
Abstract
Introduction
Process data changing over time is often recorded as discrete event sequences in various domains. An
A collection of long event sequences typically contains a shared high-level event structure, for example, processes in a hospital, with events grouped by patient or doctor. This structure can be a set of
The derived multi-level stages differ in duration and, therefore, subsequence length. Understanding the underlying high-level structures by discovering stages from different abstraction levelsallows to verify if cases are treated consistently in the system, for example, hospital patients, factory products, etc. The factors that influence the quality of a discovered stage depend on the domain and the specific user query in mind. Therefore, users need to understand the stages on different aggregation levels, for example,
State-of-the-art event sequence visualizations often focus on detailed, low-level patterns 10 or the stages are constructed based on fixed time windows, for example, the work of Guo et al. 11 Fixed windows segment the sequences in subsequences by using a fixed time period or number of events to create the stages rather than building stages that are semantically meaningful or have shared events/patterns. For example, in the hospital emergency department, patients are treated differently and their treatment duration can differ drastically. The sequences of these different patients cannot be clearly split using fixed time windows. The context and event labels are ignored using this splitting method, and the split can occur in the middle of a treatment. Also, the semantically similar time periods, (a set of) treatments and medications treating the same (phase of a) disease, are not known upfront and differ in length. Closest to our research is another work by Guo et al. 8 that with a maximum average sequence length of approximately 800. However, the subdivision method is rather black box using methods from the text analysis field and ground truth information on stages is typically unavailable. This hinders the interpretation of the discovered stages, which is important to be able to use the results of the stages. Whether the methods focus on low-level patterns or high-level structures, visualizations, for example, Sequen-C 3 or Guo et al., 8 have visual 8 and computational3,8 scalability challenges. This hampers the visualization of long sequences and the interactive injection of domain knowledge to adapt the stages in the staging algorithms, respectively. Interactive visualization of those stages is needed to explore and discover the high-level structures.
We present LoLo, a domain-independent interactive visual analytics method to analyze long univariate event sequences. It considers
a strategy to discover stages that allow for semantic
a visual analytics approach to analyze the multi-level structure of long event sequences by identifying
The paper is structured as follows: first, we identify tasks for analyzing long sequences and related work. Second, we describe the stage generation and visualization. Third, using two real-world data sets, we evaluate LoLo with two experts and present a discussion and conclusions.
User tasks
We identify which tasks are most relevant when dealing with long sequences. Our target user group is data analysts/researchers working with long sequence data in different domains, such as healthcare, security, and energy. We analyzed and identified user tasks based on tasks and challenges from papers mentioned in related work, and additionally, discussions between the authors experienced with event sequence visualization.
Related work
In general, researchers and domain experts perform several main tasks when analyzing event sequence data, such as comparison 4 (similar to T3) and summarization 14 (similar to T2). Users execute these tasks on data of varying sizes which typically influence the analysis process. For example, a large number (more than a thousand) of sequences,1,3,13,16,17 a large number (more than a thousand) of categories, 1 a large number (more than 50) of attributes, 2 or long (more than a thousand events) sequences. 13 Data reduction strategies help reduce data variety and volume. 18 To go into more detail of discovering stages and visualizing them in long sequences, we first describe an overview of related work regarding finding and analyzing high-level structures, for example, stages, in event sequence collections. Second, we discuss related work visualizing those.
High-level structure identification
As mentioned in the introduction, there are
Fixed staging is the most common approach, also present in related fields, such as network visualization, where methods use fixed time intervals to discover stages.11,19,20 However, the process underpinning the sequences is not always bound to fixed time intervals, for example, emergency treatments in a hospital. Fixed time intervals likely cause sequences to be cut in the middle of their high-level structure. A sliding-window approach 20 partially solves this, but still there is the challenge on how to define the window size.
With dynamic staging, that is, stages based on the event sequence data and not a predefined time-span, there are solely non-interactive black box machine learning methods such as hierarchical clustering
21
or coordinate ascent strategy/expectation-maximization algorithms
22
to discover stages. It is difficult to interpret and reason about the resulting stages.
11
On the other hand, there are interactive visual methods. DPVis
23
provides a visual analytics methods to discover states using hidden Markov models and aim for interpretability. However, in their approach, they discover states, that is, each multivariate event is given a classification, instead of segmenting a sequence collection in stages (our aim). Chen et al.
15
construct a hierarchical visualization based on frequent patterns, having multiple hierarchical visualizations to describe the entire data set. It is hard to capture the high-level structure of the entire collection (T2 and T5), because identifying where in time the patterns of different hierarchies occur is not straightforward. Moreover, when the length of the sequences increases, the hierarchical trees become large. Another example, closest to our work is the method from Guo et al.
8
with sequences of a maximum average length of 800 events. They took inspiration from the text analysis domain to discover stages by applying computations on the events, represented as event co-occurrence likelihood vectors. Although, they provide visual information about the event structure, the stage computation method is largely black box, making the
Visualization of high-level patterns
We identified two main trends in visualizing high-level patterns or stages:
Overall, most methods do not focus on long sequences. It is not possible for users to explore hierarchical (T5) stage
Stage discovery method
We present definitions and discuss the multi-level stage discovery process.
Definitions
In this work, we assume univariate events with a label and a timestamp (no duration), representing discrete occurrences of activities grouped as sequences. We define an event as
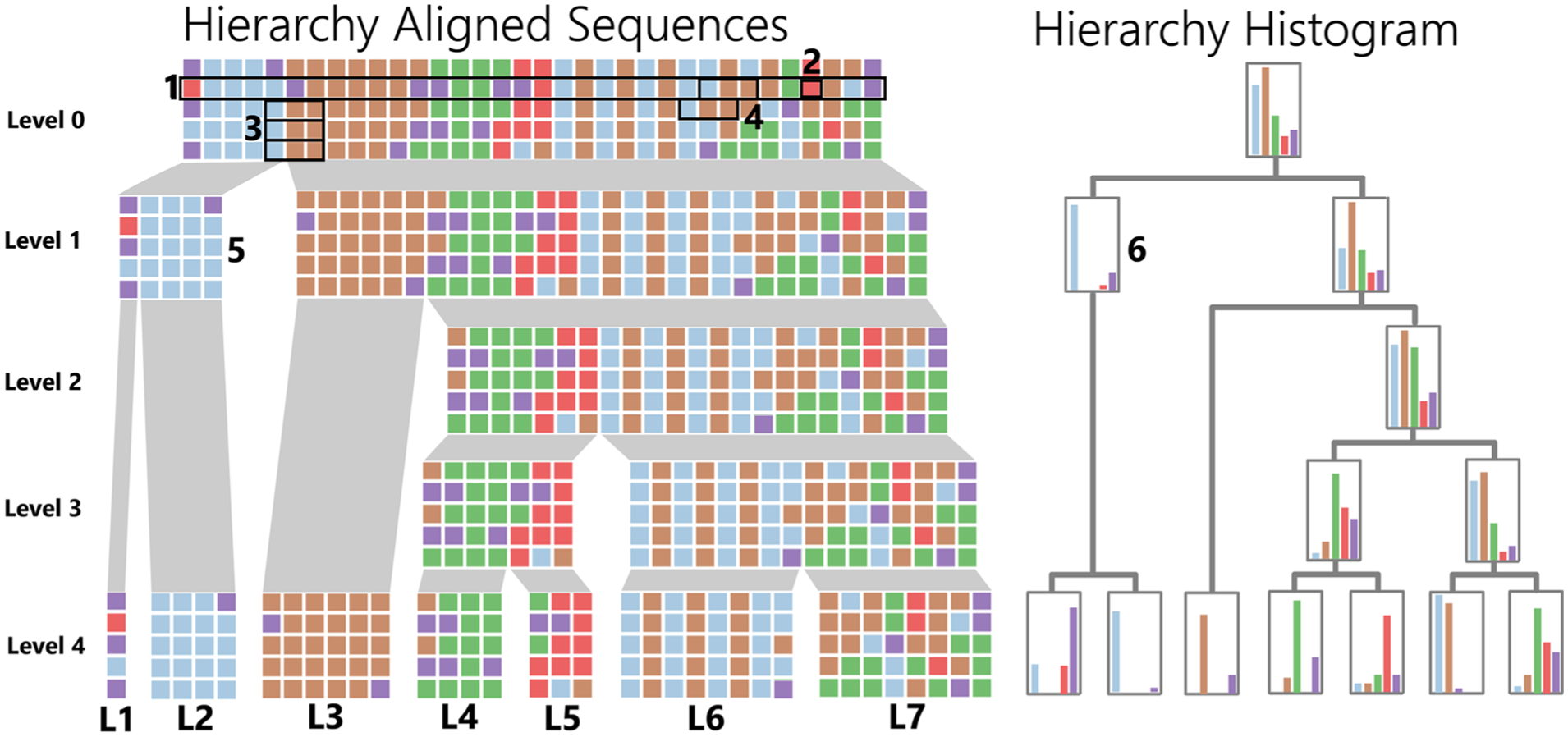
Global staging: On the top left (level 0) are the five original input sequences. A sequence is horizontally displayed (1) with each event (2) in chronological order. Patterns are subsequences present in one or multiple sequences, for example, the blue-brown-brown pattern (3–4). During global splitting these sequences are recursively split in two children represented by the hierarchical flow. For example, the original sequences (top on the left) are split into two children, for example, the left child (5). These children are split again etc. The final children (leaves) are the global stages (L1–L7). This splitting is hierarchical. To determine the splits, the (sub)sequences involved in the split are transformed to a data structure of histograms of their event or pattern frequencies. In this case, the event frequencies are seen on the right. For example, parent 5 on the left corresponds to histogram 6 on the right.
Discovering stages
We believe that four key concepts, related to stage discovery in long sequences, are crucial and differentiate LoLo from related work;

After the global splitting, the leaves (L1–L7, see Figure 1) are used in the local splitting. Each two consecutive leaves are merged, for example, L6 and L7. The subsequences are clustered and per cluster the splitting is run again. This results in the final stages. The local splitting is only done with the leaves of the global splitting. The results from this are used to create the final hierarchy.
Building histograms
As we aim for stages with similar behavior, the discovery depends on both the homogeneous event labels and their order. We assume patterns are precomputed with, for example, the VMSP algorithm27,28 that provides a concise representation of all patterns. 29 The focus of this paper is not on pattern computations. Any pattern algorithm can be used to generate the pattern file. This pattern file, similar to the aligned sequences, is an input file of LoLo. To represent the event data, the (sub)sequences are converted to histograms displaying the event label, for example, histograms in Figure 1 right or Figure 3 top, or the pattern frequency, see histograms Figure 3 bottom. Each bar in the histogram represents the frequency of one unique event label or unique pattern. Visually, the order of the bars is the same for all histograms, alphabetical. Computationally, the order does not matter for the splitting and events or patterns with a frequency of zero are not taken into account. Both discover different stages with other characteristics. For example, when using event labels for splitting, the blue subsequences at the end of every sequence are discovered as a stage, see Figure 3 top. We use patterns of consecutive events to represent often occurring event orders. These generate different stages, see Figure 3 bottom.
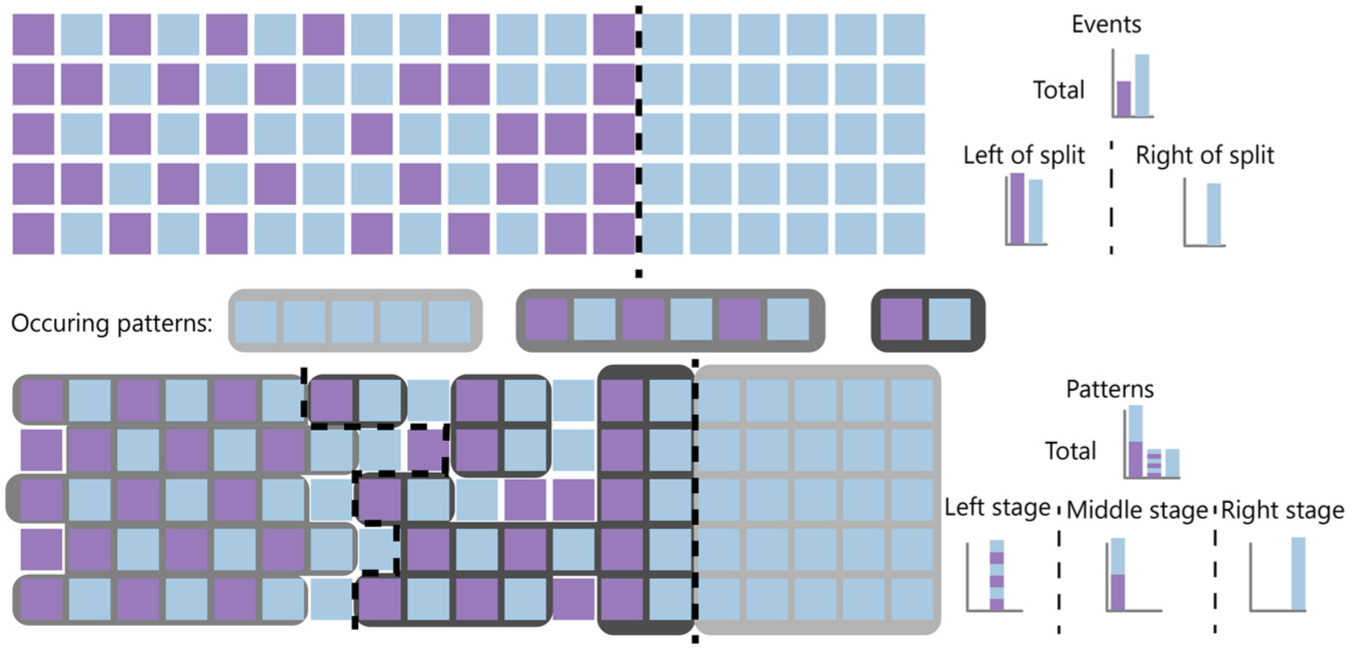
Example of the differences between splitting based on events (top) and patterns (bottom) for the same sequences. There are five sequences with two possible event labels, purple and blue. Assume three possible patterns occur. The background colors indicate where these patterns occur in the bottom sequences. The dotted lines indicate the splits based on events or patterns. The right side indicates the histograms associated with the splits. For explanation purposes, we assume each sequence is their own cluster in the local staging.
Distance measure
The distance measure is based on our definition of a stage. As we want our stages (distributions of events or patterns) to be as homogeneous as possible, we select Information Gain 30 to compute the split scores for the staging based on the histograms. Information Gain, often associated with decision trees, aims to split attributes (sequences in our case) such that resulting subgroups are homogeneous:

where

where
Global staging
Since we assume sequence alignment and that sequences have the same high-level structure, we deduce the following. The same event labels of the sequences are predominantly grouped around the same indices, for example, the first event of each sequence is at index zero, the second event at index one, etc. LoLo uses an exhaustive greedy search to discover the global splits. This global staging is similar to data reduction strategies as proposed by Du et al., 18 that is, merging events by time window and merging events into one abstraction. We adapt this by considering time-varying windows and abstract multiple events of multiple sequences in one stage.
First, LoLo determines all potential split indices; index

Local staging
LoLo computes local stages as variations of the global stages, which capture local nuances in the global splits using clustering on each two consecutive stages (leaves of the hierarchy). We first cluster the sequences in every two consecutive stages using density-based clustering (DBSCAN), 31 see Figure 2. We opted for density-based clustering as it does not require to specify the number of clusters. Distances between sequences are computed based on the histograms using the Jensen-Shannon distance. 32 We use this distance because we do not want to segment sequences in two homogeneous children, but rather base it on their similarity. We also experimented with dynamic time warping. 33 But this is computationally expensive, even with the relatively short (a couple of hundred or a thousand events) sequences. The density-based clustering method has an epsilon parameter related to what is considered dense and a minimal number of points within that epsilon radius parameter. Second, LoLo computes a new split for each cluster or noise sequence based on the histograms. The splitting is performed similar to the global splitting. Now, LoLo only considers the information of the two consecutive stages of that cluster or noise sequence, see Figure 2. Based on this, the final hierarchy is seen in Figure 4. There is a (user defined) maximum allowed deviation to avoid large deviations from the global split. This results in the local stages, see Supplemental material for details. We use an epsilon 0.2 and a minimal number of points of 2 for the density-based clustering, which were experimentally found adequate for our data.
Visualization
In this section, we describe the visualization part of the LoLo method based on its four key concepts;
Hierarchy
For the stage hierarchy plot, see Figure 4, users should be able to inspect different (aggregated) levels of detail (T5) (two examples of the hierarchy plot are Figure 5(c1) and (c2), compare them (T3), and understand transitions (T4). As mentioned in the Global Staging, LoLo discovers stages with a top-down hierarchical approach implementing a user-based focus and context approach enabling scalability and flexible switching. The stages are the leaves of the hierarchy. The top part of the stage hierarchy plot represents the hierarchy levels, see Figures 5(d) and 6. LoLo represents each level of this hierarchy using an adapted icicle plot. Each stage has a header label with the stage name, for example, S0, see Figure 5e. This hierarchy visualization provides users insights into how the data is split into stages and offers different levels of detail (T5).

LoLo’s interface where each stage is represented as a circle in the stage similarity plot (b). Stages are displayed in an icicle plot with different levels of detail (c1, c2), and hierarchy on top (d); the stage header color (e) corresponds to the scatterplot (b) colors to identify similar stages. The horizontal stacked bar charts (d) represent the frequency of each event label for each level of the hierarchy (e.g., the ascendants of the stages) and are colored based on the event label. Examples of user-selected (a) display levels are: the aggregated level with and without (c1) normalization of the bar charts, and the detailed level (c2). Normally, only one display level, for example, c1 or c2 is displayed. The bars of the histograms in c1 and d, and the events in c2 are colored based on event labels.
We use an adapted icicle plot because it preserves the temporal order of the stages, allows to show abstracted information of each stage hierarchically, and provides the ability to focus on stages of interest without loosing the hierarchical overview. Initially, the whole hierarchy of stages is displayed, providing a high-level overview for each stage in the hierarchy. Horizontally stacked bar charts, see Figure 5(d), represent the proportion of the different event labels or patterns (depending on the global staging distance measure) that occur in each level of the hierarchy for all ancestors of the stages. If there is insufficient space to display the stacked bar chart, the top frequent labels or patterns are displayed depending on the available space. Also, a red triangle is added in the lower right corner to indicate that some label or pattern frequencies are left out of the visualization. LoLo enables users to close (collapse) and open (expand) stages, see Figure 6. This provides users with a focus and context mechanism. The context switching by changing levels is animated to preserve users’ mental model. All expanded stages, receive the same amount of screen space to emphasize that each stage is potentially equally important. LoLo enables users to expand ancestors of the stages, see Figure 6(b). A parent is displayed in the same way as a child stage, with the collapsed children displayed underneath, see Figure 6(b1). The content of the expanded stages and (grand)parent stages are horizontally aligned to make comparison (T3) easier. Overall, we adapted an icicle plot to be able to display the hierarchy of stages in relation to the sequence data both chronologically and hierarchically. Through different representations, for example, the stacked bar charts and opening or collapsing stages, we provide further information for the understanding of the method.

Example of the hierarchy where the (grand)parent stages are indicated in purple and blue, respectively; (a) describes what happens if users close the redly marked stages by clicking, (b) describes what happens if users expand a parent or grandparent, indicated in green. Their children are closed (b1).
Explainability
Understanding the constructed stages and their transitions (T4) is important because there is no way to validate the stages automatically. LoLo displays the subsequences in an expanded stage on three different aggregation levels; as a most aggregatedoverview the corresponding histograms of the expanded stages are shown (1), see Figure 5(c1); as compressed information (mid-level) where each × consecutive events of the subsequences are merged into one event (2); or as detailed information (3), see the rectangles representing individual events, such as the blue ones in Figure 5(f). By default, LoLo displays the most aggregated overview of all the discovered stages. The aggregated overview consists of histograms because these are easy to interpret and scalable visualizations that increase the understandability. When users hover over a stage header, LoLo shows a tooltip with the time of the earliest and latest events. Users can choose between non-normalized and normalized bar charts. Non-normalized bar charts inform users about the number of events or patterns, depending on the global staging distance measure. Normalized bar charts help to compare the event label or pattern frequency histograms, depending on the global staging distance measure, to understand the computed splits. This increases explainability because the splits are based on differences between those histograms. For the normalized bar chart, the highest frequency in that chart is scaled to a hundred percent and the other bars are scaled relative to this. To increase visual scalability, the histograms can be shown in different levels of detail depending on the screen space; vertical stacked bar charts, see Figure 10(d), and histograms with, see Figure 5(c1), and without axis, see Figure 8(b). For patterns, the bar representing it is colored based on the pattern, see Figure 11. For example, if a pattern consists of event A followed by event B, the first half of the bar representing this pattern is colored with the label A color and the second half with the label B color. If there are more than 20 unique patterns, the 20 most frequent ones are included in the bar charts for visual scalability reasons.
The detailed information view displays the original subsequences present in the stage to verify in which (groups of) sequences certain event labels or patterns occur that are responsible for the stage splits. Each ordered subsequence is represented by horizontally aligned event blocks. The different stages’ subsequences are horizontally aligned to enable visual comparison. The color of an event block is determined by its label. The event types scale visually to the 15 labels with the highest frequency, based on the qualitative scales from ColorBrewer. 34 This ensures the colors of the different events are still distinguishable. All other label categories are colored gray. This means that in LoLo the components seen in Figure 5(c1), (c2), and (d) are colored using this color scheme. The mid-level displays a compression of the events to increase visual scalability. For example, if there is screenspace for 10 events and a hundred events present, each of the 10 events is compressed into one based on the highest occurrence frequency. By zooming in and out, this compression ratio becomes less or more. This relates to the bucketing events using a fixed time window data reduction strategy. 18 To help with verification, users highlight event labels and patterns interactively. At the compressed or detailed level users identify why certain stages were discovered and how they differ (T2, T3, T5). Users can manually select and highlight patterns at the compressed or detailed level.
Users can cluster the subsequences within one stage for visual inspection based on their event labels. Users are free to change the epsilon value, related to what is considered dense, for density-based clustering of these subsequences. This epsilon is for clustering within one stage, not the epsilon for clustering in the local staging between consecutive stages. A consequence of the clustering is that the horizontal alignment of sequences, the subsequences of sequence × have the same vertical position in all expanded stages, over the different stages is no longer preserved. Due to clustering, this vertical position differs per stage, but via highlighting interaction, the subsequences of the same sequence are identified. To further ease comparison (T3), LoLo enables users to align the sequences horizontally based on the clustering of a selected stage, see Figure 9. The clusters of the detailed level and mid-level are the same and based on the detailed sequence information. Gray arrows will appear on the sides to indicate when more sequence information is available through panning to the left or right within one stage. To aid the comparison (T3), we implemented linked zooming and panning to ensure that the horizontal alignment of the bar charts or the blocks are synchronized.
Stage similarity
The stage similarity plot, see Figures 4 and 5(b), and the stage headers in the hierarchical plot, see Figure 5(d) and (e), enable users to identify stage similarities dependent and independent of time (T2). Each stage (leaves of the hierarchy) is represented as a circle in the stage similarity plot, see Figure 5(b). We use UMAP 35 for this stage analysis, where pairwise distances are computed using the distance metric as selected for the global splitting, see “Distance measure” section. The circles are semi-transparent to indicate density. Users typically need to identify how and when stages transition over time (T4). Therefore, by default, the headers of the stages and circles in the similarity plot are colored in grayscale based on their timestamps to identify the re-occurrences over time in the similarity plot. Another option is to project a 2D colormap on top of the scatterplot, where the four corner colors originate from Steiger et al. 36 Users are enabled to color the circles and stage headers based on the 2D colormap, see Figure 5 (T2). This means that in LoLo the components seen in Figure 5(b) and (e) are colored using this color scheme. (Grand)parent headers are colored the same as the header color of their middle leave. An example of two similar stages are stage S0 and S7 in Figure 5. The headers both have a yellow-green color, for example, the header of S0 (Figure 5(e)). The S0 bar chart describes this stage as many blue events, some purple events, and little red events. S7, see Figure 5(f), also has the same composition of event labels. There are several interactions available to users. When users hover over a circle, the corresponding stage is highlighted in the stage hierarchy plot. By selecting multiple circles, the stages represented by these circles in the stage hierarchy plot are expanded. When users click on a circle, the stage in the stage hierarchy plot collapses or expands, depending on its state. The circle size depends on the stage state, that is, large if expanded, small if collapsed.
Interactively redefining stages
Based on the hypotheses of the users, different aspects of the data are of importance. Therefore, users are enabled to redefine the stages (T1) by adapting the parameters, see Use Scenario Neighborhood Complaints Data for an example. The different parameters are the stop condition for the splitting (cumulative IG percentage), the maximum event deviation between a local and global split, the minimum number of events per stage, and whether event or pattern frequency histograms are used for the global and local staging. Filtered-out sequences and event labels will disappear from the visualization. When stages are based on events, the filtered-out event labels are not taken into account during staging recomputations. On the detail level, events having a filtered-out label are replaced with an empty space to preserve the multiple sequence alignment. The redefinitions are interactive due to the choices made on the algorithm used to build the hierarchy. The methods have relatively low computational costs while being informative.
Evaluation
We first evaluate the interactivity of LoLo by analyzing the staging algorithm’s running time. Second, we compare LoLo against a baseline of fixed staging. Third, we evaluate LoLo with two use cases on two real-world data sets.
Computational
We claim that LoLo can be used interactively to refine the stages. Here we discuss and evaluate the running time for computing the stages. We use the electrical energy consumption data from 37 different buildings at our university campus from 2019 up to 2022. The data is provided as a time series; to transform those into events, we bin the data in six categories/labels from low to high using quantiles normalized per building. Each sequence represents 1 year of data for one building and each event the binned energy usage of a certain point in time. We align the data based on their timestamps. Only 0.5% of all the events are gaps introduced by the alignment due to missing data and leap year. There are 152 sequences, each with a length of 35,136 events. These precomputations generate the input file for LoLo.
The global staging depends on the number of splits, which relates to the depth of the hierarchy and the stage parameter, responsible for the number of stages. The local staging depends on the number of splits, which relates to the number of clusters and the staging epsilon parameter. To provide an indication of the running times, see Figure 7 and Supplemental Material. The experiments were run on a conventional laptop (Intel i7-9750H CPU, 32GB RAM). Considering a sequence length of approximately 35,000 events and the assumption that users recompute the staging, but not extremely frequently during one use, we consider this running time of approximately 13 and 37 s for staging based on events or patterns, respectively, adequately for supporting the analytical and exploration workflow. Increasing the event types, that is, the number of quantiles in the energy data set, for example, to a hundred event types, increases the running time for staging based on events. However, increasing the staging epsilon reduces the total running time and the number of splits. Also, more event types in this dataset mean fewer patterns. Moreover, increasing the number of sequences increases the running time. When the number of sequences increases, relatively less time goes to the splitting and more to the other functions in the staging algorithm. 84% and 91% of the staging time goes to splitting based on events and patterns, respectively, for 10 sequences, and 32% and 9% of the staging time goes to splitting based on events and patterns, respectively, for a thousand sequences. See Supplemental Material for the details. Overall, the running time for computing the stages of long sequences based on events is adequately for supporting the workflow but increases when the number of event types or sequences grow.

Staging computation times (left) and number of splits (right) for LoLo’s staging algorithm for sequences of different lengths, based on splitting on events and patterns. The percentage indicates how much of the sequence length of the energy data from the energy use case is included. For example, 50% are the first 6 months of all the sequences. The stage, minimum event, maximum deviation, and staging epsilon parameters are 0.025, 500, 100, and 0.2, respectively. In total, there are 100 unique patterns and 378,124, 284,705, 186,050, and 92,366 patterns in the 100%, 75%, 50%, and 25%, respectively.
Baseline comparison
We compare LoLo’s staging method to a baseline method where we use fixed time-windows. Comparing LoLo to dynamic staging baselines is hard, because there is no defined baseline neither is there a ground truth. Moreover, if we would select a method, such as from Guo et al.,
8
this likely results in different stages compared to our method, but we cannot conclude one is better over the other as there is no ground truth. We included energy data for the month of January of 1 year. This results in 38 sequences of length 2976 events. We used two different time windows for the fixed staging; either 1 week or 1 day. Figure 8(a) shows that fixed staging of 1 week gives three very similar stages (second to fourth bar chart) since the weekly pattern is similar. Fixed staging per day gives many stages, we can recognize the weekend days, see circles in Figure 8(b). It is hard to get an overview of the similarity between stages and where they repeat over time. Moreover, similar semantic consecutive stages could be merged. As Figure 8(c) shows, our staging based on events is, overall, able to differentiate between holiday, weekends and weekdays based on the content of the stages. The stage header colors show where similar stages are repeated and similar workdays are merged together in one stage. Friday nights and Monday mornings are, in general, included in the weekends as well since people are not working yet and there is low energy usage. This separation is not present in the fixed staging. In Figure 8(d); splitting based on patterns, the staging has trouble separating Mondays and Fridays from the weekend and the work weeks often consist of multiple consecutive stages, but working periods are also visible. There are also multiple occasions in which there is no trivial or meaningful definition of a fixed window, for example, the hospital example from the Introduction. It could take several refinements and re-computations of the stages to find the suitable stages for a data set, since the number of stages is unknown upfront. Therefore, the flexibility to refine the stages

Fixed staging based on weeks (a) or days (b) compared to our staging based on events (c) or patterns (d). White circles indicate weekends in b and work periods in (d). The yellow stages are work periods in (c). An example stage histogram of working and weekend periods is displayed in (c) and (d).
Use case energy consumption data
We evaluated LoLo with two users: P1, a data scientist in the energy sector, and P2, a data scientist researcher mainly working with genomics data. The goal is to discover high-level structures in the energy usage of buildings and similar and outlying energy usage periods over the year. P1’s evaluation is leading in this section. P2’s feedback is mainly used from a usability point of view because P2 is familiar with sequence data but in a different domain. Based on the same set of specific tasks, see below, and our instructions, we let P1 and P2 interact with LoLo. Afterward, they filled in a five-point Likert scale system usability scale 37 questionnaire, where a score of one is strongly disagree and a score of five is strongly agree.
We initialized LoLo based on event staging (using events for global and local splitting, stage parameter of 0.025, minimum events 500, and maximum deviation 100) and color the stage headers based on similarity. 25 stages are discovered, S0–S24. We asked the participant to share their first impression of the yearly energy data in the high-level overview. The first thing P1 noticed is that the winter (at the beginning, until March, and end of the year, November/December) and summer (the other parts of the year) periods differ (T3). Also, the first and last stages correspond with the Christmas holiday and are more similar to the summer period, likely because the buildings are closed (T2). Furthermore, there is one stage, S6, with a header color different from the surrounding winter stages, which P1 also suspected as a holiday period (T2). However, it is not a holiday period and something else is going on, see below.
Two main clusters are visualized in the stage similarity plot. Next, we asked the participant to select multiple points in the stage similarity plot from each cluster to identify the differences between the clusters, see Figure 9(b). All the stages that were not selected in the scatterplot are closed, such that only the selected stages remained expanded. After selecting two stages from each cluster, P1 and P2 noticed that the high-level histograms of the different clusters almost have an inverse relation of ascending or descending occurrence frequency from q1 to q6 (T3). Since the histograms directly relate to how the stages are split and the hierarchy is build, they help users reason about why these stages exist. This is harder to do with state-of-the-art methods where stage summaries are not related to the splitting of the stages, for example, Guo et al. 8 We also asked the participant to make this comparison on the low and mid-level (T5) by changing these four expanded stages from a high-, to a low-, and mid-level. The low level is too detailed, according to P1, to conclude something about the clusters quickly. P1 noticed on the mid-level that blue stages have indeed more events of darker colors and that there is probably some night and day rhythm within the stages.

Three expanded stages on the mid-level describing the Christmas transition, S22–S24 (from the 10th of December to the 31st) see (a), where the sequences are ordered based on the clustering, see C1–C6, of stage S24. For example, if sequence 10 is displayed (vertical position on the screen) as the third sequence from the top in S24, then the subsequences of sequence 10 in S22 and S23 have this same vertical position, that is, third from the top in S22 and S23. The event labels are q1 to q6, low to high energy, and dark green to light green (see Menu). Most buildings, see C1 and C3, have many high-energy events in the winter (S22, the pink stage header), fewer high-energy events towards the Christmas break (S23), and even less during the Christmas break (S24). While some buildings have many high-energy events in all three stages, see C2. (b) describes the two clusters of all the 25 stages (a + d): blue and pink. (d) describe the collapsed stages S0–S21. One anomalous stage (S6) is surrounded in time by pink stages (S5, S7).
Afterward, we asked the participant to select the last three stages to investigate the transition to the Christmas holiday. Now, only the last three stages are expanded and the rest is closed. Based on the mid-level, P1 mentioned that there is a daily pattern, see Figure 9, and that some buildings are more similar to each other. We asked P1 to select the clustering option and align them based on the clustering of the last stage to more easily compare (T3) sequences within stages and their transition (T4), see Figure 9. P1 noticed that some buildings in S24 only have the lowest energy level. Also, P1 mentioned that there is still higher energy usage in C2 and C4. C2 does not have a daily pattern and is always high. P1 wondered if machines are running constantly or if something else is happening. Moreover, P1 observed that darker sequences in S24, for example in C1, have higher energy usage, probably during the day, before Christmas. Similar, P2 mentioned that the light events followed by dark events pattern from the previous stages disappears in S24 for C1 and C3. Multiple levels of detail, among which the mid-level, contribute to the understanding of the stages and help compare them.
We asked P1 to investigate the outlying stage S6 (T2), see Figure 9(b), based on the high-level bar charts by expanding S6 and the surrounding stages and closing the others. S6 is a blue colored stage surrounded by pink colored stages, based on the stage headers. P1 noticed that there is missing data (gaps) by the frequency of the gap category in the high-level histogram. This is similar to the data in December, but otherwise, there is not much difference to S7. We explained that we can confirm if that stage was formed due to the gaps by rerunning (T1) the staging without gaps. After rerunning the stages, P1 saw, that the time period of the previous S6 is now similar to other winter weeks in the high-level overview. This was also noticed by P2. This is an example of how we think that LoLo
We also wanted to know if the patterns present a different data perspective. Therefore, we instructed P1 to select the pattern buttons and
Overall, P1, who is experienced with events and visualizations,found it relatively easy to use LoLo, scoring a five for ease of use and confidence, and a one for needing to learn a lot of things, see Supplemental material for all scores. P1 mentioned that this is a system for people with knowledge about data analysis, and even within that group, most will need a mini-course to learn it. P1 gave a score of three for learning this system quickly. P2 had more trouble interacting with LoLo and found it difficult. P2 gave a 3.5 for unnecessary complexity because P2 forgot which options existed and had trouble knowing what to do and when in this short usage period. Therefore, P2 gave a score of two for confidence and that people would learn it quickly. Also, P2 thought she needed to learn a lot to use LoLo, a score of four. Although, P2 still gave a four for easy to use. Also, P1 mentioned that some interactions could be improved and, therefore, gave a score of three for inconsistency in the system. P2 also mentioned that selecting stages is not so easy. Moreover, P1 gave a score of three for using the system frequently. P1 explained that LoLo possibly helps to give P1 insights, but if P1 wants to communicate this to partners and clients, which often happens, then P1 needs to translate the information into simpler plots. This was the biggest drawback of LoLo, according to P1. On the other hand, P1 liked the different levels of detail and the ability to rerun the data the most based on this short usage. P2 also liked the switching between different detail levels.
Use scenario neighborhood complaints data
We describe a usage scenario using complaints data from five neighborhoods in the city of Eindhoven. 7 We carry out this scenario, no users were involved. We want to discover high-level complaints patterns, when they occur, and if they reoccur over the year. A sequence is 1 year of data from one neighborhood and each neighborhood has 11 years of data. An event is a complaint. We have 55 sequences, each of length 8980 events. We aligned the data based on their timestamps: the first event of each week is aligned because we expect that time of year influences the occurring events. This results in 57% of the events being gaps. The events are categorical and have 15 possible main categories (including gaps). We gave the main categories an English name, for example, greenery or animal, representing the names of all its subcategories.
We initialize LoLo with the defaults; a stage parameter of 0.05, 100 minimum events, and 50 maximum deviation. Initially, we see two clusters, see Figure 10(a) white circles. After inspecting the normalized histograms of stages of each cluster, it is hard to identify the differences (T3) between the stages except for the gaps, see purple bars Figure 10(b). The proportion of these purple bars differs between the two clusters, but the other colors are hard to compare. Therefore, we rerun LoLo without the gaps (T1) because we want to know the high-level structure based on the event labels rather than being dominated by the gaps, see Figure 10(c) and (d). Now, several stage clusters (T2) and their transitions (T4) appear in the stage similarity plot, see Figure 10(c) white circle for an example cluster. Looking at the colors of the stage headers based on similarity, we see that there is a gradual yearly transition, Figure 10(d). The color of the headers changes from orange to blue to pink. Also, we run the staging again (T1) with a stage parameter of 0.1 because there are quite some similar stages with the same (grand)parent and similar header colors after each other, see the white boxes in Figure 10(d) white boxes. This is an indication that there might be too many stages. By changing the stage parameter to 0.1, the stages are merged into fewer stages. In the stage similarity plot, we can see that, for example, the last two stages, representing the last days of the year, start to transition from the previous stages, see Figure 10(e) white circle. In order to easily see this, the stage headers are colored in grayscale based on their temporal order. In this manner, LoLo helps us to

Snippets of LoLo with complaints data. With 50 stages (a), there are two clusters, that appear to differ mostly on the gaps (purple part of the bars), see (b). By rerunning LoLo such that it excludes gaps (resulting in 43 stages), we see less separated clusters as well as some transition clusters (white circle in (c)). A yearly pattern in the stage headers (d) is visible now. There are similar stages after each other that share a (grand)parent (white boxes in (d)). Reducing the Information Gain parameter further (another rerun of LoLo), results in 13 stages (e). Stages are colored by temporal order (dark to light gray) and the white circle is indicating the last two stages.
To identify the differences and similarities (T2) between the stages we used the normalized high-level bar charts, we filtered out categories that only contribute a small percentage to all the events and/or that stay approximately constant throughout the year. For example, during the summer period, that is, mid-May to the end of August, there are relatively more greenery and less lighting events than the rest of the year.
To find out more about the event order of the stages, we rerun the staging with the patterns for the global and local splitting (T1) and a stage parameter of 0.3. We see that one stage, S5, has by far more patterns than the other stages, mid of April until end of August. We see this by using the non-normalized high-level bar charts and looking at their height. To see the stage differences (T3), we look at their normalized high-level bar charts, see Figure 11. For example, the large stage has relatively many patterns with greenery events, brown, combined with animal, orange, see Figure 11 white rectangle. Although, the differences are not directly obvious, maybe because the unique patterns do not occur often in the entire data set; frequency is maximum 182. This explains why these stages are discovered.
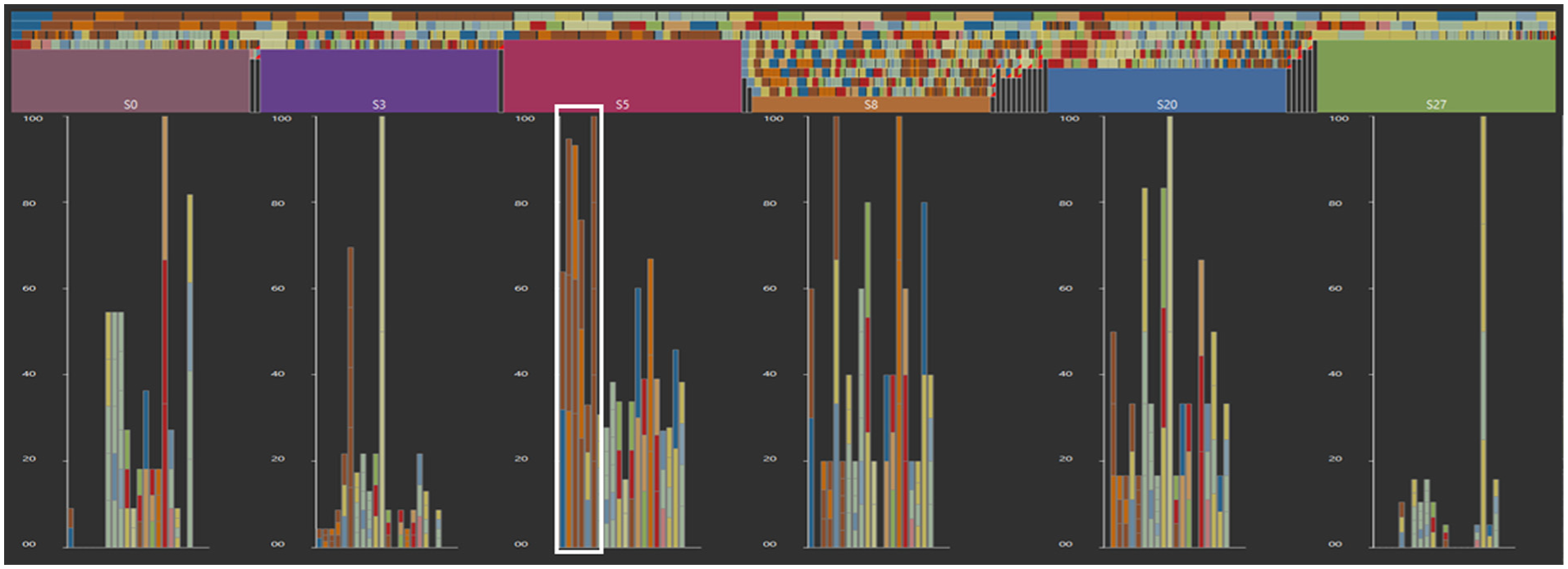
Normalized high-level from the complaints data, where the staging is based on patterns. Each bar represents a pattern, the color in the bar represents the events in the pattern from bottom to top. S5 has relatively many patterns containing greenery events, brown events, see the white box.
Discussion and conclusion
This paper presents LoLo, a novel visual analytics approach to discover, explore, and analyze high-level structures in long event sequences by discovering stages. These stages are of flexible time windows because they are created based on their content. These stages have four key concepts making them novel; they are
LoLo is not domain dependent. However, the similarities that define the stages might need to be adapted to specific domains. LoLo needs event sequence data that progresses as input. Otherwise, there is no high-level structure. Moreover, there are several considerations. We considered combining the event label and pattern splits, however, if we have a proposed split based on the event labels and the patterns, it is unclear how to combine these. We cannot just take the highest split score because their split scores represent different aspects. Also, it is unclear which event split to match with which pattern split. Therefore, users either determine the global stages on the event label or the pattern histograms, and can easily switch between the two. We also considered clustering sequences before any global splits are made, so the staging could be computed per cluster to optimize for homogeneous stages. However, for this a distance metric between sequences is needed, this is different from the IG distance metric to split sequences. The Levenshtein distance 38 is the most common distance measure to compute distances between two sequences. However, for long sequences, many insertions, deletions, and replacements are needed. After normalization, distances are too similar, resulting in a hierarchy where often only one sequence is added to the main cluster at each step. 39 Moreover, the computation time does not allow for interactivity. To the best of our knowledge, no other distance metric for sequences mitigates these shortcomings. We leave this for future work.
Also, LoLo currently cannot detect certain data constructs, such as concurrency or parallelism, between the different stages. By providing stages with summaries, the cognitive load is reduced because users get an overview and for selected stages of interest users get more detail. The adapted Icicle plot keeps the time-aspect of the stages and the hierarchy with the different levels of detail help to navigate to interesting data subsets while keeping track of the overall context. However, the horizontally stacked bar charts encoded in the hierarchy, see Figure 5(d), could be improved because this part looks busy. Different aggregation schemes, for example, visualizing the majority event, may offer solutions. Moreover, if sequences do not fit the screen-space vertically, users have to pan or zoom out to get all the sequences on the screen, which increases the cognitive load. By also compressing the sequence vertically, perhaps in a similar visual manner as Sequen-C, 3 LoLo could visually support scalability in the amount of sequences. These cognitive load reducing summaries could also omit potentially interesting relations. We currently use a simple aggregation scheme for the mid-level. Different aggregation schemes, such as mentioned in Sequence Surveyor, 40 could also be added. Furthermore, the parameter setting is influenced by the specific data characteristics and need to be tuned to get optimal results. Finding this optimum might not be trivial. However, it can be found through iterative interactive exploration.
There are several opportunities for future work. For example, a more formal, extensive user study will provide more insight to improve and validate LoLo. Also, it would be interesting to have additional interactions in the staging to, for example, redefine the stages arbitrarily. However, this would need quite some effort to coordinate with the stage generation. Additional interactions to promote comparison could be added as well, where users are able to extract and rearrange stages. A next logical step is to extend LoLo to multivariate sequence data, where the multivariate attributes are incorporated in the staging. Furthermore, the results are as good as the distance metric is able to capture the relevant information. Further research to alternatives would be useful, for example, Jaro-Winkler distance. 41 It would be interesting to improve computational times for, for example, the staging, as evaluated in “Computational” subsection, or the drawing of the elements on the screen. The field of progressive VA might provide inspiration. Moreover, the colors can be improved. Currently, the categorical colorscheme and the colormap make LoLo colorful with possibly similar colors, for example, both colorschemes have a shade of purple. All in all, LoLo enables users to identify insights in long sequences with a lot of events. LoLo helps potential users to identify the high-level structure in long event sequences by enabling them to interactively redefine hierarchically discovered stages which is superior to baseline fixed window stages or not understandable dynamic stages. Users have the ability to explore multiple aggregation levels for comparison between stages and within one stage. Through this method we aim to provide users with new perspectives on long event sequence data.
Supplemental Material
sj-pdf-1-ivi-10.1177_14738716251372584 – Supplemental material for Long sequences with a lot of events (LoLo): A visual analytics approach for analyzing long event sequences
Supplemental material, sj-pdf-1-ivi-10.1177_14738716251372584 for Long sequences with a lot of events (LoLo): A visual analytics approach for analyzing long event sequences by Sanne van der Linden, Bram Cappers, Anna Vilanova and Stef van den Elzen in Information Visualization
Footnotes
Acknowledgements
We thank the experts for their feedback. We also thank our university’s real estate department for the usage of the energy data set.

Funding
The authors received no financial support for the research, authorship, and/or publication of this article.
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Supplemental material
Supplemental Material for this article is available online.
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.