
Abstract
Keywords
Introduction
The term cyber-physical systems (CPSs) refers to a new generation of systems with integrated computational and physical capabilities that can interact with humans through many new modalities. Figure 1 shows the feature of CPS. To realize the automatic flow of data, there are four steps: state perception, real-time analysis, scientific decision-making, and precise execution. A large number of implicit data contained in physical space are transformed into explicit data through state perception, and then can be analyzed by a computational method in information space, and the explicit data can be transformed into valuable information. The information of different systems is processed centrally to form scientific decision-making of external changes, which further transforms information into knowledge. Finally, the more optimized data are applied to the physical space to form a closed-loop flow of data.

The feature of CPS.
Figure 2 shows a CPS application scenario. In CPSs, computational and communication cores, governed by cyber processes, interact with physical-domain sensors and actuators. This interaction opens up possibilities for unique vulnerabilities 1 posing serious challenges to the system security. For example, as the information flow in the cyber-domain manifests physically in the form of energy flows in the physical domain, it may be leaked. These energy flows may be observed in the form of various analog emissions such as vibration, acoustic, magnetic, and power.

CPS application scenario.
These mediums, through which unintentional leakage of information occurs, are also known as side channels. Side channels pose a serious threat to the confidentiality of the system as they may indirectly reveal the cyber-domain data. Side-channel attacks2,3 have shown to be extremely effective as a practical means for attacking implementations of cryptographic algorithms. Adversaries can obtain sensitive information from side channels such as timing of operations, 2 power consumption, 3 and electromagnetic emanations.4–6 They are used to break the cryptographic protocols, where attackers, rather than using brute force or attacking theoretical weakness of the algorithms, use side channels to infer about the various system states in the cyber domain. Since Paul Kocher’s original paper, 3 a number of devastating attacks, such as simple power analysis (SPA), differential power analysis (DPA),3,7,8 and correlation power analysis (CPA),9–11 have been reported on a wide variety of cryptographic implementations.12–16
Template attack (TA) was first proposed by Chari et al. 17 in Conference on Cryptographic Hardware and Embedded Systems 2002 (CHES2002). Since then, it has been widely used by many scholars in side-channel attack technology. The basic idea is to establish noise templates for specific information leaked during cryptographic algorithms. Noise templates reflect the energy consumption characteristics of leaked information and are used to identify information leaked by attack traces. TAs 17 consist of two phases. The first phase is the profiling phase, and the second phase is the extraction phase. In the profiling phase, one captures some actual power traces from a reference device identical or similar to the targeted device and builds templates for each key-dependent operation with the actual power traces. In the extraction phase, one can exploit a small number of actual power traces measured from the targeted device and the templates obtained from the profiling phase to classify the correct (sub) key. However, a key requirement for the TA 17 is that the adversary has an identical experimental device which can be programmed. By changing the secret key of the experimental device, the adversary can cross compare the power consumption measured in the encrypting process with different secret keys and find possible positions of information leakage on power traces. These positions are called points of interest (POIs). 17 The knowledge18,19 of POIs allows the adversary to profile the power distribution of specific operations (usually by multivariate Gaussian model) and build the corresponding templates for extracting the secret key of a new device. Up to now, many different methods of choosing interesting points were analyzed in the literature. They are difference of means (DOM)-based method, 17 , sum of squared differences (SOSD)-based method, 20 CPA-based method, 21 sum of squared pairwise T-differences (SOST)-based method, 20 signal-to-noise ratio (SNR)-based method, 21 variance (VAR)-based method, 22 mutual information analysis (MIA)-based method, 23 and principal component analysis (PCA)-based method. 24
The limitation of TA is that the adversary should obtain full control of an identical experimental device, which usually means arbitrarily changing the secret key of the experimental device; this limitation has been relaxed to knowing only three keys of similar devices by the method proposed in the study by Lerman et al. 25 and has been further relaxed to only requiring one secret key of an identical device by the concept of equal images under different subkeys (EIS) proposed in the studies by Gierlichs et al. 20 and Schindler et al. 26 EIS property states that the domain of the intermediate value of an operation is always the same whether or not the plaintext and subkeys involved in the operation are random or not. Under the assumption of EIS, an adversary can profile a type of device with only one secret key. Wu et al. 27 have proposed a method of TA based on clustering, which can accurately fit the leaked information probability model even one secret key cannot be required, and the location of information leakage can be determined. But this method to locate the POIs is not straightforward.
As mentioned earlier, POIs are the basis of building templates in TA. How to choose the POIs correctly is significantly important. Our contributions are the following three points:
Sometimes adversary cannot locate the positions of SBOX input and output straightforwardly, a new MPR method for finding POIs correctly is proposed.
A method for establishing templates on the basis of those POIs still without requiring knowledge of the key is proposed. Several techniques are proposed to improve the quality of the templates as well.
A method for choosing attacking traces is proposed to significantly improve the attacking efficiency.
In this article, related works are introduced in section “Related works.” Then, a novel TA method is proposed. How to find POIs correctly? How to build templates effectively? How to extract the correct key? These three questions are answered in section “Novel TA on SM4.” In order to verify the novel method, experiments are shown in section “Verification and comparison.” Finally, the conclusion is drawn.
Related works
In this section, we briefly review the different methods of choosing interesting points, TAs and the block cipher algorithm SM4.
The methods of choosing interesting points
As mentioned earlier, many different methods of choosing interesting points were analyzed. They are DOM, SOSD, SOST, and PCA.
Captured traces normally consist of too many samples, usually to the magnitude of 105. Most of these samples are irrelevant to the targeted information leakage of

where
The SOSD method was proposed to improve the quality of selecting POIs in the study by Gierlichs et al. 20

where
The SOST method is based on the

where
PCA has also been applied as a dimension reduction technique in TA. 24 In practice, the effect of applying PCA is limited because the principal dimensions contain a large proportion of VAR on locations irrelevant to the targeted operation. PCA is practical only when applied to a large number of POIs (e.g. thousands) that are selected on the basis of SOSD or SOST. 20
TA
TA consists of two phases. The first phase is the profiling phase, and the second phase is the extraction phase.
Profiling phase
In the profiling phase, traces are grouped on the basis of the intermediate values produced by the targeted operations in the encryption process. These groups of traces will be used to build the templates, which are usually modeled with multivariate Gaussian distribution representing the mean power consumption and the characteristic of Gaussian noise of the leaked information. Suppose the trace group of operation

where
Extraction phase
After the templates are built, one or a few traces will be used to extract the secret key on the basis of their probabilities determined by the templates

where
SM4 algorithm
SM4 algorithm is a block cipher algorithm, formerly known as SMS4 algorithm, which is the first official commercial cryptographic algorithm of China. Figure 3 presents the framework of round function of SM4. The plaintext, ciphertext, and key of SM4 are all 128 bits. There are 32 rounds for SM4, and the key of each round is 32 bits. The S-box of SM4 has eight inputs and eight outputs. Actually, the SM4 algorithm is similar to AES-128. Both algorithms are Rijndael structures.

Framework round function in the SM4 cryptographic algorithm.
Novel TA on SM4
With the promulgation of the SM4 algorithm in 2006, in recent years, domestic scholars began to pay attention to the security of the SM4 algorithm in the side-channel direction.
Various attack methods against the SM4 algorithm were proposed in previous studies28–32 from power analysis attack, including SPA attack, DPA attack, and CPA attack. Some TA methods on the SM4 algorithm were proposed by Zhang 33 and Ma and Ding. 34 These methods are based on traditional TAs.
In this section, a novel TA method is proposed. As introduced earlier, TA has two phases: profiling phase and extraction phase. In the profiling phase, POIs are the basis of building templates in TA. How to choose the POIs correctly is significantly important. The quality of the template is directly related to the correctness of obtaining the key in the second phase.
The steps for the new TA proposed in this section are as follows:
Finding POIs
For any block cipher algorithm, non-linear substitution (SBOX) is the key part of block cipher algorithms as it ensures their reliability and is thus the major target in side-channel attacks. The input of round

Definition 1
Definition 2
Traditionally, traces need to be grouped into hamming weight groups of
We propose that the positions of SBOX’s input and output can be found on the basis of X-groups, which can be obtained without the round key according to its definition. Suppose
Given that the SBOX’s input of each X-group is the same, the SBOX’s output of each X-group will be the same as well. Therefore, the sum of difference in the mean of X-groups will reveal the leakage positions of SBOX’s input and output.
We take SM4 as an example. In SM4, each round function has four SBOX’s, the input of each SBOX is the value of 8 bits

where

The operation process of each SBOX at the first round.
In accordance with Formula (6),

In other words,
Figure 5 shows the peaks of SOST of SBOX’s input and output calculated on the basis of X-groups, which are nearly in the exact same positions found in hamming weight groups with the known round key.

SOST curve of X-groups for device A (section “Verification and comparison”). The highest peak is the leak position of SBOX input, and the second highest peak is the leak position of SBOX output.
After the positions of SBOX’s input and output are located, several POIs can be chosen around one of them.
But the method to locate the positions of SBOX’s input and output is not straightforward. Figure 6 shows the SOST curve of another device on which traces are measured with a significantly high sampling frequency. Similar to those in Figure 5,

SOST curve of X-groups for device B (section “Verification and comparison”). Left and right peaks are surrounded by several subpeaks that bring difficulty in locating the two peaks automatically.
Definition 3
Major peak region (MPR) is a horizontal range in a line diagram, in which the horizontal distance of any neighboring subpeaks is less than or equal to a maximum distance named width parameter. An MPR is composed of a left endpoint, a right endpoint, and a peak location where the highest peak locates in that region. The left and right endpoints represent the current boundary of a region.
As shown in Figure 6, before locating the positions of SBOX’s input and output, we should recognize two MPRs of the curve.
MPR is used to represent the inverse V-shaped regions of the major peaks by collecting the neighboring subpeaks in that region. When creating an MPR given an initial location, the location will be the initial left and right endpoints. In determining whether a new location belongs to a region, the location will be compared with the left and right endpoints and will result in three cases: if the new location is between the two endpoints, then it belongs to that region; if the new location is outside of the region but within the maximum distance to the left or right endpoint, then it expands that region by replacing the left or right endpoint with itself; otherwise, the new location does not belong to that region. On this basis, the steps of the method for locating the two major peaks of SOSD or SOST curve are described as follows:
Thereafter, each created MPR will represent an inverse V-shaped peak region. This method can find all the peak regions on the curve, so we can easily choose two highest major peaks. This method uses the width parameter to smooth the SOST curve. If width parameter is set too small, then some subpeaks will be created as an individual MPR and the correct second highest major peak may be missed. If width parameter is set too large, then the two inverse V-shaped regions may be merged into one MPR and the second highest major peak will also be missed. Empirically, our experimental results suggest that 10 times of the width of an instruction width will be a good choice. Figure 7 shows the result of the proposed method which shows that the locations of SBOX’s input and output are located correctly.
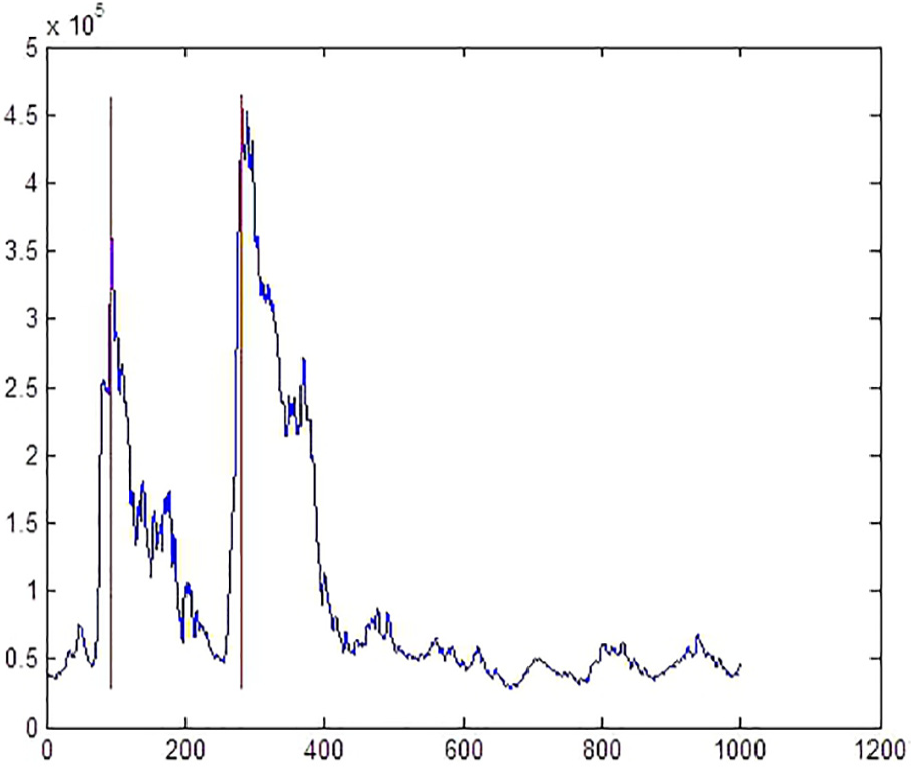
Red lines are located at the two major peaks by the use of the MPR method with the width parameter set to 10 times of the instruction width.
Building templates on the basis of X-groups
POIs of the SBOX’s input or output at the first round can be used to establish templates and then extract the round key of the first round. The

The procedure of the novel TA.
After the POIs are located, the next task is to build templates for the power consumption model of SBOX’s input or output. Unfortunately, while the hamming weights of the SBOX’s input or output of X-groups and the round key are unknown, templates cannot be established directly on X-groups. In this article, we propose a novel method for determining the hamming weight of the SBOX’s input or output of each X-group.
According to the hamming weight model, the mean power consumption of each X-group should be proportional or inversely proportional to their hamming weights. Thus, the X-group with large mean power consumption will obtain a large hamming weight. Suppose the plaintexts are uniformly distributed, then

Member distributions: (a) for device A and (b) for device B.
After the hamming weight of each X-group is assigned, X-groups with the same hamming weight will be merged into one hamming weight group. The power vectors of traces in each hamming weight group will also be used to establish the corresponding multivariate Gaussian distribution template by calculating their mean and covariant matrix, as Formula (4).
We intuitively validate the method for establishing hamming weight templates on the basis of X-groups. For this purpose, two sets of templates obtained by the proposed approach and by conventional TA profiling are drawn in Figure 9 in different colors.
Arbitrarily assigning the hamming weight for each X-group may be incorrect as the number of traces in each X-group is relatively small. For example, suppose 3840 traces are available and the input of SBOX is 8 bits, then 256 X-groups will be generated, and each of them will contain only 15 traces on average. Under the noise environment, their average power may drift into the power range of nearby X-groups. This condition can cause certain inaccuracy of the estimated templates. Two methods are proposed to optimize the estimated templates.
Improvement 1: projecting the center of each template to the major orientation
According to the linear hamming weight power consumption model, the center of each member distribution should be located on a line along a specific orientation. Several experiments have verified this fact. As some X-groups may be assigned with an incorrect hamming weight, the center of member distribution may drift from that orientation. Projecting each template center onto the orientation line can be helpful.
The parameters of the major orientation line can be calculated using linear regression of the centers of estimated templates. Given that the groups with hamming weight 0 or 8 only contain traces in one X-group, their templates are least reliable and should be discarded in linear regression. Assuming

where
Assuming

After

The affine projection matrix will be a

where the top-left

where
Improvement 2: using the same covariance matrix for each template
As the VAR of power is mainly determined by the type of instruction, the VAR of every X-group at a specific position on traces should be the same. Similarly, the correlation of the power at two positions on traces should not be different from one X-group to another X-group. Ideally, each X-group should possess the same covariance matrix. As the template of the medium hamming weight is best qualified because it is built on the basis of the most number of traces, other templates covariance matrixes can be substituted by this covariance matrix

Extracting the key
In this section, the attacking method will be introduced first and then the entire attacking framework will be described, including a filtering process that can significantly reduce the number of combinations of candidate round keys used to attack the next round key.
The attacking method is the same as that of conventional TA. In particular, given a set of attacking traces, their joint probability of each possible subkey can be calculated by the probabilistic distribution of each template. Then, the top
Trace vectors in a hamming weight group disperse from the mean power vector of that hamming weight because of the Gaussian noise. If such traces located at the peripheral area of a distribution are used in attacking, then they can exert a negative effect on the attacking quality. On the contrary, traces located near the center of the distribution are a better choice. As the templates with medium hamming weights are qualified statistically because they are built on the basis of a large number of traces, they should contribute a large number of attacking traces. The number of attacking traces near the center of a template can be calculated as

where

where the input of SBOX is

Choosing 20 attacking traces near template centers. Templates with hamming weight 0 or 8 does not contribute to the attacking traces.
Different from conventional TA in which templates for all rounds are built in the profiling phase, this method can only build templates for the first round at the first time. Templates for the next round will be built on the basis of the output of the previous round.
Building templates for the next round with each candidate round key of the previous round in the extraction process seems inefficient at first. This step is rather an advantage in the sense that the size of candidate set of round keys can be compressed by adding a filtering process in step 2. The size of candidate set is a key factor of the efficiency of an attacking scheme. Suppose four subkeys of each SBOX will be remained as the candidates, four SBOX’s are present in each round, and at least four round keys are needed to recover the main key as in SM4, then 256 candidate round keys will be generated in each round, thereby producing 256 sub-branches for each branch of the previous round. A total of 4,294,967,296 branches will be available for testing. If the candidate set can be compressed, then the attacking efficiency will be improved exponentially. In step 2, the SOSD or SOST will be calculated on the basis of the candidate round key of the previous round. An incorrect round key from the previous round will not produce any remarkable peak on SOSD or SOST curve because incorrect round key will produce incorrect

SOST for the second round: (a) on the basis of the correct first round key and (b) on the basis of the incorrect first round key.
The filtering process can be implemented by comparing the height of the highest peak of SOST with a minimum height or threshold, which is set to be five times the average SOST in our experiments. If a candidate round key can produce SOST in which the highest height is larger than the threshold, then the round key can be reserved. Otherwise, it will be filtered.
Another functionality of the filtering process is to determine the power proportional model of a device. As mentioned in section “Novel TA on SM4,” when attacking the first round, hamming weights are assigned to X-groups on the basis of an arbitrary assumption that the power consumption is proportional to the hamming weight. If this assumption is incorrect, then the candidate keys of the first round will be completely incorrect, which in turn will not produce any significant peak of the SOST for the second round. Whether the assumed proportional power model is correct, can be determined using the same criterion of filtering. If the model is incorrect, then the proportional model is reversed and step 3 of the first round is repeated.
Verification and comparison
We experiment on three different cryptographic devices with the SM4 crypto algorithm.
Device A is a 32-bit smartcard designed as a positive logic circuit with a software implementation of SM4.
Device B is an embedded system running SM4 on an 8-bit microprocessor AT90S8515 with the CPU frequency of 28 MHz.
Device C is also a 32-bit smartcard designed as a negative logic circuit.
Three trace sets are captured from devices A, B, and C with different sampling rates. Each contains 10,000 traces, which are divided into profiling and attacking sets in the ratio of 80% and 20%. Dividing trace sets into profiling and attacking sets is not necessary for the proposed algorithm but should be conducted in experiments for comparing the proposed attacking schema with conventional TA. A total of 20 traces are used in the extraction phase for all experiments.
Three types of experiments are conducted as follows.
Experiment 1 is designed to verify the correctness of locating the positions of SBOX’s input and output on the basis of X-groups.
Experiment 2 is conducted to compare the effectiveness of the proposed attacking method (i.e. proposed TA) with conventional TA (i.e. TA), in which the attacking traces are taken from a standalone attacking set different from the profiling set.
Experiment 3 tests the ultimate effectiveness of proposed TA, in which only one trace set is used in the profiling and extraction phases, and the attacking traces are taken near the centers of the templates (section “Novel TA on SM4”).
Table 1 shows the result of experiment 1, in which the positions of SBOX’s input and output obtained by the two methods (X-group and Hamming weight group) are nearly exactly the same for all devices.
Input and output positions of sbox1 of the first round.

Experiment 2 is designed to compare the effectiveness of proposed TA with TA and the effectiveness of four variants of profiling methods in the proposed TA.
For the sake of comparison with TA, the attacking traces used in this experiment are all selected from an attacking set different from the profiling set.
In Table 2, the highest success ratio and the minimum GE are highlighted in bold and italic font. For devices A and B, the effectiveness of the proposed TA and its variant are noticeably better than TA. For device C, the effectiveness of the proposed TA and its variant are comparable if not better than that of TA.
Comparing the effectiveness of variant profiling methods for sbox output.

GE: guessing entropy; TA: template attack.
Therefore, the quality of templates based on X-groups is better than that of templates based on hamming weight groups. This result is still unclear because the templates based on X-groups contain traces of incorrectly assigned hamming weights. One explanation is that the templates of TA overfit the profiling set. In Figure 10, the center of the TA template of hamming weight 0 is misplaced into the area of other templates. In other words, the probabilistic distribution of hamming weight 0 is inaccurate because of the inadequate profiling traces used to calculate the parameters of its distribution.
On the contrary, three variants of the proposed TA show no significant superiority to one another. For device A, the SgmProf method achieves the highest success ratio and the lowest GE. Meanwhile, for device C, the ProjProf method achieves the highest attacking quality. The situation of device B is complicated and for which the OrgProf method and the ProjProf method achieve the highest success ratio, while the SgmProf method and the ProjSgm method obtain the lowest GE. In summary, the variants of proposed TA exert no deterministic effect and are therefore optional.
Experiment 3 checks the effectiveness of the proposed method by selecting attacking traces from the same trace set of profiling and near the template centers as introduced in section “Novel TA on SM4.” The results shown in Table 3 are good. The first-order success ratios for all devices achieve 100%.
Effectiveness of using traces near template centers in attacking SBOX’s output.

GE: guessing entropy; TA: template attack.
Conclusion
This article provides an insight into how to extract the crypto key of the cipher algorithm in the smartcard, which is the most important cyber-domain information, from the side-channel leakage information transmitted by the cyber-physical system. As a case study, the embedded system and the smartcard running SM4 crypto algorithm are selected, and analog power emission is analyzed. We propose a novel TA on the SM4 algorithm. POIs are the basis of building templates in TA. Sometimes adversary cannot locate the positions of SBOXs input and output straightforwardly, a new MPR method for finding POIs correctly is proposed. A method for establishing templates on the basis of those POIs still without requiring knowledge of the key is proposed. Several techniques are proposed to improve the quality of the templates as well. A method for choosing attacking traces is proposed to significantly improve the attacking efficiency. The experimental results show that the proposed novel TA achieves much better attacking quality than does conventional TA. The method for locating the leakage positions of SBOX’s input and output without knowing the key may be applied in many other block cipher algorithms. This method also can be further studied in scenarios that consider countermeasures. This work serves as a proof of concept for necessity of exploring different analog emissions of CPSs that are capable of leaking information and weakening the confidentiality of the system. The proposed novel TA can effectively break through the limitations of the traditional TA, but there are other new attack ideas, such as SBOX input–output joint attack and voting attack. Further development can be considered in the follow-up study.