
Abstract
Keywords
Introduction
Structural health monitoring (SHM) is considered a consolidated asset in many industrial fields where predictive maintenance is desired. 1 A specific application consists of monitoring damage arising in composite structures, which are extensively adopted to obtain lighter components. In this context, the most suitable approaches rely on the use of ultrasonic-guided waves (UGW). These are a form of elastic waves that propagate in thin structures. Moreover, they are sensitive to any change in the waveguide or the structure that could be potentially overlooked during scheduled inspections. 2 The potential benefit of SHM deployment on these types of structures has already been assessed in different applications.3,4
A major challenge for the reliable operation of guided wave-based SHM systems is varying environmental and operational conditions, affecting wave propagation and altering damage detection capabilities. Varying temperature leads to amplitude and phase variations in the recorded ultrasonic signals. 5 A number of temperature compensation techniques have been developed in the literature including, for example, optimal baseline selection and baseline signal stretch, 6 principal component analysis, and singular value decomposition 7 as well as independent component analysis. 8 Furthermore, data-driven and model-based approaches for temperature compensation in UGW systems are proposed by Ren et al. 9 and a methodology based on a continuous baseline update is reported in Maack et al. 10 Likewise, loads on the structure cause deformation and stress, affecting the propagation of guided waves.11,12 The acoustoelastic effect has been discussed for uniaxial tensile loading in metallic plates which showed a general increase in wave velocity with loads yet depending on the frequency. 13 The effect gets complicated by multi-axial loading, introducing anisotropic behavior in isotropic material. 14 This effect is exacerbated when dealing with complex composite structures under multi-axial loading, with a direct effect on wave amplitude too. 15 Although commonly used damage indexes can be implemented under varying environmental and operative conditions,7,15 they are strongly connected to the specific use case and lack generality. 16
More recently, machine learning (ML) approaches have been explored thanks to their ability to find underlying patterns in data. This is particularly advantageous when environmental and operative conditions vary. In Abbassi et al.,
17
two damage detection and localization strategies under temperature variations were implemented: one involved reducing dimensions and creating score plots, while the second relied on calculating
In this paper, we present a combination of supervised and unsupervised ML approaches illustrated in Figure 1. In particular, all the approaches have been tested and compared on the open-guided waves (OGW) dataset under varying temperature conditions, before validating the third approach on a dataset from an experimental campaign carried out on a composite overwrapped pressure vessel used for hydrogen storage under varying load condition and damaged with actual defects. The main contributions of this study are as follows:
The implementation of a combination of strategies for damage detection in composite structures under temperature or load variations, exploring supervised learning algorithms: ridge regression classifier (RRC) and convolutional neural networks (CNNs), along with an unsupervised learning approach called local outlier factor (LOF).
Two different strategies for time series transformation are proposed for subsequent input to ML classification algorithms, namely Gramian angular field (GAF) and Minimally Random convolutional kernel transform (MiniRocket). The latter offers a reliable, time- and hardware-efficient option for feature extraction, applied for the first time in SHM with UGW.
The application of the combination of the previous two items, along with the ensemble voting strategy, takes full advantage of the ultrasonic sensor networks to provide a collective prediction.
Finally, the method successfully detects damage at previously unknown locations, even under varying environmental and operational conditions, addressing the specific challenges associated with complex scenarios that are often overlooked in supervised ML approaches.

Data processing pipeline for supervised and unsupervised ML.
Related works
Machine learning methods
ML methods are commonly categorized into supervised learning and unsupervised learning:
Supervised learning algorithms have been extensively used in signal classification, such as image and audio classification. According to Bansal and Garg, 22 deep neural networks have excelled in this domain with the highest accuracy attained by a CNN. A CNN is a so-called deep learning algorithm, which refers to the use of multiple layers within a neural network, which extract features from the data allowing for the learning of complex patterns and representations. A typical CNN architecture alternates between convolutional layers and pooling layers, which synthesize the information obtained from the convolutional process. This combination of both layers can be utilized to process large volumes of data for classification and to generate complex predictions also in the SHM context. 23
Regression algorithms are also supervised methods used in SHM. Regression algorithms are generally used to build models consisting of continuous variables using only available data. 24 The RRC, also known as Tikhonov regularization, belongs to this category. Methods such as polynomial regression and standard least squares are prone to overfitting and can quickly handle high polynomial coefficient values, particularly in the case of polynomial regression. Overfitting occurs when a model captures noise in the training data rather than the underlying pattern, leading to poor performance on unseen data. To overcome this problem, RRC includes a regularization or cost term; this approach, controlled by the defined regularization parameter, penalizes fits with large coefficients, allowing for a balance between the model’s fit to the given data and its complexity.
While supervised learning algorithms are predominantly used, unsupervised or clustering methods can be advantageous for anomaly or damage detection. The LOF is one such algorithm; it evaluates whether an element within a given multidimensional dataset belongs to a defined “norm.” This classification relies on the distance between each element in the entire dataset. When the distance between most elements is short, this group of elements is seen as a high-density cluster by the algorithm and is interpreted as the norm, while any element located far away from this cluster is classified as an outlier or anomaly. 25
Time series classification
The UGW used for damage detection in SHM is recorded as time series data, which refers to a sequence of data points collected at successive points in time as the one displayed in Figure 4. The recorded data are essential for tracking changes and structural variations over time. Analyzing, labeling, and categorizing this data are the core tasks of Time series classification. Nevertheless, a critical aspect of TSC is feature extraction, which involves deriving relevant features from the time series to enhance the classification process. This step is vital, as it enables the identification of key time-dependent characteristics and properties that significantly influence the classification outcomes of ML algorithms, such as those presented previously. Unfortunately, time series feature extraction 26 and future value prediction in time series 27 are processes that are both complex and time-consuming. Ultimately, effective feature extraction not only facilitates the application of ML algorithms but also improves the accuracy and reliability of the classification results.
Experimental data acquisition and generation of datasets
This section briefly introduces the datasets adopted for validation of the methodology proposed in the study. The first dataset is taken from the study of temperature effects published on the OGW website. 7 The second dataset is taken from an experimental campaign carried out on a composite overwrapped pressure vessel (COPV) for hydrogen storage. The experimental setups are described first, followed by an explanation of how environmental and damage conditions were varied to create the datasets.
First experimental setup (OGW)
The first experimental setup consists of a carbon fiber reinforced polymer (CFRP) plate made of Hexply® M21/34%/UD134/T700/300 carbon pre-impregnated fibers. The plate is 500 × 500 mm in size with a thickness of 2 mm and a quasi-isotropic layup with a stacking sequence of [45/0/−45/90/−45/0/45/90]S. The plate is equipped with 12 DuraAct transducers employed to establish a network of actuators and receivers. The signals are generated with a Handyscope HS5 from TiePie Engineering and recorded using analog-to-digital conversion at a resolution of 14 bits. The excitation signals are amplified with a PD200 broadband amplifier from PiezoDrive Ltd. (Shortland, NSW Australia) and forward to a custom multiplexer to automatically sort among the actuator and the receivers in a round-robin fashion. The surface temperature of the plate is recorded by two temperature probes. Round aluminum disks are attached with tacky tape at different locations to simulate damage in a reversible way. From a larger number of potential locations for the damage, four points lying on a line were selected. These positions, labeled

Sketch of the plate along with transducer and damage positions. Among the possible damage locations,
7
To generate the first dataset, an interrogation signal consisting of a 5-cycle Hann-filtered sine wave is amplified to
Second experimental setup (COPV)
The second experimental setup consists of a Type IV COPV manufactured by NPROXX, with the reference AH350-70-4 (see Figure 3(a)). The vessel consists of a polyamide liner and a carbon fiber overwrap. It is designed to withstand an internal pressure of up to 700 bar. Moreover, it has an axial length of 1670 mm and an outer diameter of 352 mm. The vessel is instrumented with a network of ultrasonic sensors for testing and data acquisition. These sensors are piezoelectric DuraAct patch transducers (P 876K025), each incorporating a 10 mm circular ceramic element embedded within a ductile polymer manufactured by PI Ceramics. The sensors are mounted onto the vessel’s surface using a commercial epoxy adhesive. A total of 25 sensors are deployed, comprising five rings of five elements each. They have a spacing between them of 221 mm in the circumferential direction and 312.5 mm in the axial direction. Signal acquisition and excitation are conducted using a Vantage 64 LF system from Verasonics, which is wired to the sensor array to generate and capture the ultrasonic signals. To achieve the required internal pressurization, the specimen is mounted into a high-pressure system (PN20) provided by Maximator GmbH (Nordhausen, Germany). This hydraulic system operates with glycol as the pressurizing medium.

Measurement setup: (a) photograph of the pressure vessel mounted into the high-pressure system, and (b) layout of the artificial damage
To generate the second dataset, the pitch-catch approach is still employed, enabling a comprehensive data collection process across the entire sensor network. To ensure consistent measurements, the entire inspection cycle is performed three times for each excitation frequency, varying in the range [60, 120, 180, 240, 300] kHz. The sequential excitation and data collection processes are programmed into the computer operating the Vantage System. Each dataset or measurement was recorded at specific pressure levels using a programmed trigger. The trigger was held for 3 min before releasing to minimize transient effects after pressurizing the vessel. Each pressure level was maintained for 6 min. The pressure cycle followed this sequence: starting at 20 bar, it increased to 50 bar, then pressurized the vessel in 50 bar increments up to a maximum of 700 bar. The pressurization cycle is repeated twice.
Three types of damage were used at different locations as shown in Figure 3(b): artificial (reversible) damage created by gluing aluminum metal blocks onto the vessel’s surface
Influence of temperature and load on UGW signals
Figure 4 shows a complete signal for three different temperatures. In the first 300 µs, they do not yet differ, which is an indication of electromagnetic crosstalk. As the graph continues, a slight phase shift to the right can be seen for increasing temperatures in the orange and green curves. This decrease in group velocity and increase in Time of Flight (TOF) is in line with expectations. Furthermore, a shrinking of the amplitudes can be observed, which is also consistent with the findings from the literature.

Varying temperature. In the magnified part of the plot, the phase shift to the right and attenuation of the amplitude can clearly be seen for higher temperatures.
The influence of a mounted aluminum disk on the UGW can be seen in Figure 5. After the electromagnetic crosstalk, which is identical in both cases, there is a slight attenuation of the amplitudes compared to the baseline. However, the effect is only small compared to the one caused by larger temperature changes. There is no noticeable phase shift. While increases in temperature lead to a phase shift to the right, the opposite can be observed with an increase in pressure.
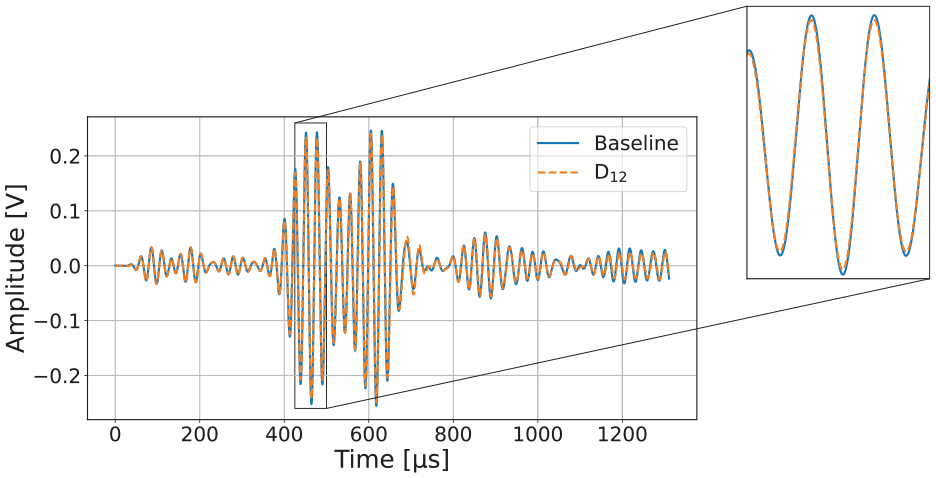
Comparison of a baseline measurement with a signal recorded when damage was applied (
Figure 7 shows the difference between a baseline signal and one with a hole in the surface between the actuator and sensor. After the electromagnetic crosstalk, which is again identical in both cases, an attenuation can be recognized in the event of damage.
A very small phase shift to the right only appears in some time ranges. Through analysis of the previously presented signals (Figures 4–7) and comparisons with various additional signals, we can conclude that variations in temperature and load have a greater impact on guided waves than damage does.

Varying pressure. In the magnified part of the plot, a phase shift to the left can be detected for higher pressures.

Comparison of a baseline measurement with a signal recorded after the first hole was drilled
Methodology
In this section, the methods developed in this work are introduced. A brief overview of the metrics relevant to the following sections is provided at the beginning. Afterward, two different ways of converting the measured signals into representations that serve as input for the utilized classification algorithms are presented. These include the GAF, which generates an image-like matrix, as well as the features calculated by a time series feature extraction method called MiniRocket. 28
The two classification models belonging to the field of supervised learning – CNN and RRC – are shown next. While the GAFs are interpreted by a CNN, a comparatively simpler RRC uses MiniRocket features.
This is followed by a description of the anomaly detection algorithm called LOF, which is an unsupervised learning method that does not require signals from a damaged structure for training.
Lastly, it is explained how ensemble voting combines the predictions of individual actuator-sensor pairs. This approach makes it possible to obtain a collective prediction for the entire system and significantly improves the accuracy compared to the individual predictions. The procedure for an optimal choice of the decision threshold, which is used to distinguish between
Metrics
For classification tasks in ML, there are a few particularly important metrics that appear at various stages. These are relevant both for training when optimizing the hyperparameters and selecting the decision threshold as well as for evaluating the performance of the models when used on test data.
A common method for measuring the performance of a classifier and analyzing the kinds of errors it makes is the so-called confusion matrix. It is shown for two classes in Figure 8:

Confusion matrix for two categories.
Accuracy refers to the proportion of correct predictions out of all predictions. The precision value describes the ratio of correct positive predictions to all positive predictions. Also known as sensitivity or true-positive rate (TPR), recall is calculated as the percentage of positive instances that are correctly classified. The previous two metrics can be combined using the harmonic mean into a single metric called




The so-called receiver operating characteristic (ROC) shows the relationship between the TPR (equivalent to recall) and the false-positive rate (FPR). As with precision and recall, one of the two metrics generally gets worse when the other gets better. A simple way to assess the performance of a classifier is the area under the curve (AUC), which is 0.5 for a random classifier and 1.0 for a perfect one.

Data preprocessing
Depending on the choice of the classification model, the data must be prepared in different ways. The two approaches used for data pre-processing in this work are GAF and MiniRocket.
Gramian angular field
Previous research of this paper’s authors successfully investigated transforming UGW into mel-frequency cepstral coefficients matrices, a compressed form of a spectrogram retaining information about time and frequency, for detecting damage and estimating its size and location.29–31 One of the aims of this work was to find further forms of image-like matrices for the utilization of a CNN. While previous approaches focused on a dataset of OGW without environmental influences, this study’s classification tasks take temperature fluctuations into account.
In initial tests on this dataset, GAF achieved more promising results than recurrence plots and Markov transition fields (MTF). An overview of the different approaches with imaging methods in TSC, in general, can be found in Ismail Fawaz et al., 32 a recent application of GAFs specifically in the field of SHM in Liao et al. 33
GAFs (and MTFs) were proposed in 2015 by Zhiguang Wang and Tim Oates as a new method for encoding time series as images.34,35 These are described using polar coordinates as a Gramian matrix whose elements represent the trigonometric sum of different time intervals.
First, the time series


Next, the transformation into polar coordinates is done by encoding the value as the angular cosine and the time stamp as the radius.

Here,




In the last step,
An implementation of the algorithm for generating the GADF and GASF matrices is available in the Python package pyts.
36
The parameters used in this work can be found in the section “Results.”Figure 9 shows an example of how a signal from the OGW dataset is transformed into GAF matrices of size

After normalization of a signal from OGW, the transformation into polar coordinates follows. The GASF and GADF matrices are reduced to the size
MiniRocket
MiniRocket was recently introduced by Dempster et al. 28 It is an almost deterministic variant of Rocket and up to 75 times faster for large datasets than its already comparatively quick predecessor. Thanks to these improvements, there is currently no TSC algorithm that has such low computational cost with the same level of accuracy.
In a nutshell, MiniRocket works as follows: By default, 10,000 kernel-dilation-bias combinations are used to perform convolutions with a time signal. This is followed by the calculation of the proportion of positive values (PPV), a type of pooling for dimensionality reduction. These values between 0 and 1 form the features that are then used to train a linear classifier. For datasets with fewer than 10,000 time series, the authors recommend an RRC, for larger datasets a logistic regressor. However, in the section “Results,” it is shown that these features can also be successfully used for other models, in particular for an anomaly detection algorithm, which is introduced in the section “Local outlier factor.”
The application of a kernel

Specifically, in the context of guided waves,
Only the PPV is then of relevance for MiniRocket.

An implementation of the algorithm is available in the Python package sktime. 37
Classifiers
The following section presents three approaches for using features derived from measured signals in classification. The first is the RRC, which takes the MiniRocket features as input. Next is the CNN, which is trained with GAF matrices. These two methods are supervised learning techniques, utilizing labeled data for training. The third approach is the LOF, an unsupervised learning technique that does not require labeled data. Again, MiniRocket features are used as input.
Ridge regression classifier
Linear models are characterized by the fact that they make predictions using a weighted sum of the input features plus a constant called the bias term or intercept term. The notation is based on Géron 38

Here,

During the training of the model, its parameters are set to predict training set values as accurately as possible, typically measured using the root mean square error (MSE). In practice, however, the MSE is used instead, which leads to the same minimum, as the root function is monotonically increasing.
Regularization methods like ridge regression, also known as Tikhonov regularization, can be used to prevent overfitting by adding a regularization term to the cost function

The strength of the regularization depends on the hyperparameter
While regression is normally applied to predict continuous values, it can also be used for classification with scikit-learn’s
Convolutional neural network
The CNN used here was the so-called EfficientNetV2,
39
which was chosen for its impressive balance of size and performance. As a small model, it offers the advantages of minimizing hardware requirements, reducing training time and lowering the risk of overfitting due to limited training data. While a small CNN (about 640,000 parameters) inspired by Géron
38
was successfully utilized in previous work,29–31 initial tests proved this simple architecture to be insufficient for the more complex task involving environmental influences. Instead, the smallest variant (about 6 million parameters) of EfficientNetV2 was selected for this task. Specifically,
The training of the network, initialized with random weights, was run on a T4 GPU on the cloud-based service Google Colab. Within 750 epochs, the loss function categorical cross-entropy was minimized with the Adam optimizer and the learning rate scheduler cosine decay. Details on hyperparameters and pre-processing of input data can be found in the section “Results.”
Local outlier factor
In a realistic SHM scenario, the damage can vary in size, severity, and number, but there is only one undamaged state (apart from environmental influences). In this situation, it is necessary to determine whether a new input belongs to the same distribution of known observations (
In outlier detection, the training data are contaminated with a few outliers located in regions of low density that are to be found. Novelty detection, on the other hand, assumes that all data from the training set belong to the same class. If a new observation is labeled as an outlier, it is referred to as a novelty. In the context of damage detection, novelty detection is particularly interesting, as only undamaged signals are needed for training. This provides an important reduction in hardware requirements and experimental effort. However, outlier signals are still required to evaluate model performance.
For this work, the scikit-learn implementation of LOF 25 was selected for anomaly detection. LOF measures the extent to which the object under consideration can be described as an outlier. For objects deep in a cluster, the LOF value is approximately 1, as the densities of an object are comparable to those of its neighbors. Values significantly greater than 1, which indicate an outlier, are caused by the low densities of the object under consideration and the high densities of its neighbors. Very high values are therefore achieved when a single object is located far away from a cluster of high density.
An example with synthetic data for illustration of the method is shown in Figure 10. Three isotropic Gaussian clusters were created for part (a) of the figure using scikit-learn’s

Exemplary use of LOF on a synthetic dataset: (a) synthetic dataset. In addition to three clusters, 20 random points were inserted and (b) points marked with blue circles were identified as inliers by the LOF algorithm, red circles show outliers.
Collective predictions
In the previous sections, all the methods necessary for classification were presented. The next step is combining predictions from individual transducer pairs to significantly improve accuracy and provide a single prediction for the overall state of the test object, rather than just for a part of it.
Ensemble voting
The first part of the approach is simple to implement and is summarized in Figure 11. After choosing one of the three methods (CNN, RRC, and LOF), a model is trained for each of the 36 transducer pairs. Each model now predicts each new signal, outputting either 0 (

Flowchart illustrating ensemble voting.
Decision threshold
To determine a customized decision threshold, a sufficiently large dataset is necessary, as cross-validation requires signals of different labels and positions. However, cross-validation was not performed for the LOF algorithm, as this would have been contrary to the basic idea of using only baselines for training. Nonetheless, the same methodology could theoretically also be applied to LOF.
The process consists of several steps, summarized in Figure 12. First, a part of the dataset (the test set) is set aside to evaluate the method later. It is crucial for a realistic assessment of the model’s performance that the test data are not used for training or for optimizing any parameters. Here, the data for one of the four damage locations and a subset of the baselines were withheld.

Flowchart for determining the ideal decision threshold for a given dataset.
Cross-validation follows as the second step. For this purpose, the main dataset (training–validation set) is divided into several segments. Two of the remaining three positions are used for training (training set), and the third position is for validation (validation set). This is done for all possible splits into training and validation sets, which in this case were three different ones.
Afterward, the training set is used to adjust the model weights and the validation set is used for the evaluation. Several metrics are calculated for the entire range of possible threshold values. The aim is to select the threshold value at which the
All of the previous steps were designed to find a suitable threshold value that hopefully works well for unknown data and especially signals of new damage locations. To examine this, the performance of a model trained on the entire training-validation set is now assessed on the test set that was retained for this purpose. This is accomplished by applying the threshold found with cross-validation and assigning one of the two possible labels to the averaged predictions for each signal of the test set.
Results
Results for temperature or load varying datasets are reported here. For the former case, the three approaches are tested and compared. In the latter case, the third approach is validated on a realistic damage scenario.
Temperature-varying dataset
The first step was to optimize the most important settings for GAF and CNN through a hyperparameter search, which was carried out using only one transducer pair due to time constraints. For the paths (4–10) located in the middle of the CFRP plate, the validation accuracy was to be maximized. In doing so, it was important to include signals from other damaged locations in the validation set as otherwise achieving 100% accuracy would have been far too easy. In fact, even without optimized parameters, perfect metrics were obtained when the training and validation set differed only in temperature or measurement repetition number, but not in position. This suggests that the real challenge lies in detecting damage at previously unknown locations—a factor not always considered in the literature, though important for a performance assessment under more realistic conditions.
The hyperparameters search was performed with the optimization framework optuna.
41
With its efficient
Hyperparameter optimization results for GAF + CNN.

GAF: Gramian angular field; CNN: convolutional neural network.
Figure 13 shows the accuracy, precision, recall, and

Evaluation of predictions by the CNN for individual transducer pairs.
With the exception of (3–10), where no damage was detected and the precision is undefined, precision values for all channels are 100% or very slightly below. Therefore, if a CNN predicts damage, the test object is actually damaged. This property is crucial for the success of the ensemble voting. The recall plot shows that while two channels recognized almost all damages, two others detected almost none. Finally, the
The results shown so far were for individual CNNs. Now, the combination of their predictions is analyzed. After all, the aim is to generate an overall prediction of all trained classifiers.
Before the execution of ensemble voting, the optimal decision threshold must first be found. For this purpose, cross-validation was performed with various splits. Their individual metrics are not listed here, as only the optimized threshold is of interest.
Figure 14 illustrates the determination of the best threshold using one of the three cross-validation splits. In this example, training included positions

For the validation set, a decision threshold value of 0.083 maximizes the
The metrics reach their minimum at a threshold above 0.5 or are undefined in the case of precision. The vertical dotted line indicates the center of the section in which the
Figure 15 then shows the metrics for the test set. Compared to the previous plot, all metrics are now significantly better for the majority of possible threshold values. This is probably due to the fact that the entire training-validation set was used for training, giving the CNNs more examples to learn to distinguish between

Various metrics versus threshold for the test set using the CNN approach.
For the second method, MiniRocket transformed the signals and an RRC classified them. The procedure was similar to the previous one but with 36 transducer pairs and a broader range of scenarios. First, however, the hyperparameters to be set are briefly discussed.
MiniRocket’s hyperparameter search is straightforward, as only the number of kernels (

Optimization of the
The criterion for a suitable value of the
Aside from
In direct comparison to the CNN, the scores for the channels used in both methods are slightly higher on average for the RRC. More important, however, is the performance of the ensemble, which is shown in Figure 17 for

Various metrics versus threshold for damage location
This anomaly detection approach aimed to use only baselines for the training data. The first three-quarters of all baselines were included in the training set, while the last quarter and the data for the CFRP plate damaged at one position formed the test set. This procedure was followed for all four damaged positions, resulting in four test sets. As done by Dempster et al. 27 and Tu et al., 43 where unsupervised learning methods were also used for SHM, AUC was selected as the key metric for the evaluation of the model.
First, the hyperparameters were optimized utilizing the
Hyperparameter optimization results for MiniRocket + LOF using the OGW dataset.

OGW: open-guided waves; LOF: local outlier factor.
Figure 18 illustrates the AUC values for

AUC for detecting damage at position
The threshold plots in Figure 19 look slightly different than before due to LOF returning either −1 or 1 as a prediction. While 1 means

Various metrics versus threshold for damage location
Lastly, Table 3 presents the compiled results for the three methods. For GAF + CNN and MiniRocket + RRC (MR + RRC), both the average accuracies across all transducer pairs and the ensemble accuracies are reported. For MiniRocket + LOF (MR + LOF), the AUC values are displayed to represent the method’s performance. Regardless of the damage location selected, the ensembles of all three methods reliably distinguished between the two classes for nearly all signals and temperatures. Given that UGW signals contain multi-modal dispersive waveforms with reflections—such as those from structural boundaries—along with signal changes resulting from temperature and load variations, this unpredictable behavior limits the applicability of ML methods when considering new transducer pairs that were not included in the training phase (Table 3).
Results of all methods.

GAF: Gramian angular field; CNN: convolutional neural network; MR: MiniRocket; RRC: ridge regression classifier; LOF: local outlier factor; AUC: area under the curve.
Load-varying dataset
Addressing real-world situations, we found that the application of supervised ML approaches was not feasible, as the vessel could only be destroyed once. Therefore, this study explores the applicability of unsupervised methods in this practical scenario. First, the hyperparameters are optimized to maximize the average AUC value across 15 transducer pairs considered for the analysis (paths having either transducer #6 or transducer #16 enabled). During the hyperparameter optimization, the first half of the baselines (i.e., the three repetitions of the first pressure ramp, corresponding to a total of 42 signals per transducer pair) was used for training, the second half of the baselines and the data for
Hyperparameter optimization results.

The results after the application of the ensemble voting process are summarized as ROC curves in Figure 20. For

ROC curves and AUC values when applying the method to ideal and real damage.
Discussion
Comparison between supervised learning methods
The first two methods are fundamentally similar in their application, which simplifies comparison. Both require labeled data from both undamaged and damaged test objects for training and classify transformed signals into one of two categories. The primary objective of this study is to develop a robust ML model (supervised, unsupervised) for detecting damage to structures under varying environmental and operational conditions, specifically temperature and load. Beyond the slightly higher classification accuracy for individual transducer pairs, several other advantages favor MiniRocket + RRC. The most obvious is the significantly shorter training time for MiniRocket—only a few seconds per transducer pair compared to around 15 min for the CNN. This makes it possible to consider significantly more channels, which generally leads to more reliable classifications, as it allows for better coverage of the monitored object’s surface. Moreover, malfunctions of single transducers are less problematic since neighboring transducers still observe similar segments. Another advantage is the lower hardware requirements for the RRC compared to the CNN, which needs a GPU for efficient training, whereas a CPU is sufficient for the RRC. In addition, the reproducibility of the results of the MiniRocket + RRC method helps in comparing different approaches. The simpler hyperparameter optimization, in which only the number of convolutional kernels needs to be varied, is also worth mentioning. Finally, MiniRocket and in particular sktime’s
In its current form, the verdict is therefore clearly in favor of MiniRocket + RRC. However, the number of possible variations of the CNN approach is so large that it should not yet be ultimately dismissed.
Supervised versus unsupervised learning approaches
After ensemble voting, the supervised learning approach almost always achieved perfect results, thanks to excellent precision values from individual transducer pairs and the ability to optimize decision thresholds using data from various damage locations. Another advantage of this approach is the large number of classifiers for which there are already implementations that can potentially be tested in the future.
However, signals from structural damage at various positions are needed for a robust classifier with optimized hyperparameters and thresholds. Besides reversible damages like the aluminum disk attached to the CFRP plate for OGW, simulated damages could be an alternative to obtain a sufficiently large training set.
The unsupervised learning algorithm LOF is as easy to implement and fast as the RRC method. It also offers the major advantage of not requiring damaged object signals for training, greatly reducing the experimental workload. By distinguishing between
However, there are also downsides such as how to interpret the results when no threshold is determined beforehand. One option is to check anomaly scores of new or retained baselines, classifying anything below the lowest value for the undamaged object as outliers. Alternatively, a threshold simply set at 0.0 would have achieved very good results for this dataset. While real damages would probably be more appropriate for determining a decision threshold, this would to some extent contradict the original goal of using only baselines for training and still require actual damages to assess realistic performance.
Considering the strong performance of the individual classifiers, the wide ranges for threshold values, with which (almost) perfect metrics are achieved, as well as the potential for damage localization, especially considering the anomaly score, there are many arguments for continuing research with the LOF approach. In future work, we will consider experimental signals corresponding to specific temperature ranges, designated as test data to facilitate an unbiased evaluation of the model’s performance. The ML models will be trained on data collected from conditions that do not include these observations from the specified test temperature and load ranges. This methodology is intended to assess the models’ generalizability and performance under previously untested environmental and operational conditions. Furthermore, we plan to broaden the range of environmental conditions by conducting new measurements over a pressure vessel that will test the performance of the studied ML models across a spectrum of simultaneous temperature and load variations which will further validate the models’ generalizability and robustness.
Conclusion
The paper demonstrated the performance of supervised and unsupervised ML methods in the context of damage detection in the presence of temperature or load variations, resembling the operational conditions of the specimens. The main results of this work can be summarized as follows:
The supervised learning algorithms RRC and CNN were implemented and tested alongside the unsupervised learning algorithm LOF to successfully identify damage in a CFRP plate under varying temperature or load conditions.
Both time series transformation methods, GAF and MiniRocket, provided suitable and valuable features for the ML models, accurately reflecting the state of the structure. MiniRocket, which was applied for the first time in the context of SHM with UGW, combined with RRC or LOF, proved to be the most time-efficient approach used in this study.
Ensemble Voting significantly improved the reliability of damage detection by combining predictions from multiple transducer pairs. Even with a limited number of strong individual classifiers, 100% accuracy was achieved in most cases.
The combined approach of MiniRocket, supervised/unsupervised ML algorithms, and ensemble voting proved to be an effective, hardware- and time-efficient strategy for detecting damage in the composite structure. This approach successfully overcame the challenges introduced by temperature or load variations, even in locations not included in the training of the ML models.