
Abstract
Keywords
Memory researchers frequently need to assemble specific stimulus sets when assessing predictions of various theories. For example, they might want a set of abstract words and a corresponding set of concrete words, or a set of high-frequency words and a corresponding set of low-frequency words. One well-known concern is that as the size of the stimulus set gets smaller, it becomes increasingly more likely that idiosyncratic properties of the particular words can influence performance and that the results may not generalise to other stimulus sets (e.g., Bireta et al., 2006; Caplan et al., 1992; Lovatt et al., 2000; Neath et al., 2003). In this article, we report a series of experiments that examine whether an unusual finding reported by Greeno et al. (2022) about the effect of set size on the neighbourhood size effect in serial recall generalises to other stimulus sets.
There are several different definitions of what constitutes an orthographic or phonological neighbour of a target word. One widely used definition of an orthographic neighbour is Coltheart’s
The neighbourhood size effect refers to the finding that words which have a large number of orthographic or phonological neighbours are better recalled on immediate memory tests than otherwise comparable words which have fewer neighbours (e.g., Allen & Hulme, 2006; Clarkson et al., 2017; Derraugh et al., 2017; Guitard et al., 2018; Jalbert, Neath, Bireta, & Surprenant, 2011; Jalbert, Neath, & Surprenant, 2011; Roodenrys et al., 2002). As can be seen in Table 1, these studies have used stimulus sets that vary in size from small to large.
The size of word pools used in neighbourhood size experiments, the mean number of orthographic neighbours in the large and small conditions, and performance measures.
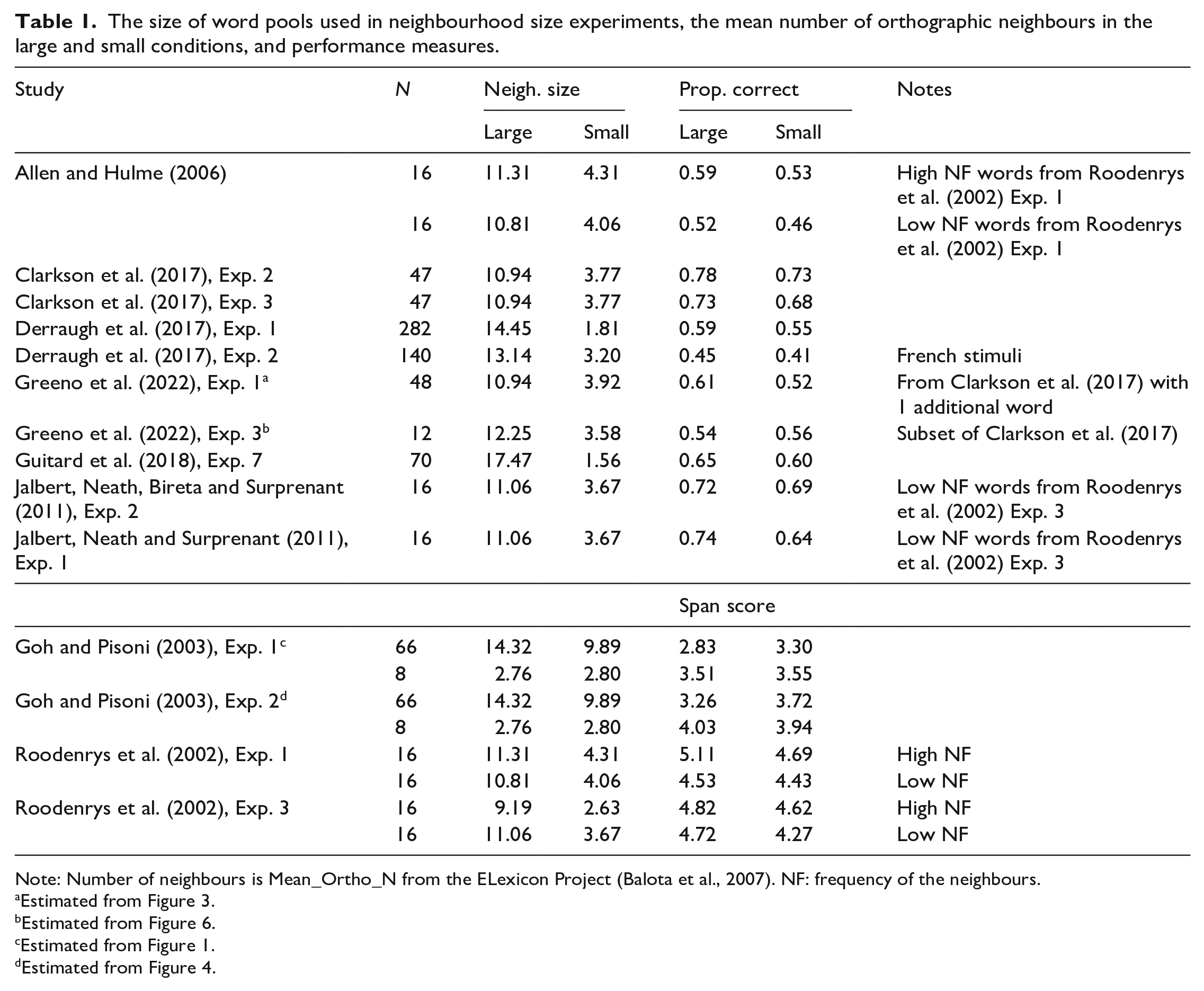
Note: Number of neighbours is Mean_Ortho_N from the ELexicon Project (Balota et al., 2007). NF: frequency of the neighbours.
Estimated from Figure 3.
Estimated from Figure 6.
Estimated from Figure 1.
Estimated from Figure 4.
One commonly invoked account of the beneficial effect of neighbourhood size derives from Roodenrys (2009) and focuses on redintegration. The idea is that after presentation, the degraded cues representing the items can serve as input to an interactive network. Each cue partially activates or primes its neighbours. A word with more neighbours, such as
There are other theories of short-term memory that would suggest the effect of neighbourhood size does not just influence processes operating during recall. For many years, some have argued that verbal short-term memory makes use of structures and processes inherent in the comprehension and production of speech (e.g., Martin et al., 1999). These psycholinguistic accounts of short-term memory have varied from arguing that memory tasks rely entirely on co-opted language processes (e.g., Schwering & MacDonald, 2020) to arguing that they make use of linguistic representations of the words, along with additional attentional processes to maintain the novel order of the lists of words (e.g., Majerus, 2013). In either case, variation in activation between different linguistic representations might be expected to occur from the time of presentation onwards. Thus, the neighbourhood size effect may reflect differential activation across the entire task rather than just at retrieval.
There are some manipulations which reduce or abolish the neighbourhood size effect. For example, Jalbert, Neath, Bireta and Surprenant (2011) manipulated whether the lists were pure (i.e., contained only large or only small neighbourhood words) or mixed (i.e., contained both large and small neighbourhood words). A neighbourhood size effect was found for pure lists but not for mixed lists, a result replicated by Jalbert, Neath and Surprenant (2011) and Clarkson et al. (2017). Neighbourhood size is thus like a number of other memory results that differ as a function of pure or mixed lists (e.g., the generation effect; Serra & Nairne, 1993). As a second example, Jalbert, Neath and Surprenant (2011) showed that concurrent articulation eliminates the neighbourhood size effect, similar to the elimination of the acoustic similarity effect (e.g., Murray, 1967).
As can be seen in Table 1, there are two papers which reported
The second experiment that found a
Excluding the Goh and Pisoni (2003) stimuli for the reasons noted earlier, Table 1 indicates that four different large stimulus sets have been used, all of which resulted in a typical large neighbourhood advantage (Derraugh et al., 2017, Exps. 1 and 2; Clarkson et al., 2017; and Guitard et al., 2018). In contrast, only three small stimulus sets have been used. Roodenrys et al. (2002) had two small sets, and these were also used by Allen and Hulme (2006), Jalbert, Neath, Bireta and Surprenant (2011), and Jalbert, Neath, and Surprenant (2011). The third is the small set used by Greeno et al. (2022). The two sets from Roodenrys et al. both produced a large neighbourhood advantage, whereas the one set from Greeno et al. produced a small neighbourhood advantage. As Greeno et al. (2022, p. 13) noted, one issue with small stimulus pools is that the effects produced may be due to idiosyncratic properties of the small number of words tested. One example of an idiosyncratic small stimulus set concerns the time-based word length effect. Baddeley et al. (1975, Exp. 4) used a small, fixed set of items that were equated for number of syllables and number of phonemes but differed in pronunciation time. They found better recall of the words that could be said faster. There are a large number of studies that have used the same stimuli and have obtained the same results; however, there exists no other set of stimuli that show the same results (for a review, see Neath et al., 2003). A second example concerns the much more strongly supported syllable-based word length effect whereby lists composed entirely of words with fewer syllables are better recalled than lists of words with more syllables (but see Guitard et al., 2018, for a discussion of whether this effect is actually driven by the number of syllables). Cowan et al. (2003) found that lists that contained 3-short and 3-long words were recalled worse than lists of 6-short words but better than lists of 6-long words. This result is replicable when using their small stimulus set, but a different result obtains with other stimulus sets (Bireta et al., 2006; Hulme et al., 2004).
Greeno et al. (2022) used one small set of words for all subjects. An alternative method is to randomly sample 12-large and 12-small neighbourhood words from a larger pool for each subject. The result is that each person receives a small set of words, but on average, each person will have a different subset. The advantage of using randomly generated pools is that it minimises the probability of unwanted systematic differences: although by chance there may be such an idiosyncratic set of items for one subject, it is highly unlikely any other subject will have the same variation. This method was used by Neath and Surprenant (2019) to demonstrate that other semantic effects are observed in serial recall even when the same six items are shown on every trial.
Below we report the results of three registered experiments. Experiment 1 used the same large pool of stimuli used in Experiment 1 of Greeno et al. (2022) and the prediction is that the standard neighbourhood size effect will be observed, with better recall of large than small neighbourhood words. Experiment 2 used the same small pool of stimuli used in Experiment 3 of Greeno et al. and a reverse neighbourhood size effect is expected. These two experiments, then, should replicate the results reported by Greeno et al. Experiment 3 was identical to Experiment 2 except that the small pool of stimuli was randomly generated for each subject by drawing from the larger pool in Experiment 1. This methodology provides a much stronger test of the neighbourhood effect with small stimuli pools. In this experiment, if a reverse neighbourhood size effect is observed, then set size is critical. If a standard neighbourhood size effect is observed, then Greeno et al.’s results may be attributed to idiosyncratic properties of the stimulus set tested.
Experiment 1
Experiment 1 was based on Experiment 1 of Greeno et al. (2022) but with the following differences: (a) Greeno et al. manipulated presentation modality (auditory and visual), but because they reported no interactions between modality and neighbourhood size, we used only visual presentation. (b) Greeno et al. used spoken recall whereas we used typed recall given the use of an online subject sample. (c) Greeno et al. showed the visual items for 350 ms followed by a 650 ms blank screen. The rate is thus 1 item per second but the item is not visible for the entire time. The reason was to match the presentation rate of the visual items to that of the auditory items, each of which lasted 350 ms. Because we were not using auditory presentation, we used a fixed rate of 1 item per second and the item remained visible for the full 1 second. (d) Greeno et al. had 24 lists per condition; we had 12 lists per condition to keep the experiment short to minimise fatigue and the amount of typing required. (e) Greeno et al. had 30 subjects whereas we had 50 subjects. The reason for the increase in the sample size is because of different power analyses. Greeno et al. performed their power analysis on detecting an interaction between modality and neighbourhood size based on previous studies. In contrast, we based our power analysis on detecting a main effect of neighbourhood size based on the visual condition in their Experiment 3.
Ethics
The experiments were approved by the Virginia Tech institutional Review Board (IRB).
Subjects
Fifty volunteers from Prolific participated and were paid £8.50 per hour (pro-rated). The inclusion criteria for all experiments were (a) native speaker of English; (b) age between 19 and 39; (c) an approval rating of 90 or higher on pervious Prolific experiments; and (d) normal or corrected to normal vision. The sample size was determined by a power analysis using Superpower (Version 0.2.0, Lakens & Caldwell, 2021) with estimates based on the first 12 trials of the visual condition of Experiment 3 of Greeno et al. (2022). The mean age was 32.32 years (
Stimuli
The stimuli were the same as in Experiment 1 of Greeno et al. (2022).
Design
The experiment was a 2 neighbourhood size (large vs. small) × 6 serial position within-subjects design.
Procedure
After reading an informed consent form and agreeing to participate, the subjects were reminded of the instructions. A trial began when the subject clicked on a button labelled “Start next trial.” Six words were randomly drawn without replacement from the appropriate pool (i.e., large or small neighbourhood size) and were shown one at a time for 1 s in the centre of the screen in 28 point Helvetica. After the final word had been shown, a message appeared prompting the subject to type in the first word. The instructions emphasised the importance of typing the first word first, the second word second, and so on. The instructions encouraged guessing but also indicated that the subject could click on a button labelled
Results and discussion
The data were analysed using both frequentist and Bayesian analysis of variance (ANOVA) using JASP (JASP Team, 2022). For the former, noninteger degrees of freedom indicate the Geenhouse-Geisser sphericity correction has been applied. For the latter, we report either a Bayes factor, BF10, that indicates evidence for the alternative hypothesis or a Bayes factor, BF01, that indicates evidence for the null hypothesis. We interpret a value between 3 and 10 as indicating substantial evidence; a value between 10 and 30 indicating strong evidence; values between 30 and 100 indicating very strong evidence; and values greater than 100 indicating decisive evidence (Wetzels et al., 2011).
The proportion of words correctly recalled was analysed by a 2 neighbourhood size (large vs. small) × 6 serial position repeated measures ANOVA.
3
There was a significant main effect neighbourhood size,

Proportion of large and small neighbourhood words correctly recalled in order as function of set size.
Error analysis
We analyse two types of item errors. An omission error is when a word from the list is not reported, whereas an intrusion error is when a word that was not in the list is reported. We also analyse order errors. An order error is when a word from the list is recalled in the wrong serial position; however, the raw number of order errors is misleading because it can vary with overall level of recall. For example, if three items from a six-item list are recalled, the maximum number of order errors is three, whereas if five of the six items are recalled, the maximum is five. To control for different numbers of opportunities for an order error, the number of order errors is divided by the number of items recalled in any position (Murdock, 1976; Saint-Aubin & Poirier, 1999).
There were more errors of each type in the small than in the large neighbourhood size condition. The proportion of intrusion errors was 0.171 (
Despite the many minor changes, Experiment 1 replicated the main results of Experiment 1 of Greeno et al. (2022). In particular, more large than small neighbourhood words were correctly recalled in order, and there were more conditionalized order errors for small than large neighbourhood words. In addition, Experiment 1 found more omission and intrusion errors for small than for large neighbourhood words.
Experiment 2
Experiment 2 was based on Experiment 3 of Greeno et al. (2022). The sole change from Experiment 1 is that instead of using a large pool of stimuli, Experiment 2 used a subset of 12 large and 12 small neighbourhood size words.
Subjects
Fifty different volunteers from Prolific participated. The mean age was 30.46 years (
Stimuli
The stimuli were the 12-large and 12-small neighbourhood size words used in Experiment 3 of Greeno et al. (2022).
Design
The design was the same as in Experiment 1.
Procedure
The procedure was identical to Experiment 1 except for the stimuli. As a small pool was used, each pool was depleted after two trials of that stimulus type. When this occurred, the pool was replenished. Each word appeared six times in the experiment.
Results and discussion
The proportion of words correctly recalled was analysed by a 2 neighbourhood size (large vs. small) × 6 serial position repeated measures ANOVA.
6
The main effect of neighbourhood size was not significant,
Error analysis
There were no differences in errors, although the Bayes factors did not offer much support for the null hypothesis. The proportion of intrusion errors was 0.163 (
Experiment 2 did not replicate Experiment 3 of Greeno et al. (2022). Greeno et al. reported better recall of small than large neighbourhood words, whereas there was no difference in this experiment; the Bayes factor indicated strong evidence in favour of the null hypothesis. However, the null results for order errors does replicate their finding. We discount differences in methodology as an explanation for the different outcome, given that our Experiment 1 replicated Experiment 1 of Greeno et al. We postpone further discussion until after presenting Experiment 3.
Experiment 3
Experiment 3 was identical to Experiment 2 except for the stimuli. Experiment 2 may be described as having a
Subjects
Fifty different volunteers from Prolific participated. The mean age was 30.12 years (
Stimuli
The stimuli were 12 large neighbourhood size words and 12 small neighbourhood size words randomly drawn, for each subject, from the larger pool used in Experiment 1.
Design
The design is the same as in Experiments 1 and 2.
Procedure
The procedure is identical to Experiment 2 except that the 12 large and 12 small neighbourhood size words were randomly determined for each subject.
Results
A 2 neighbourhood size (large vs. small) × 6 serial position repeated measures ANOVA revealed a significant main effect of neighbourhood size,
Error analysis
There were numerically more errors of each type in the small than in the large neighbourhood size condition, but not all were statistically different. The proportion of intrusion errors was 0.138 (
The results of Experiment 2 and 3 are very different: The small fixed pool in Experiment 2 resulted in no difference between small and large neighbourhood words whereas the small random pool in Experiment 3 resulted in the usual large neighbourhood advantage.
General discussion
The neighbourhood size effect has played an important role in the development of memory models and helps to further our understanding of basic human processing. For instance, the neighbourhood size effect is directly linked to Roodenrys et al. (2002) account of the complex interaction between the presented information and the redintegration of that information, which is widely incorporated in key hypotheses and simulation models of human memory. However, until the work of Greeno et al. (2022), the demonstrations of a neighbourhood size effect with small stimulus pool, on which the redintegration account of Roodenrys et al. (2002) was built, was restricted to the original stimuli. The results of Greeno et al., showing a detrimental effect of neighbourhood size, pose major challenges for memory models. The three registered experiments reported here demonstrate that the particularity of the Greeno et al. small pool was the key factor driving these results.
More exactly, the results of the experiments overall are clear and can be summarised as follows. Experiment 1, using a large pool, and Experiment 3, using a small pool, both found typical neighbourhood size effects with a better serial recall of words with large neighbourhoods than words with small neighbourhoods, using both frequentist and Bayesian statistics. In addition, Experiment 2, which used the same small pool as used by Greeno et al. (Experiment 3), found no effect of neighbourhood size. The difference between Experiments 2 and 3 is that in the former, all subjects received the same small pool whereas, in the latter, the small pool was determined randomly for each subject. Experiment 3 provides a further demonstration of a neighbourhood size effect with a small set size.
Additional evidence consistent with our results comes from neighbourhood size manipulations with nonwords. In this case, a nonword such as
There is one methodological difference between Experiment 2 here and Experiment 3 of Greeno et al. (2022), which is that Experiment 2 used typed recall instead of spoken. It seems unlikely that this is an important factor and should not challenge the interpretation of the results for a number of reasons. First, there was no difference between the results of Experiment 1 here, which used typed recall, and Experiment 1 of Greeno et al., which used spoken recall. Both of these experiments used a large pool, and replicate previous work using spoken (e.g., Roodenrys et al., 2002) and typed recall (e.g., Guitard et al., 2018), and there is no a priori reason why set size might interact with response modality. Second, Experiment 3 (here) used a small pool, but each set was randomly generated for each subject. This resulted in the same pattern of results observed in Experiment 1 (here), suggesting that the neighbourhood effect is present for small and large set sizes in this response mode. Third, there are many demonstrations in the literature that other effects in serial recall occur with either written or typed responses. For example, Saint-Aubin et al. (2020) found a large effect of word length in both spoken and typed recall, strong phonological similarity effects are found in written (e.g., V. Coltheart, 1993) and typed recall (e.g., Roodenrys et al., 2022), and Beaudry et al. (2018) found similar effects in spoken and written recall of imageability and word frequency. Ultimately, this is an empirical question, but based on the above, our prediction is that if Experiment 3 (here) were run with spoken recall, a neighbourhood size effect would still obtain.
Although it is apparent that the unusual set of stimuli is the small pool used by Greeno et al. (2022, Experiment 3), it is not entirely clear how they differ from other sets. One possibility is the distribution of phonemes within the words. Greeno et al. (2022) go to some lengths to justify the selection of the 12 items for each condition in their Experiment 3, including ensuring the two sets of stimuli have “the same dispersion of phonologically similar onset consonants” (p.9). However, an examination of their stimuli reveals they are equated on the initial letter of the word but not the initial phoneme. In the large neighbourhood set four words start with a hard “c,” whereas in the small neighbourhood set only one has a hard “c” pronunciation. Such differences in phonological overlap within sets may be important. Similarly, analysis of phonological similarity with Psimetrica (Phonological Similarity Metric Analysis, Mueller et al., 2003) indicates the mean pairwise similarity of onset phonemes was greater in the large neighbourhood set.
One other point to note is that the current research focussed on serial recall and not serial recognition. Experiment 2 of Greeno et al. (2022) found that using the same large set of stimuli as in their Experiment 1, there was no effect of neighbourhood size in serial recognition. To our knowledge, there are no other published studies that examine whether neighbourhood size effects occur in serial recognition, but even if the null effect of Greeno et al. is replicated, the lack of effect is not particularly surprising or noteworthy. The reason is that a number of lexico-semantic effects that are robust with serial recall are known to be absent with serial recognition. Of particular interest, Chubala et al. (2019) used a procedure in which subjects did not know whether they would receive a serial recall or a serial recognition test until after the list had been presented. For the serial recall test, they found the usual effects of frequency and semantic relatedness effects, but no such effects were found for the serial recognition test. Thus, the absence of a particular manipulation in serial recognition is not necessarily informative of the effect of that manipulation in serial recall.
The results of Experiment 3 combined with those already extant in the literature reinforce the notion that one should be wary of any results from a small stimulus pool even when great care is taken to select stimuli. If the set of stimuli is small, the danger persists that some idiosyncratic factor differs enough to influence performance and lead to erroneous conclusions and overly complicated theoretical speculations. This is not to say that all research using small stimulus pools is suspect. Rather, the point is that small pools are inherently more likely to be influenced by idiosyncratic properties than a large pool, and therefore, one must exercise caution when relying on the results of only one set of items. Greater confidence in an outcome can be built by conducting many experiments, each with a different set. Alternatively, a more efficient method is to create a large pool and then randomly select a small subset for each subject. By chance, a particular subject might receive a set of items with unusual properties, but it is highly unlikely that any other subject will receive a similar set. Put another way, randomly selecting the items from a larger pool minimises the chances of some unwanted variation being confounded with the experimental factor.
Conclusion
The general pattern of results is consistent with the redintegration framework, which in turn is consistent with results from the speech production literature. The redintegration framework can be incorporated into a number of different theoretical accounts, including simulation models. Because the experiments reported here were designed to evaluate only set size, the data do not inform on which of those accounts provides a more complete explanation. In summary, this study strengthens the empirical support for a facilitative effect of neighbourhood size on serial recall, but it also highlights the danger associated with stimuli propriety. Methods such as those used here provide more reliable findings and a safeguard against unwarranted challenges to theories and the addition of more complicated mechanisms to models.