
Abstract
Qualitative research seeks to uncover nuanced meanings and contextual subtleties that elude simplistic categorization. However, the labor-intensive nature of traditional qualitative processes—manual coding, iterative reading, audio transcription—creates tension between analytical depth and practical constraints. Recent advances in generative artificial intelligence (AI), and with Large Language Models (LLMs), in particular, offer methodological innovations that can fundamentally reshape how social scientists engage with qualitative data (see e.g., Christou, 2023; Schroeder et al., 2024; van Dis et al., 2023).
LLMs allow researchers to explore qualitative data in a “conversational” way for the first time, rather than being confined to predetermined codebooks or line-by-line interpretation of otherwise static text. By posing dialogue-like queries and natural-language prompts, analysts can uncover insights, highlight patterns, and discover conceptual connections that might otherwise remain hidden. What makes LLMs uniquely suited for qualitative analysis is their sophisticated ability to process and generate human-like responses based on extensive training across diverse corpora. Unlike traditional computational tools that rely on predetermined rules or statistical pattern matching, LLMs demonstrate a form of language “understanding” that, while fundamentally different from human cognition, enables remarkably nuanced analysis (Karimova, 2024; Marcus & Davis, 2019) that can grasp semantic relationships, contextual meanings, and subtle linguistic patterns across multiple scales of analysis (Brown et al., 2020; Ziems et al., 2023). This technological foundation enables LLMs to recognize not just explicit content but implicit meanings, cultural references, and contextual nuances—capabilities that more closely approximate human interpretive practices (Kim et al., 2024).
LLMs thus extend far beyond basic automation, offering sophisticated capabilities that strengthen the researcher’s toolkit: they can summarize and analyze interview transcripts, reveal thematic patterns across multiple datasets, generate theoretical propositions from empirical data, and reconcile coding disagreements with near-human accuracy (Bail, 2023; Wadhwa et al., 2023). They excel at identifying narrative structures, tracking conceptual evolution across texts, synthesizing findings across multiple data sources, and can even suggest theoretical frameworks that might explain observed patterns (Collins, 2024). Their multilingual capabilities enable cross-cultural research without extensive translation resources, while their recall capacity can track analytical decisions which enhances methodological accountability (Rathje et al., 2023). Recent advances have also enabled these systems to handle multimodal data, integrating text, audio, and visual elements in their analysis (Zhang et al., 2024).
Comparing the use of LLMs to traditional computational approaches reveals key distinctions. Traditional computational approaches, such as Latent Dirichlet Allocation (LDA) and topic modeling, have helped researchers identify patterns within large text corpora (DiMaggio et al., 2013). However, these methods, based on word frequency and co-occurrence, often miss the deeper contextual meanings central to qualitative inquiry. Similarly, while conventional Computer-Assisted Qualitative Data Analysis Software (CAQDAS) tools help organize and retrieve data, they offer limited analytical insight. LLMs, in contrast, can actively engage with content, suggesting interpretations and theoretical connections that move beyond simple coding assistance to a sophisticated analytical partnership.
When researchers “converse” with their data through LLMs, they can seamlessly move between empirical detail and conceptual abstraction. With carefully constructed prompts, researchers can encourage LLMs to generate provisional hypotheses, to compare and contrast thematic strands across datasets, or to suggest new lines of inquiry for further human-led analysis. As a result, the computational process becomes less about rote extraction and more about stimulating intellectual exploration and discovery.
This, therefore, does not mean that LLMs replace the interpretive acumen of the researcher, but rather supplements it in new and exciting ways. Still, the integration of LLMs into qualitative analysis demands a reconceptualization of the researcher’s role. Rather than delegating interpretive authority to the machine, successful implementation requires a hybrid approach where human insight and reflexivity guides and critically evaluates computational analysis (Li et al., 2024). The researcher remains central as the architect of inquiry, bringing theoretical sensitivity, methodological expertise, and ethical judgment to the analytical process. This human-AI partnership enables a sort of “three-way conversation” between researcher, data, and LLM, where each component contributes distinct capabilities to the analytical process. Just as a skilled interlocutor can push a researcher to consider new angles or challenge their assumptions, the LLM serves as an intelligent mediator helping surface how participants’ own words and experiences speak to particular research questions while remaining grounded in the datal itself. The researcher remains the sense-maker, testing the model’s suggestions against their broader disciplinary knowledge and the empirical realities under study.
Still, it is crucial to recognize the ethical and epistemological dimensions at play. LLM-driven analysis must be carried out transparently and responsibly. Researchers should clearly state when and how LLMs were used to analyze data and remain attentive to the potential biases and gaps encoded in these models. Efforts to ensure data privacy, to respect the rights and dignities of research participants, and to critically assess the model’s outputs remain essential. Moreover, the epistemic nature of the researcher-model interaction demands continual reflection on the boundary between computational suggestion and interpretive authority. How do LLMs’ capabilities complement or conflict with different theoretical or methodological traditions? What epistemic authority should we grant to AI-generated insights? The ability to intuitively converse with data can yield richer insights but also risks naturalizing the model’s outputs as self-evidently meaningful if not properly scrutinized.
Ultimately, “conversing” with data through LLMs represents an emergent methodological practice that resonates with the spirit of established qualitative traditions while leveraging advanced computational capabilities. Rather than settling for either laborious manual coding or reductive statistical topic models, researchers can begin to inhabit a hybrid space, engaging dynamically with their data at scale and depth. In doing so, qualitative inquiry can become both more efficient and more imaginative, encouraging new ways of understanding the social world.
In what follows, I present a framework that progresses from basic orientation to more creative exploration of qualitative data, demonstrating how LLMs can augment human interpretive expertise. Through an extended case study that analyses existing interview data, I illustrate how LLMs might be used at multiple levels of engagement.
What are LLMs—and Why are They Especially Suited for Qualitative Research?
Large Language Models (LLMs) are artificial intelligence systems designed primarily for understanding and generating human language. While various computational tools exist for analyzing text, LLMs are distinctive in both their architecture and their operation. They rely on deep neural networks that excel at handling sequences of text by leveraging so-called “attention” mechanisms (Devlin et al., 2019; Vaswani, 2017). Rather than just predicting the next word based on narrow statistical patterns, attention-based networks weigh contextual relationships across entire passages, allowing them to capture deeper semantic and syntactic dependencies that go beyond simple autocomplete functions. Through training on massive and diverse textual corpora (literally
This linguistic grounding is significant because qualitative research often relies on precisely these kind of data—words, phrases, narratives, dialogues, and texts—that LLMs are uniquely optimized to process. Traditional computational methods, such as Latent Dirichlet Allocation (LDA) and other topic modeling techniques, reduce language to statistical distributions of words across documents, identifying patterns in frequency and co-occurrence (Blei et al., 2003; DiMaggio et al., 2013). While such methods can illuminate structural regularities, their analytical granularity often stops at the word level. LLMs, by contrast, capture patterns across multiple layers of linguistic organization (Tenney, 2019). They can discern not just which words co-occur, but how phrases, sentences, and paragraphs interrelate, and how these relationships shift across contexts.
Through their deep learning architecture and extensive pre-training, LLMs develop what appears to be an intuitive grasp of language in much the same way humans learn to understand nuance and context—through massive and repetitive exposure to examples (Rogers et al., 2021; Wei et al., 2022). Just as a child learns that “yeah, right” often means the opposite of agreement, and “I’m fine” can mean very different things depending on tone and context, LLMs go through a similar semantic process, but at an enormous scale (Peters et al., 2018). This grants a unique ability to grasp complex linguistic features such as tone (detecting whether something is formal, casual, sarcastic, or sincere); cultural connotations (understanding idioms, specific phrases, and cultural touchpoints); contextual shifts (recognizing how the same words mean different things in different situations); and implicit meaning (understanding what’s suggested but not directly stated; to “read between the lines”)—among others.
This deep awareness of language enables modern “chat” models to engage in seemingly natural conversations that far surpasses a basic processing of text. LLMs can take everyday questions or instructions (called
Because language is the primary “raw material” of so much qualitative inquiry—whether in interviews, focus group transcripts, ethnographic fieldnotes, online forums, or historical documents—LLMs are naturally attuned to the textures and complexities that researchers seek to interpret. Their linguistic sensitivity extends to subtle aspects of discourse, such as metaphorical expressions, code-switching, distinctive genre conventions, or culturally specific idioms. Whereas traditional computational techniques must often rely on predefined dictionaries, stop-word lists, or topic priors, LLMs are able to adapt dynamically without any domain-specific examples or explicit rules for the particular analysis task at hand (known as “zero-shot”), drawing instead on their broad training to interpret content in context (Bender et al., 2024; Bommasani et al., 2021; Shanahan et al., 2023).
Such adaptability opens new avenues for qualitative analysis. Rather than treating language as a static artifact to be statistically decomposed, LLMs respond interactively. When a researcher prompts an LLM to highlight contradictions in a set of interview excerpts, to relate certain thematic patterns to sociological theories, or to generate hypotheses about underlying cultural meanings, the model transforms the traditional relationship between researcher and data in a fundamental way: here, situating micro-level textual details within macro-level theoretical frameworks. Researchers can move seamlessly between examining specific textual evidence and exploring its theoretical significance, using each level of analysis to inform and enrich the other. In short, LLMs can help researchers quickly move from broad surveys of thematic patterns toward more nuanced inquiries that reflect the complexity of human communication.
Beyond an intuitive and expert grasp of human language, LLMs’ extensive pre-training also affords them an extensive knowledge base (Pan et al., 2023). Indeed, LLMs integrate encyclopedic factual knowledge and gain domain expertise from their training data—which amounts, essentially, to ingesting the equivalent of the Library of Congress several times over, plus a significant portion of the public internet (Pezeshkpour, 2023; Roberts et al., 2020). This vast exposure to human knowledge and creativity allows them to recognize and engage with the almost limitless references to historical events, theoretical constructs, or disciplinary paradigms that inform the meaning of texts. Indeed, an LLM like ChatGPT has “read” far more extensively than even the most dedicated scholar could in a lifetime. While it is true that early instances of publicly available LLMs faced issues of “hallucinations” (i.e., plausible-sounding but factually incorrect or nonsensical information), subsequent advancements in fine-tuning and reinforcement learning have already significantly reduced these occurrences by aligning model outputs more closely with verified information and user intent (Liu et al., 2025).
Thus, if an analyst is developing, for instance, a conflict theory framework to help explain interview data collected from workplace disputes in a tech company, not only has it “read” Marx’s entire corpus along with both contemporary and modern interpretations & critiques, but also the state-of-the-art in organizational theory, tech industry analyses, and labor relations research. The model can draw from these diverse sources to suggest relevant, informed connections and interpretive frameworks, inclusive of both classical theory and cutting-edge applications (see: Cornelissen et al., 2024; Hau, 2024).
Despite their remarkable abilities, LLMs available today
From Basic Queries to Creative Exploration: Expanding the Researcher’s Toolkit
To demonstrate these methodological principles in practice, this section provides a detailed walkthrough of how LLM-assisted methods could be applied in practice. Drawing from a real-world research context, I analyze a dataset of ten semi-structured interviews chosen at random from a project uploaded to This phrase “publish or perish” is one of the most enduring expressions in academia. With the rise of audit culture in higher education it has been argued that academic value is increasingly becoming “monetised” and as a result academic values are being transformed…This dissertation addresses how audit culture in higher education is transforming the identities of academic scientists and influencing how the scientific identity is dependent on peer reviewed publications.
Basic Orientation
At an elementary level, researchers can use LLMs to swiftly orient themselves within large and complex datasets. Instead of manually skimming hundreds of pages, they might prompt the model to summarize a set of interviews or identify the most frequently mentioned concepts. Such initial queries lay the groundwork for more substantive analysis. The LLM can quickly reveal, for example, that a particular theme—such as organizational trust or environmental risk—is central to the dataset, suggesting where the researcher should devote greater attention. While these outputs are simple and descriptive, they save valuable time and help researchers approach subsequent steps with greater clarity.
The ten transcripts were uploaded to a publicly-available LLM, followed by this initial prompt and subsequent response (the LLM was not made aware of the abstract, only he project title).
2
Note that the LLM intuitively adopts a numbered list with bullet points format. Unless instructed otherwise, this pattern of output is likely to follow subsequent interactions that follow from this initial prompt:
• • • •
• • • •
• • • •
• • • •
• • • •
• • • •
• • • •
• ○ ○ ○ • ○ ○ ○ • ○ ○ ○ ○
Thematic Coding
Once familiar with the general contours of the data, researchers can move toward thematic coding tasks. LLMs can respond to prompts that ask for emergent themes, clusters of related excerpts, or inductive categorization without the researcher predetermining codes. Rather than starting from scratch, a scholar might say, “Group these passages based on the issues they discuss,” allowing the model to suggest an initial coding framework. This provides a useful scaffolding on which the researcher can build a more nuanced, theory-driven coding scheme. The advantage here is efficiency and inspiration: the LLM can surface overlooked patterns, spurring the researcher to refine and enrich the initial categories.
Code Analysis Table.

CODEBOOK:
Comparative Analysis
To dig deeper, the researcher can leverage the LLM’s contextual sensitivity to compare textual subsets. Perhaps some interviews are from experienced professionals, others from novices, or perhaps documents were created before and after a policy change. With prompts like “Compare how early-career and senior participants discuss professional challenges,” the LLM can highlight differences in tone, emphasis, or conceptual framing. This comparative capability encourages a more dynamic, relational approach to data analysis, helping researchers discern shifts in discourse over time, variations across demographic groups, or contextual contrasts between data subsets.
Note at this point in the response below, the LLM does make two small errors in misattributing (actual) quote excerpts to the wrong participant interview (marked in the transcript below). While not as common as they have been in the past, these errors that still occur likely stem from LLMs’ tendency to rely on patterns and similarities across texts, which can sometimes cause it to misidentify the source of a statement, especially when participants discuss similar themes or use overlapping language. Such mistakes underscore the importance of maintaining rigorous human oversight, cross-referencing the LLM’s outputs with original data, and ensuring that attributions are accurate to preserve the integrity of the analysis (Pangakis et al., 2023).
• • •
• • •
• • •
• • •
• • •
• • •
(is actually P10, Reader)
• • •
• • •
• • •
• • F •
• • 2. • •
• •
• •
These differences reflect not just career stage, but also the changing nature of academic science and publishing over time. Senior academics often reference how the system has changed since their early careers, while ECRs are navigating a more metric-driven, competitive environment from the start.
Relating Data to Theory
A next level of sophistication involves asking the LLM to connect identified patterns to theoretical frameworks or established scholarly concepts. Researchers might prompt the model to interpret certain themes through the lens of cultural capital, social network theory, or framing theory. By asking, “Which patterns align with the concept of ‘moral panic’ in sociology?” the researcher spurs the LLM to offer a close and critical theory-informed reading. While the model’s suggestions do not replace the researcher’s expertise, they can serve as intellectual catalysts, nudging the scholar to consider theoretical perspectives they may not have initially thought of. This step encourages a dialogue between data-driven themes and conceptual constructs, ultimately broadening the analytical repertoire.
• • •
• • •
• • •
• • •
• • •
• • •
• • •
• • •
• • •
• • • •
• • • •
Interrogating Internal Dynamics
As the analysis deepens, LLMs can be prompted to identify contradictions, tensions, or evolving narratives within the corpus. For instance, a researcher might say, “Point out any contradictions in how Participant A discusses institutional trust across these three interviews.” Here, the model’s capacity for textual coherence allows it to locate subtle shifts in a single speaker’s stance or to highlight internal inconsistencies in official documents. By foregrounding these internal dynamics, the researcher gains richer interpretive opportunities, moving beyond surface-level themes to the complexities that often characterize qualitative data.
Note at this point, as well, that the prompting strategy becomes more specific, and cautions the LLM to be careful to analyze each transcript in isolation. This is because LLMs, when allowed to process multiple documents simultaneously, may inadvertently conflate distinct contexts or attribute statements from one interview to another. Such errors can arise from their tendency to generalize patterns or infer connections wherever they may exist, potentially leading to misinterpretations of the researcher’s intention. By isolating each transcript, the researcher mitigates the risk of the model introducing errors, ensuring that its analysis respects the unique situational contexts of each piece of data and avoids creating artificial consistencies or conflicts.
These patterns suggest that contradictions often emerge where individual values conflict with institutional requirements or career necessities.
Another possibility is to check for unique cases or outliers among the data. By surfacing outliers, the LLM highlights cases that may offer unique insights or challenge prevailing interpretations, enabling the researcher to explore exceptions that could deepen theoretical understanding or uncover overlooked complexities.
These outliers are significant because they represent opposing responses to institutional pressures - active resistance versus detached acceptance - compared to the more pragmatic navigation described by other participants.
Scenario Testing & Hypotheticals
When researchers reach a point where they seek inspiration and intellectual playfulness, they can ask the LLM to imagine hypothetical scenarios or counterfactual situations. Questions like “How might these discussions differ if participants were in a different cultural context?” invite the model to generate plausible but speculative narratives. These hypothetical exercises can stimulate creativity, uncover implicit assumptions, and broaden the researcher’s conceptual horizons. By taking the inquiry beyond what is present in the data to what could be (or could have been), the researcher can set up novel comparisons, refine their analytical questions, challenge their assumptions, and open new avenues for future studies.
For this prompt, adding “Keep it to a short summary” also informs the LLM that the response should be less comprehensive here compared to prior responses.
Creative Synthesis & Prompting Further Inquiry
At an advanced level, researchers may treat the LLM as a conversational partner that can propose new research questions, adopt alternative theoretical lenses, or synthesize patterns into novel analytic frames. A prompt might read, “Adopt the lens of feminist social theory and reinterpret these data—what stands out now?” By guiding the model to “speak” in a particular analytic voice, the researcher can discover angles, arguments, or inquiries that might otherwise remain dormant. This capability moves the relationship from tool-assisted coding to genuine intellectual co-exploration, sparking unexpected insights and promoting methodological innovation.
This lens reveals how seemingly neutral academic practices may actually reproduce gendered power relations and suggests the need for structural changes to create more equitable academic environments.
Analysts can also query the LLM to mine for subtleties, nuance, and underrepresented perspectives that may be contained in the data, but which are overshadowed by more dominant narratives, themes, or tropes.
These nuances suggest deeper structural and psychological dynamics than initially apparent.
Reflexive Engagement
Finally, researchers can leverage LLMs to foster reflexivity about their own role and biases. Prompts might include, “Suggest ways to challenge my initial coding scheme to ensure a more balanced analysis,” encouraging the model to highlight potential blind spots or propose corrective strategies. The LLM’s ability to reflect on analytical process—albeit without true self-awareness—can still prompt scholars to become more methodologically rigorous. By making it easier to consider alternative interpretations or acknowledge potential oversights, this level of engagement helps maintain the integrity and trustworthiness central to qualitative research.
This revision enables analysis of structural power dynamics previously invisible in the original coding scheme.
Some More Unconventional Uses of LLMs in Qualitative Inquiry
As researchers gain confidence and skill in conversing with their data through LLMs, the horizon of possibilities expands well beyond thematic coding or theoretical exploration. Venturing into more creative and transdisciplinary territory, researchers can treat LLMs as collaborative partners that generate new modalities of analysis, visualization, and even synthesis across media and methods. By prompting the model to produce instructions, code, or conceptual outlines, researchers can orchestrate entire workflows that turn static texts into dynamic, multifaceted research artifacts.
For instance, prompting the LLM to produce storyboards, prompts, or descriptive outlines, researchers can feed these outputs into image generators or other multimodal AIs. “Describe a symbolic image that captures the tension between institutional trust and individual autonomy” might yield a concept that, when given to an image-generation model, produces evocative visuals that accompany the analytic narrative (Figures 1 and 2).
Example visualization. Text-to-Image Generation. 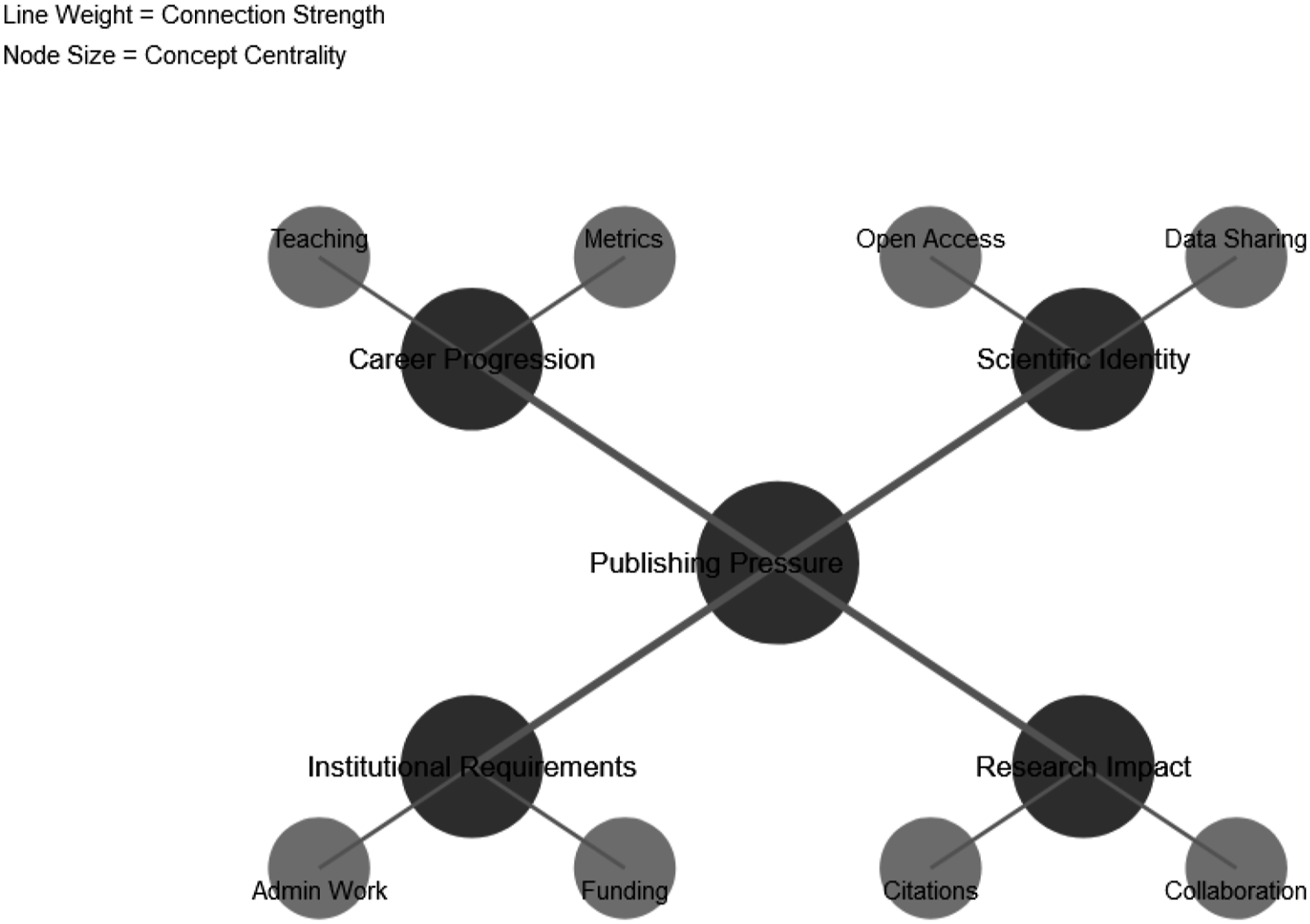

LLMs can serve as a readily accessible methodological consultant and on-the-fly software coder. Asking, “write Python code to scrape social media feeds from Instagram” yields snippets that researchers can adapt and then execute for their data collection needs. Beyond code generation, LLMs can further explain methodological choices, suggest best practices for data handling, and help troubleshoot common technical issues (Siiman et al., 2023). This capability extends to statistical analysis, where LLMs can recommend appropriate analytical approaches and generate corresponding code implementations—or even take in and analyze code using an internal Python environment.
Beyond expanding the methodological toolkit in novel ways, LLMs can facilitate theoretical triangulation through structured dialogic exercises (Christou, 2023). The LLM can stage debates among theoretical perspectives, offering dialogic texts that animate the data. By prompting, for instance, “Craft a conversation where a Bourdieusian cultural theorist, a symbolic interactionist, and a critical race scholar debate these findings,” the researcher gains a meta-theoretical lens, stimulating intellectual play and potential interdisciplinary insight.
Murmurs of Reluctant Agreement
With careful prompting, LLMs can even produce “synthetic respondents” who mimic the style, concerns, and discursive patterns present in the original corpus. AI-generated synthetic data is already being taken seriously in quantitative domains (see: Raghunathan, 2021). In healthcare studies, for instance, synthetic patient records help researchers develop and validate analytical methods while maintaining confidentiality and adhering to regulations like HIPAA (Giuffrè & Shung, 2023). Financial institutions today use synthetic transaction data to test pricing models for assets in illiquid markets where real transaction data is sparse; and banks with fraud detection algorithms to explore suspicious patterns without compromising individual privacy (Selvaraj et al., 2022).
This quantitative precedent suggests promising applications for qualitative research. Just as synthetic quantitative data preserves statistical properties while obscuring individual identities, synthetic qualitative responses can maintain thematic patterns and discursive styles within small data sets, while protecting participant anonymity. Researchers might generate synthetic interview responses to expand their analytical scope by creating theoretically-informed variations of existing responses that help identify pattern boundaries and test theoretical assumptions; to explore how emerging themes could manifest across different contexts or demographics; or to test the robustness of their coding frameworks. For example, “Generate a persona who speaks in a manner similar to Participant C, but who addresses an emerging policy issue not covered in the original interviews.” This can help researchers explore potential responses in evolving social contexts or test how concepts might be articulated if new circumstances arose.
However, this practice demands careful ethical and methodological caution. Synthetic respondents blur the boundary between empirical evidence and AI-generated content. They must be transparently labeled and never misrepresented as genuine participants. Ethically, researchers must ensure that these synthetic voices do not distort real perspectives, mislead audiences, or violate participants’ confidentiality and dignity. Instead, they serve as analytical tools that complement traditional data collection methods, much as synthetic quantitative data supplements rather than supplants actual observations. When used responsibly, they can serve as a thought experiment—an analytic sandbox that prompts researchers to contemplate alternative scenarios and refine their interpretive frameworks.
Ethics, Bias, and Standards of Practice
Integrating Large Language Models (LLMs) into qualitative research frameworks raises fundamental ethical and methodological challenges. While these tools can enhance analysis, researchers must remember that LLMs do not possess true understanding or intentionality (Bender et al., 2024; Bommasani et al., 2021). Regardless of how sophisticated or insightful their outputs are, LLMs nevertheless produce contextually plausible text based on patterns gleaned from their training data, not from any genuine comprehension of meaning or social reality. In this context, human researchers bear full responsibility for interpretation, ensuring that the outputs align with ethical standards and the goals of scholarly inquiry.
Inherent Bias in Training Data
One concerning issue arises from the fact that LLMs tend to produce outputs grounded in countless texts that tend to reflect dominant viewpoints. If the training data predominantly represents a certain cultural stance, other interpretations or marginalized voices might be overlooked (Liu, 2024). These biases could manifest in subtle ways—highlighting certain types of viewpoints while sidelining others, or describing certain groups’ concerns as peripheral or “irrational.” In qualitative research that seeks to uplift underrepresented communities, this epistemic imbalance could replicate colonial or hegemonic narratives. Critical AI scholars and decolonial theorists have warned that uncritical AI use can reinforce imperial epistemologies, making it harder for non-dominant knowledge systems to emerge (Gebru, 2019). Indeed, high-profile controversies have shown that algorithmic systems, even without AI, can perpetuate racialized, gendered, and classed biases (Benjamin, 2019; Noble, 2018). This has clear implications for qualitative inquiry, so researchers must remain vigilant about biases in the model’s responses.
These potential biases are serious, but they are neither inevitable nor impossible to mitigate. To be sure, LLM outputs reflect learned data patterns rather than deliberate malice (see: Guo et al., 2024; Rozado, 2023). As a result, researchers should first and foremost explicitly prompt models to consider alternative perspectives and marginalized viewpoints when analyzing such data, and iterate as needed (Nazer et al., 2023). For instance, when analyzing interview data about urban development, researchers might prompt: “Examine how different socioeconomic groups discuss neighborhood change, paying particular attention to perspectives that might be underrepresented in mainstream discourse,” or “Identify patterns in how residents from different ethnic backgrounds describe their experiences with community planning processes, ensuring equal attention to all community voices.”
Second, validation processes should include diverse stakeholders who can identify potential blind spots or problematic assumptions in the model’s interpretations. Compare LLM outputs with manual coding, community consultations, or alternative data sources. And third, researchers should document instances where outputs appear biased and report them to LLM creators. Already, OpenAI, the parent company of ChatGPT, updates and fine-tunes models with debiasing techniques based, in part, on user feedback (OpenAI et al., 2024).
Data Privacy
Data privacy is another potential concern that might arise if researchers upload identifiable transcripts into external LLM interfaces. A breach or unauthorized use could expose sensitive participant information. High-profile tech scandals and data leaks (as covered by major media outlets) illustrate that even well-meaning platforms can fail at data protection. In a qualitative context, this might mean that participants’ trust is betrayed, undermining ethical commitments and potentially causing harm to vulnerable individuals.
Researchers already have robust tools to handle data responsibly. Techniques like anonymization, pseudonymization, and strict adherence to IRB protocols are standard in qualitative research and remain effective in the LLM era. Researchers can also download and deploy standalone LLMs in secure, on-premise environments, ensuring data never leaves their institutional control.
Authenticity, Transparency, and Intellectual Honesty
Because LLMs can produce text that closely resembles human speech, there’s a risk that researchers might conflate AI-generated content with genuine participant perspectives. Deliberate misuse (e.g., presenting synthetic respondents as real data) or neglecting to clarify the origin of certain narratives could damage scholarly credibility. The rise of “deepfakes” and AI-generated misinformation (Chesney & Citron, 2019) has heightened awareness of how convincingly AI can sometimes mimic authenticity. In qualitative inquiry, this could result in misleading conclusions and a breakdown of trust between researchers, participants, and audiences.
Transparent documentation—clearly indicating which insights came from participants and which stemmed from AI interpretation—helps maintain intellectual honesty. Beyond maintaining basic logs of chat interactions, researchers should implement comprehensive documentation protocols that detail their entire analytical process. This includes archiving prompt sequences, recording decision rationales, and maintaining version controls for evolving analyses. These materials should be deposited in publicly-available repositories with permanent URL links or DOIs, ensuring long-term accessibility and reproducibility. Peer review, editorial oversight, and community scrutiny further reduce the likelihood of deceptive practices.
Practical Limitations
In addition to these ethical concerns, there are also certain technical and practical limitations to keep in mind. LLM platforms typically have a maximum “token” capacity (i.e., the maximum number of words or symbols they can process and remember at one time), meaning they can handle only so much text in a single session. If researchers upload texts that exceed this limit, the model may lose context or ignore parts of the data. In this way, the model’s short-term “memory” within a conversation can sometimes overlook earlier content if the chat history grows too long. Moreover, many online chat-based LLMs have periodic usage limits that restrict users to a certain number of discrete interactions before requiring a paid subscription upgrade or imposing waiting periods (even for subscribers). While LLMs are constantly improving their token capacity, to address current limits, researchers can break large data sets into smaller, thematically cohesive chunks—ensuring the model remains focused and able to handle the text without discarding contextual cues.
Prompt design likewise should be adjusted so each query is targeted to produce a desired output (e.g., “Analyze recurring references to social hierarchy in these three paragraphs” vs. “Analyze these paragraphs”). Vague or overly broad prompts often yield generic responses that lack analytical depth. Instead, researchers should craft specific, focused queries that guide the LLM toward the particular aspects of the data they wish to explore (Shah, 2024).
Effective prompts typically include context about the research objectives, specific analytical tasks, and clear parameters for the desired output format. This specificity serves multiple purposes. It helps ensure the LLM’s response aligns with research objectives, makes the analytical process more transparent and reproducible, and enables more systematic documentation of the researcher’s decision-making process. Moreover, detailed prompts cna create clearer audit trails for other researchers who might wish to understand or replicate the analysis.
Conclusions: Bringing the Human Back in
Qualitative research often operates on the premise that social reality is actively shaped by how people interpret, negotiate, and assign meaning to their lived experiences. Interpretivist scholars emphasize the researcher’s role in co-creating these understandings through direct engagement, reflexivity, and attention to participants’ viewpoints. Constructivist traditions similarly foreground the ways individuals and groups develop shared understandings of the world, seeing reality as a product of social processes and interactions (Burns et al., 2022).
Introducing LLMs—a system devoid of personal or cultural experiences—into these traditions raises questions about how interpretation occurs and who (or
In a constructivist sense, the researcher’s active role in co-constructing meaning might, too, risk being sidelined if LLMs are perceived as “neutral experts.” This perception could inadvertently privilege machine-generated interpretations over the careful, context-sensitive meaning-making that emerges through human interaction and reflection. Yet, constructivist scholars might see an opportunity: each LLM output can be treated as an interpretive “draft” that the researcher refines through a human lens, drawing on theoretical frameworks, field knowledge, or participants’ own insights. In doing so, LLMs become a catalyst for deeper investigation rather than a one-click solution. The danger lies not in using LLMs as analytical tools, but in potentially overvaluing their outputs or mistaking their pattern recognition capabilities for genuine understanding.
When used thoughtfully, LLMs can expand our perspectives rather than replace them. They can quickly assign thematic codes, conduct pattern recognition, or contrast different viewpoints on a topic, leaving the researcher to decide how these insights align with—or challenge—existing interpretive frameworks. As things still stand, only human analysts can connect textual cues to experiential knowledge—knowledge that extends beyond language to the broader social world. As a result, LLMs can amplify human capabilities—especially at early stages, such as organizing large datasets or surfacing potential themes—while the deeper interpretive and cultural insights often remain the domain of the human qualitative researcher.
Thus, the researcher stays in charge. Rather than a self-contained “analysis machine,” the LLM functions as a prompt-driven assistant that catalyzes new lines of thought through dynamic back-and-forth “conversation” with their qualitative data. Researchers apply their own theoretical lens when deciding which prompts to use, how to incorporate the model’s suggestions, and whether those suggestions hold up under critical examination. Through constant reflection on what is gleaned from the LLM, and where the researcher’s own expertise and skill is needed, it becomes possible to harness AI insights without undermining the foundational values of rich, human-centered qualitative inquiry.