one visualization.
An alternative is to create a coordinated multiple view framework for different data issues. A similar idea was proposed by Sjöbergh and Tanaka
34
in the scope of missing values. Along with missing values, the outliers are another frequent data issue that requires attention, because
Although the VA and Visualization community have a strong foundation in cognitive human perception and a variety of methods and techniques have been developed to create visual metaphors of the data, in the context of the preprocessing, we still can formulate a question like
Systems and tools
Despite the fact we can find studies such as Zhang et al., 79 and its more recent revision Behrisch et al., 80 evaluating VA commercial systems in Big Data scenarios, we consider it worth to continue a comparative review of the state-of-the-art for open source and systems with special attention to preprocessing. As part of this discussion, it should be evaluated if the planned guidelines of PrAVA are attended or not.
Recommendation
Although multiple works have presented advanced solutions in the scope of data cleaning and transformation recommendations, within
Big data
Regarding data transformation activities in high-dimensional data, Liu et al.
81
provide a comprehensive survey on the topic that can be used as source of inspiration. While the Progressive Visual Analytics, proposed by Stolper et al.
56
indicates an alternative to handle Big Data scenarios, its adoption may cause new challenges, such as whether a current partial outcome is already good enough.
82
In the scope of preprocessing (
Likewise, careful validation of aggregation strategies, as indicated by Elmqvist and Fekete, 57 is needed to allow any visual metaphor to scale while analyzing large and complex datasets. Otherwise, a wrong design decision may introduce data distribution issues that may impair the visual identification of any pattern. For these cases, the resulting visualization is diminished and leads to uncertainty in the data. 25
Conclusion
A state-of-the-art literature review and the practitioners’ testimony in data analysis allowed us to reach the following conclusion: Data preprocessing is seen as one of the most laborious and time-consuming – and even tedious as stated by Kandel et al. 4 – activities of the data analysis process. Notwithstanding, few works in the Visual Analytics and Visualization areas address the challenges related to preprocessing as their research subject. Moreover, some studies do not explicitly consider preprocessing as an equally important activity to the knowledge discovery process’s final findings.
Thus, in this paper, we presented the Preprocessing Profiling Approach for Visual Analytics (PrAVA). Our main contributions can be summarized as introducing PrAVA as an alternative to support data analysts during preprocessing activities. By enabling better data understanding and evaluating preprocessing impacts, these methods should promote data quality and provide grounds for decision-making on data preparation strategies. Ultimately, we hope that we encourage a shift to a visual preprocessing.