
Abstract
Keywords
Introduction
Understanding the complexity of qualitative datasets, such as interview transcripts and social media content, presents substantial challenges for researchers. This complexity is exacerbated by the myriad of qualitative analysis methods available. Content analysis, introduced as a quantitative technique for discerning patterns in qualitative data (Graneheim & Lundman, 2004), has since been redefined into a popularly adopted qualitative method (Cho & Lee, 2014). This history has led to a maze of competing, and often contradictory, forms of what has been referred to as qualitative content analysis (e.g., Ahuvia, 2001; Cavanagh, 1997; Cho & Lee, 2014; Downe-Wamboldt, 1992; Elo & Kyngäs, 2008; Erlingsson & Brysiewicz, 2017; Hsieh & Shannon, 2005; Krippendorff, 2004; Kuckartz, 2019; Mayring, 2015, 2019; Schreier, 2012, 2014; Vaismoradi et al., 2013; Vears & Gillam, 2022). The existence of competing qualitative content analysis approaches has led to several problems for researchers and students seeking to utilise these methods.
Firstly, it has become difficult to understand and apply qualitative content analysis procedures (Cho & Lee, 2014; Vears & Gillam, 2022). Indeed, research papers often cite competing qualitative content analysis approaches in their analytical procedures without reconciling apparent discrepancies. For example, various approaches differ in their conceptualisation of analysis structures and the assignment of data to mutually exclusive analysis units, creating substantial confusion (Elo et al., 2014; Krippendorff, 2004; Schreier, 2012; Vaismoradi et al., 2016; Vears & Gillam, 2022). The concept of mutual exclusivity in analysis units, warrants explicit discussion and clarification, especially given its foundational role in the analytical process. Moreover, the qualitative use of content analysis procedures is often not supported by appropriate epistemological and methodological assumptions and seen as atheoretical (Braun & Clarke, 2021a). Combined these issues have led to substantial difficulties in understanding qualitative content analysis, confusion in the applications of these methods within qualitative research frameworks, and have created substantial barriers for those seeking to apply these methods.
Secondly, the level of interpretation required by qualitive content analysis methods is often ambiguous. Qualitative content analysis has generally been seen as a method for the systematic reduction and description of textual data with the aim of identifying meaningful patterns (Cavanagh, 1997; Cho & Lee, 2014; Elo & Kyngäs, 2008; Erlingsson & Brysiewicz, 2017; Hsieh & Shannon, 2005; Mayring, 2015; Schreier, 2012). Yet, there is a lack of clarity regarding the depth of information being systematically described and reduced. Previous authors have stated that qualitative content analysis may be used to analyse both manifest content, the overt surface meanings of texts, and latent content, the deep underlying meanings of texts (Cho & Lee, 2014, 2014, 2014; Erlingsson & Brysiewicz, 2017; Graneheim et al., 2017; Graneheim & Lundman, 2004). In practice, however, the depth of content considered in an analysis and the level of interpretation conducted may be confused or not reported.
Finally, the inclusion of both manifest and latent content has become problematic for qualitative content analysis methods. The different qualitative content analysis methods available are not seen as distinct from other methods such as thematic analysis (Braun & Clarke, 2021a; Schreier, 2012; Vaismoradi et al., 2013). Some authors have even suggested that qualitative content analysis is only semantically different from thematic analysis (e.g., Kuckartz, 2019). This overlooks the fundamentally interpretive nature of methods such as thematic analysis, which go beyond reducing and describing data to include a nuanced interpretation of underlying meanings and patterns. While a small body of literature has compared European approaches to qualitative content analysis with grounded theory methodologies (Schreier et al., 2020), a properly differentiated method is elusive. Consequently, it is imperative to clearly define a distinctive qualitative content analysis approach that adheres to the historic use of this method to reduce and describe qualitative data.
These problems underscore a need for a qualitative content analysis method that is not only well-defined but also clearly applicable within qualitative research frameworks. This method should enable the effective reduction and description of data, while establishing a clear distinction from other qualitative methods. This paper introduces Reflexive Content Analysis (RCA), an improved method of qualitative content analysis. RCA distinguishes itself as an inductive transtheoretical and flexible researcher-oriented method for the description and reduction of manifest qualitative data. This paper provides a summary of the foundational principles of this method, associated key terms and concepts, and outlines the process for conducting an inductive RCA within a qualitative framework.
Foundational Principles of Reflexive Content Analysis
RCA is intended for the reduction and description of manifest qualitative data with reference to one or more predetermined research questions. The analysis process aims to classify and characterise patterns through the construction of a hierarchical analysis structure of quantifiable analytic strata. The analysis process is systematic and iterative, unfolding in defined stages. At each juncture, the researcher adopts a reflexive stance, which is instrumental in achieving quality description of the data. In addition, RCA can be deployed within different methodological and epistemological perspectives. Thus, RCA can be used as part of a rigorous qualitative methodology, while offering avenues for data quantification when this corresponds with a researcher’s broader research frameworks. This approach was derived from conventional qualitative content analysis described by Hsieh and Shannon (2005). Nevertheless, RCA distinguishes itself by offering several beneficial departures from these earlier methodologies. These include: the use of reflexivity as an analytic resource, the analysis of manifest content, and the design of RCA as a transtheoretical and flexible method being suitable for a range of research frameworks.
Reflexivity as an Analytic Resource
There has been growing recognition of the role of reflexivity in rigorous qualitative research (Braun & Clarke, 2019, 2021b; Campbell et al., 2021; Lazard & McAvoy, 2020). However, understanding what reflexivity represents can be particularly challenging to grasp, especially for those new to qualitative research. Simply put, reflexivity represents an acknowledgment of how subjective experiences such as prior events, preexisting knowledge, assumptions, and sociohistorical-political context influence a researcher’s engagement with research processes and decisions (Braun & Clarke, 2019; Erlingsson & Brysiewicz, 2017; Lazard & McAvoy, 2020). Lazard and McAvoy (2020) draw a useful parallel between reflexive practice and Socratic questioning. They suggest that reflexivity can be seen as a process of continuously questioning research and analytical decisions, with the aim of illuminating and comprehending the impact of subjective choices made throughout the research process. This continuous questioning and unpacking of subjective assumptions is fundamental to conducting RCA and draws inspiration from the application of reflexivity as an analytical resource in thematic analysis (Braun & Clarke, 2019).
Previous scholarly works on qualitative content analysis have acknowledged the subjective roles researchers play in the construction of their analyses (Downe-Wamboldt, 1992; Mayring, 2019; Schreier, 2012; Vaismoradi et al., 2016) and have also mentioned reflexive practices (Erlingsson & Brysiewicz, 2017). However, no established qualitative content analysis method has fully integrated reflexivity as an analytical resource, nor have they thoroughly described the integration of reflexive practices throughout the analysis process. In RCA, reflexivity is central to each stage of the analysis process and is employed to assist and strengthen the development of findings.
The Analysis of Manifest Content
Throughout the RCA process, the researcher attempts to stay as close as possible to the surface meanings explicitly communicated in the data. This manifest content does not require deep interpretation of the underlying contextual or intended meanings present within data (Cho & Lee, 2014; Downe-Wamboldt, 1992; Graneheim et al., 2017; Graneheim & Lundman, 2004) whereas latent content requires significant interpretation (Colorafi & Evans, 2016; Vaismoradi & Snelgrove, 2019). In this way, the product of RCA can be seen as providing a description of the who, what, when, and where information that is present in a dataset. Thus, RCA is well suited to exploring the overtly expressed experiences, thoughts, and needs of participants without deeply considering their interpretative context.
Constraining the analysis to manifest content is a principal divergence of RCA from other qualitative approaches such as thematic analysis, which explore latent meanings (Schreier, 2012; Vaismoradi et al., 2016; Vears & Gillam, 2022). This focus on manifest content does not necessitate the extensive cognitive inference and interpretation required of analyses that include latent content (Colorafi & Evans, 2016; Vaismoradi & Snelgrove, 2019). While this focus on manifest content may be beneficial for novice researchers (Vears & Gillam, 2022), experienced researchers may also leverage RCA for its efficiency and clarity when handling large conceptually diverse datasets. Moreover, not every research initiative calls for intensive engagement with latent content. As described later, many research questions may be adequately addressed through the analysis of manifest content.
This focus on manifest content does not mean that the analysis process is free from interpretation. Parallels may be drawn with Sandelowski’s (2000, 2010) defence of qualitative descriptive approaches. According to Sandelowski, the description and presentation of the surface phenomenon conveyed in texts will always necessitate interpretation, offering insights that are distinct and equally valuable as those derived from deeper interpretive analyses of latent meanings. Describing data, always requires a degree of interpretation and for assumptions to be made in order to understand what is being said (Braun & Clarke, 2021b; Downe-Wamboldt, 1992; Graneheim & Lundman, 2004; Kuckartz, 2019; Mayring, 2015; Vaismoradi et al., 2013; Vears & Gillam, 2022). The data must also be understood within its context and the communication mediums used (Mayring, 2015). As a result, there is no singularly definitive interpretation of manifest content. This underscores why reflexivity is considered an essential analytical resource throughout the analysis process. The analyst must make the best determination possible as to whether they are appropriately describing and reducing the overt content represented in their data.
RCA as a Transtheoretical and Flexible Method
Attempting to only analyse manifest content does not mean that this method is an atheoretical or positivist process. RCA is explicitly intended to be a transtheoretical and flexible method, rather than a methodology, that is capable of being deployed within qualitative research frameworks. To appreciate this distinction, it is essential to delineate epistemology, methodology, and methods as these components are often variably defined in the literature (Carter & Little, 2007; Chamberlain, 2015; Jackson et al., 2007). Epistemology serves as the core theory concerning the nature of knowledge and how it can be acquired, which in turn informs the methodology which is the comprehensive strategy and reasoning underpinning research (Carter & Little, 2007; Chamberlain, 2015). Epistemology and methodology guide methods; these are the specific actions taken during the research process, including data collection, analysis, and reporting (Carter & Little, 2007; Chamberlain, 2015; Jackson et al., 2007). RCA can best be seen as a discrete method, a way of conducting data analysis, able to be applied within a number of different methodological and epistemological perspectives.
This approach differs from common perceptions of qualitative content analysis that have often portrayed these methods as not engaging with epistemological and theoretical considerations (Braun & Clarke, 2021a). In this way, RCA should be seen as a building block for a rigorous qualitative methodology that must be deployed within a methodological framework supported by an appropriate epistemology. This transtheoretical perspective provides opportunities for researchers to engage in both the qualitative and quantitative interpretation of textual data, when aligned with appropriate epistemological perspectives. Similarly, broader methodological and epistemological choices will influence how reflexivity is employed. For example, depending on these choices, reflexivity may serve as a means of bias control (a positivist perspective) or as a tool for enhancing the interpretation of participant-conveyed meanings (a constructionist perspective). In itself, RCA is simply a way of doing data analysis.
From a metaphoric standpoint, and ignoring the breadth and subtlety required by differing epistemological perspectives, RCA can be likened to a landscape painter employing an artistic method to render a scene. The goal of the painter is to utilise said method to create a representation of the physical content present within a landscape. Like an artistic method, RCA provides researchers with a set of guidelines to help represent the manifest content of a qualitative dataset.
Key Concepts in RCA
In order to describe and reduce qualitative data, RCA relies on a hierarchical analysis structure of defined quantifiable analytic strata, assumptions about the interrelationships between each stratum, and the potential for the quantification of data. These concepts combined represent the key components of RCA and provide value to answering research questions.
Analysis Structure and Analytic Strata
The RCA analysis structure is made up of three analytic strata: codes, subcategories, and categories. It is most helpful to see these as existing on a continuum of abstraction. Codes are the least abstract, being the closest to the data, subcategories are at a medium level of abstraction, and categories provide the most abstract description of the data.
Codes
What constitutes codes and coding is a source of confusion in research methods literature (Elliott, 2018; Skjott Linneberg & Korsgaard, 2019). Coding is best seen as a process of tagging textual data that is relevant to a research question with short phrases that capture the meaning of that portion of text (Elliott, 2018). In prior descriptions of qualitative content analysis, codes are typically characterized as concise tags, ranging from one to three words, that encapsulate recurring, condensed phrases with significant meaning, extracted through a process of deconstructing a dataset (Erlingsson & Brysiewicz, 2017; Graneheim & Lundman, 2004; Lindgren et al., 2020). The process of deconstructing data and using short labels for codes is problematic as this can over compress qualitative data which threatens the richness of the original text (Elo & Kyngäs, 2008).
In order for codes to capture the richness of their original text, RCA takes a specific approach to coding and the construction of codes. Codes in RCA act as containers for recurring or singular pieces of text that are relevant to a research question. Codes are labelled using short self-defining sentences that are based on the manifest meanings of textual instances contained within each code. For example, the code “Feeling anxious about upcoming medical treatments” would capture all instances in which participants described their feelings of anxiety regarding their upcoming medical treatments. Using labels directly derived from the text allows RCA to reduce a dataset while capturing its original richness. Additionally, the self-definitional nature of these labels is intended to make it easier for the researcher analysing the data to work with a large volumes of codes.
The specificity of the manifest content captured by a code is dictated by the precision of the label used. Labels with broader definitions will encompass a greater number of textual instances compared to those with more restricted definitions. It is best to keep the labels used for codes reasonably constrained as they are intended to capture fine-grained surfaces meanings within a dataset. However, this approach does not imply that the coding process should be exhaustive; only data pertinent to the research question should be coded (Elliott, 2018; Kuckartz, 2019).
Each code must also be conceptually distinct, although overlap in their textual content is permissible, reflecting the complexity of qualitative data. The presumed mutual exclusivity of codes, or subcategories and categories depending on the nomenclature used, is often a taken-for-granted assumption of qualitative content analysis procedures. In RCA the development of codes is a researcher-driven process, where the exclusivity of each code is determined based on the researcher’s assessment of each code’s unique value when presented as a distinct unit. Therefore, while the same data may appear in multiple codes, each code should maintain a unique conceptual identity, and these decisions represent a reflexive choice.
Subcategories
Subcategories exist at a medium level of abstraction and are simply a collection of codes with several distinctive features. Firstly, the decisions made regarding the number, nature, and rationale for grouping various codes into a subcategory is determined at the discretion of the researcher analysing the data. For example, subcategories could be used to join a series of codes that have similar manifest content, because they provide similar responses to an interview question, or because when grouped together they contribute to a coherent description of the dataset that addresses a specific research question. Secondly, like codes, subcategories are labelled in a self-definitional manner with the labels for each subcategory being based on, and congruent with, the different content conveyed in each code it subsumes. Lastly, each code must be exclusively subsumed into a subcategory to allow for the effective reduction of the data.
Categories
The term “category” has taken on a range of definitions in previous qualitative content analysis literature with authors even delineating between different types of categories (Kuckartz, 2019). Some inductive approaches have pre-conceptualised categories before detailed coding begins and then inductively assigned codes to these (Mayring, 2015; Vears & Gillam, 2022). Unlike prior methods, categories in RCA are an overarching container for subcategories and their subsumed codes, that a researcher groups together based on their relation to a research question. Like codes and subcategories, categories are named in a self-definitional manner with a label based on the content of the subcategories it subsumes. Categories must subsume all subcategories created during the analysis. A category can be seen as providing a big picture and highly abstracted overview of some pattern resulting from the manifest content present within a dataset. Categories, therefore, represent the end point of the data reduction and description process.
It must be noted that categories are not comparable to themes – these analytic strata are mutually exclusive and distinct. A category is simply a collection of meaningfully related manifest content within a qualitative dataset, while a theme is seen as deeply interpretive and provides insight into the complexities of latent content (Braun & Clarke, 2019; Erlingsson & Brysiewicz, 2017; Vaismoradi et al., 2013, 2016; Vaismoradi & Snelgrove, 2019; Vears & Gillam, 2022). Themes can answer the how and why present in a dataset (Erlingsson & Brysiewicz, 2017; Graneheim & Lundman, 2004) and may be used to link the latent meanings of multiple categories (Graneheim et al., 2017; Graneheim & Lundman, 2004). On the other hand, in RCA categories are descriptive and aim to stay close to the manifest content from which they were constructed. The difference between categories and themes also stems from how RCA handles the interrelationships between analytic strata as a product of data reduction.
The Interrelationships of Analytic Strata
As discussed above, codes are assigned to subcategories, which in turn are assigned to an overarching category forming a tree-like structure. Thus, the concepts presented in each code, subcategory, and category must be conceptually distinct from the other branches. If the goal of the analysis is the reduction and description of a dataset in relation to a research question about manifest content, further analysis is unnecessary and may even be counterproductive. It would be unhelpful for data reduction purposes to have an identical code for a distinct concept in multiple places. Additionally, drawing connections between these different structures and their associated analytic strata risks recreating the complexity of the original qualitative dataset.
If you aim to identify interrelationships between analytic strata, or desire to understand latent phenomena you should consider the use of themes. Whilst some authors have suggested that themes can be developed within various forms of qualitative content analysis (Cho & Lee, 2014; Erlingsson & Brysiewicz, 2017; Graneheim & Lundman, 2004), in RCA the category structure represents the end state of the analysis. This does not mean that latent content and themes cannot be considered. Further scholarship should consider using RCA as the basis for more rigorous methods of theme generation such as thematic analysis (see Braun & Clarke, 2006).
The Counting of Analytic Strata
The idea of counting when analysing qualitative data may elicit scepticism or concern among qualitative researchers due to the positivist assumptions tied to the quantification of data. Counting has been seen as inconsistent with qualitative accounts of meaning (Vears & Gillam, 2022) and as possibly obscuring important but infrequent information (Elliott, 2018). However, all qualitative methods involve the implicit quantification of certain aspects of the analysis (Morgan, 1993). Other authors, that are more sympathetic to quantification, have stated that counting can be cautiously used as a proxy for significance and assist in the generation of analysis structures (Vaismoradi et al., 2013; Vaismoradi & Snelgrove, 2019). Counting and the quantification of analytic strata play an important role in conducting and reporting RCA. Researchers seeking to employ RCA should base the use of quantification on the methodological and epistemological perspectives guiding their analysis.
The counting of analytic strata can serve several functions. The use of occurrence frequencies can assist in the creation and interpretation of patterns that are described in the data, allow for comparisons to be drawn, and highlight contradictory results (Morgan, 1993; Skjott Linneberg & Korsgaard, 2019). Counting provides a way of demonstrating the credibility of data by providing extra support to a researchers claims (Morgan, 1993). In addition, the counting of analytic strata may also be viewed favourably by government agencies and industry partners who view quantification as essential to establishing claims.
While it is deemed beneficial to RCA, the use of quantification comes with three critical caveats. Firstly, any use of counting during the analysis process must be consistent with the epistemology and methodology that supports the research. Secondly, in qualitative applications, occurrence frequencies generated through counting should not be seen as a proxy for statistical significance. If something occurs more frequently this does not necessarily mean that it is more important. The importance of an account or pattern should be determined by a researcher based on factors such as the context of the data, the research question used, and the information conveyed. Thirdly, if statistical tests are used to compare different frequencies, the analytic strata that are being compared must meet the assumptions of the statistical tests used (Downe-Wamboldt, 1992).
How to do RCA
Following from previous approaches to qualitative content analysis, RCA is based on a systematic process that occurs over a set number of stages (Hsieh & Shannon, 2005; Kuckartz, 2019; Mayring, 2015, 2019; Schreier, 2014). Each stage is grounded in reflexive practices. As such, it is critical to keep a highly detail audit trail or researcher diary regarding the analytical and research decisions made (Rodgers & Cowles, 1993; Tobin & Begley, 2004; Vaismoradi et al., 2013, 2016). The RCA process is conducted through seven stages with stages three, four, and five occurring in an iterative loop that continues until it is believed that the best analysis structure is achieved (Figure 1). The seven stages of the RCA process and reflexive practices.
The following sections outline the processes and critical considerations involved in conducting an inductive RCA within a qualitative research framework. How to conduct each stage of the analysis process will be discussed through the use of a worked example based on a study I conducted, as documented in Nicmanis et al. (2023). This study aimed to characterise the experiences and questions that people living with a cardiac implantable electronic device (CIED) posted to a social media web site. The devices included in this study are surgically implanted and provide electrical stimulation to the heart to treat a range of cardiac issues (for a review see Steffen et al., 2019).
Stage 1: The Research Question, Perspectives, and Necessity of RCA
Simplistic Example Questions for RCA.

Once a research question has been determined, it must be decided what analysis method best fits this question (Elo et al., 2014) and whether RCA is appropriate. The research questions and method should be consistent with the methodological and epistemological perspectives taken by the research. RCA is a method for the reduction and description of the manifest content within a dataset. Thus, this method may not be optimal for studies that require detailed understandings of latent content. For example, in the case of research assessing the lived experiences of a vulnerable minority group, RCA may not provide as much detail as other methods. Constraining the analysis solely to manifest content, without interpreting broader social structures, may risk overlooking important aspects of these groups' experiences. While the use of reflexivity can allow for these issues to be explored, descriptive categories do not provide the same opportunities as themes to explore latent content that may affect participants’ lived experience. In cases where latent analysis is required, the use of other methods in conjunction with RCA should be explored.
In the case of the example provided by Nicmanis et al. (2023), the research question chosen was “What questions, and information about their experiences, do people living with a CIED post to communities intended for them on the social media web site studied?” Given that the data originated from social media, it was often in the form of short social media posts that described symptoms and problems. Furthermore, little prior qualitative research had been conducted in this area and participants came from a diverse range of geographic locations and healthcare systems. Therefore, RCA was chosen as it was not expected that the deep interpretive analysis required for latent content would be useful in answering this research question. The analysis was conducted from a critical realist epistemological perspective, and an inductive analysis approach was chosen to ensure a representation of participants’ unique experiences.
Stage 2: Data Collection and Familiarization
Once a research question and the necessity of RCA has been determined, data collection can begin. RCA is suited to many types of qualitative data including: open-ended interviews, semi-structured interviews, surveys, online forum posts, and textual documents. Data analysis is best done after data collection, but these may co-occur if deemed necessary.
Once collected, you must familiarise yourself with the dataset. Data familiarisation and immersion has featured as a critical step in qualitative research methods (Braun & Clarke, 2006; Elo & Kyngäs, 2008; Erlingsson & Brysiewicz, 2017; Vears & Gillam, 2022), and is generally viewed as a process of active repeated rereading of a dataset. Familiarisation is critical to the RCA process and aids in reducing the time-demands of later analysis stages. It is recommended that your dataset is read one to two times, while taking audit trail notes about potential patterns and assumptions about the manifest content presented. This process may provide insight into possible structures for the analysis and assists with the later coding of data.
Stage 3: Coding
The third stage in the RCA process is to code the data. As described above, codes act as containers for textual data relevant to a research question and are labelled based on the content they contain. The coding process involves reading the dataset line-by-line, noticing text relevant to the research question, and placing this into a code that is then defined by said information. Once this is done, each piece of successive similar information will also be coded with that code. There is no limit to the length of text included in a code, but textual data should always be relevant to the code. The process of coding is best conducted in a qualitative analysis software, however, a coding workbook that allows researchers to code data in a word document format is attached as a data supplement (see supplemental material). Figure 2 illustrates two extracts reported by Nicmanis et al. (2023) and a subset of the initial codes that were applied to each extract. Upon completion of initial coding 256 codes were represented in the study. Two extracts and a subset of initial codes. 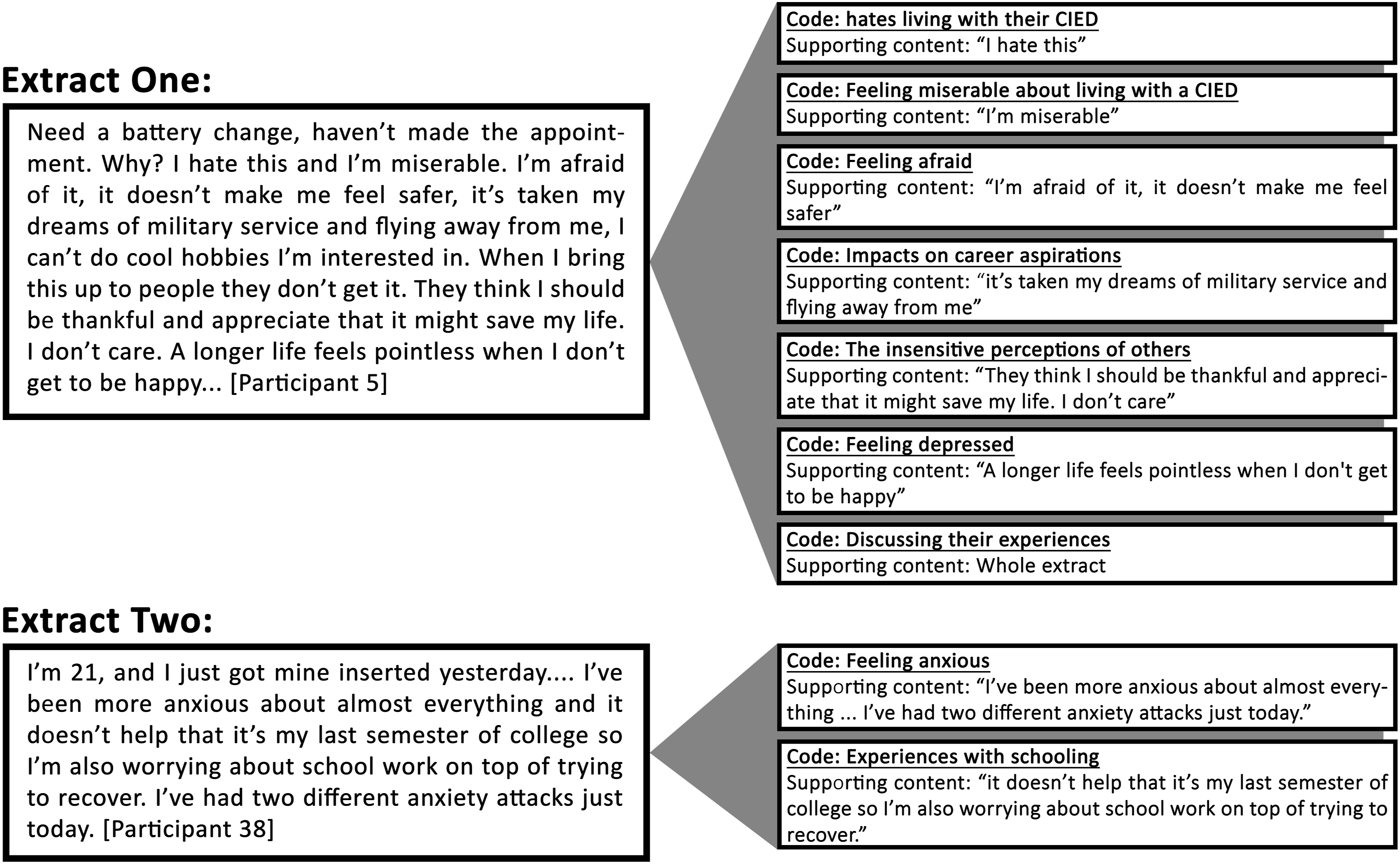
Coding is an active process, and codes do not need to be perfect in the first stage of the analysis. As the analysis progresses, more codes are added, and this will shift the definitions of codes as attempts are made to best capture the data. As coding is a subjective decision making process (Elliott, 2018), an effort should be made to keep track of decisions in an audit trail. Self-reflection on why codes were created and their meaning to the research question is critical for good coding.
Stage 4: Revising Codes
The first round of coding will be prone to flaws as it is impossible to fully capture all the observable patterns in a dataset while progressively creating codes in a line-by-line process. Hence, coding is an iterative process during which a revision stage occurs. In this revision stage, codes may be broken into smaller codes or codes with very similar meanings may be combined. Potentially interesting elements of manifest content may also only become apparent at the end of coding, thus requiring the creation of new codes. Once these codes have been revised you must go back through the dataset in order to ensure these revisions are consistent and no information has been missed. In the case of Nicmanis et al. (2023), the initial 256 codes were condensed into 104 well-defined codes. Figure 3 depicts the initial codes reported in Figure 2, the revisions made during various stages of the analysis, and the final codes. Initial codes depicted in Figure 2 and revisions made during the analysis. 
Stage 5: Developing the Analysis Structure
Once satisfied with the state of the codes constructed from the data, the next stage is to structure the codes into subcategories and categories. This process requires you to have a firm understanding of the data in order to structure these analytic strata in a way that meaningfully answers your research question. The process of developing the analysis structure will take numerous rounds of tweaking to make sure that every code is subsumed into an appropriate subcategory, and every subcategory is then assigned to an overarching category. This process may also require you to iteratively move through the prior two stages as you develop a greater understanding of the data and work to create a coherent analysis structure.
The ordering of codes, subcategories, and categories in the analysis structure is not a fixed process and requires careful consideration. If counting is undertaken, it may make the most sense to order analytic strata based on their frequency. This does not necessarily mean that analytic strata must always be ordered by frequency. For example, different analytic strata may be ordered based on their importance to understanding the analysis or data.
Determining when the analysis structure is complete is difficult as there is no one “true” structure that perfectly describes and reduces the data. The state of the final analysis structure is ultimately determined by the researcher responsible for its creation. The number of categories or subcategories does not matter as long as this structure is easy to understand, relevant to the research question used, and is not easily contested by another researcher evaluating the finished analysis.
Stage 6: Reporting the Analysis Structure
The finished analysis structure must be appropriately reported as this represents the main results of the RCA process. How the analysis is reported will depend on where it is intended to be published as journals, conferences, and various report formats each specify unique publication standards. However, were possible no parts of the analysis structure should be neglected, and every analysis unit should be highlighted in some way (Vears & Gillam, 2022). The structure itself can be presented as a table or figure presenting the different categories, subcategories, and codes. Both a graphical representation and complete analysis table were reported by Nicmanis et al. (2023). Graphical representations are particularly important as they provide insight into how the analysis was constructed and increase clarity (Elo et al., 2014; Erlingsson & Brysiewicz, 2017).
Alongside graphical representations, a narrative summary of the analysis structure should be provided. Throughout the narrative summary it is important to report representative extracts from the data in order to enhance the credibility and understanding of the data (Elo et al., 2014). Additionally, these summaries provide space to engage with reflexivity. Where possible interpretive leaps or critical choices regarding how the analysis was conducted recorded in the audit trail should be reported. While this is the case, it’s important to note that the inclusion of reflexive insights in reporting is often a pragmatic matter, as certain journals and publication platforms may not require or accommodate reflexivity in their content.
Stage 7: Interpreting Findings
Once the results of the RCA process are presented, these findings must be interpreted within the context of prior theory and research. Full coverage of how to interpret the findings of RCA is beyond the scope of this paper as interpretation is largely determined by the methodological and epistemological perspectives taken. However, all quality research should engage with literature to highlight potential support or contradictions of prior findings and theory.
Suggestions for Evaluating Analysis Quality
Approaches to qualitative content analysis have focused on the use of positivist metrics for the evaluation of analysis quality such as inter-coder reliability (Cavanagh, 1997; Downe-Wamboldt, 1992; Kuckartz, 2019; Mayring, 2015). Such metrics have received criticism (O’Connor & Joffe, 2020) and specific criteria have been developed for evaluating the quality of qualitative research (e.g.: Tracy, 2010). When used in a qualitative framework, evaluations of RCA should be consistent with those used for qualitative paradigms. In cases where counting and statistical analysis is employed, these findings should be evaluated with independent metrics for quantitative evaluation.
While this paper has primarily depicted the RCA process as the undertaking of an individual researcher, it is important to acknowledge that incorporating a variety of perspectives can substantially improve the analysis. Multiple researchers may work together to create high quality analyses. When deployed in a qualitative framework, emphasis should be placed on the diverse insights provided by multiple researchers into the patterns observed in the data, rather than striving for consensus among them (Erlingsson & Brysiewicz, 2017). This might involve researchers collaborating to analyse the data or contributing to discussions about the analytical strata throughout the research process. In addition, participants should be provided with opportunities to give their perspectives on the analysis. This may include gaining individual feedback from participants, running group feedback sessions, or providing participants the opportunity to give their written perspectives on the research. In qualitative contexts, the involvement of other researchers and participants in the analysis substantially bolsters the credibility of a study (Tracy, 2010).
Limitations and Recommendations for Future Research
As RCA is an emerging method of qualitative analysis, several limitations are currently present which future scholarly investigations could address. This paper outlines the necessary steps for employing RCA inductively, but the investigation into its deductive applications, as informed by the principles and concepts previously established, presents an area for further investigation. Additionally, RCA has been delineated as a method for the analysis of manifest content. Given the value that latent content presents for some research topics, there is a need to explore the integration of RCA with other methods in cases where a thorough understanding of both latent and manifest content is required. Similarly, the application of RCA within the diverse range of epistemological perspectives and methodological frameworks in research is yet to be fully explored. Future work should expand on current qualitative methodological literature by thoroughly interrogating the rigours of engaging with these considerations while conducting RCA. Lastly, while RCA has been presented as a tool for textual data analysis, future work should investigate the possibility of extending the guiding principles and concepts of RCA to other forms of qualitative data.
Conclusion
In summary, RCA is a method intended for the reduction and description of manifest qualitative data that is relevant to one or more research questions. RCA involves assigning qualitative data to codes that are derived from the data analysed. These codes are then grouped into subcategories and categories, forming a hierarchical analysis structure that provides insights into patterns within the data. RCA is considered to be transtheoretical and flexible being able to be deployed within a number of epistemologies and methodologies. In addition, reflexivity is acknowledged as an analytical resource that is drawn upon to assist the analysis process. These characteristics combined mean that RCA is distinctive from previous forms of qualitative content analysis and suitable for a range of research questions that require limited interpretation of latent content.
Supplemental Material
Supplemental Material - Reflexive Content Analysis: An Approach to Qualitative Data Analysis, Reduction, and Description
Supplemental Material for Reflexive Content Analysis: An Approach to Qualitative Data Analysis, Reduction, and Description by Mitchell Nicmanisd in International Journal of Qualitative Methods
Footnotes
Acknowledgments
Declaration of Conflicting Interests
Funding
ORCID iD
Supplemental Material
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.