
Abstract
Introduction
In today’s competitive manufacturing environment, and to respond quickly to shifting demand, organizations are moving toward a more effective demand-driven supply chain. The market has evolved into a “pull” environment with customers more demanding and discriminating, dictating to the supplier what products they desire and when they need them delivered. 1
Demand forecasting is crucial to inventory management. Inventory stock levels depend on demand’s forecasts. In fact, inaccurate estimation of demand can cause significant costs to pay, which proves that the process is not improved. Consequently, many systems incur large investments in inventories to avoid “stock outs.” A further complicating issue is that some demands can be intermittent demands, which means that there is a time when we have no demand and other time when we have successive demands. Intermittent demands present many difficulties for traditional statistical demand forecasting methods.
Generally, there are many approaches to forecast demand among which we find the exponential smoothing, for example. But, when applying these approaches, we need to have historical data. In the beginning, there is no information about the past, we use then an estimation based on similar cases or engineer’s experiences. In this case, we have a big amount of uncertainty which will be avoided with time.
For most organizations, managing demand is challenging because of the difficulty in forecasting future consumer needs accurately. 1 More than 74 % of the responds in a research survey, shows the poor forecasting accuracy and demand volatility as the increasing major challenges to supply chain flexibility. 2 Best performing companies tend to improve supply chain flexibility, agility, and responsiveness through improving forecasting accuracy throughout the long supply chain. 2 The managers in these companies must link forecasting to improvement goals and use past performance to avoid past errors and then reach a high level of efficiency. 3
Researchers came out with much work in the forecasting domain and suggested many methods among which we find two principal approaches much utilized: time series approaches and artificial neural network (ANN) techniques.
ANN models have been successfully involved in forecasting demand. These models are characterized by intervals with considerable variation of demand. ANN approach is considered as an alternative when it comes to the ability to capture the nonlinearity in data set.
ANN is applied in different fields. Gaafar and Choueiki 4 applied a neural network model to a lot-sizing problem as a part of material requirements planning for the case of deterministic time-varying demand. 5
To compare ANN and ARIMA method and to assess the performance of the two methods, a study related to electricity demand has been done by Prybutok et al. 6 to forecast a time series. ANN seems to be outperformed. Another study was done by Ho et al. 7 using simulated failure time of a compressor to determine the more accurate forecasting model. The two methods are used to forecast the failure of the system. 8
Aburto and Weber 9 combined the two forecasting methods which are ARIMA and neural networks. The efficiency of the hybrid model is compared with traditional forecasting methods. 10
This brief review of the literature shows that ANN is a strength tool aiming at the modeling of any time series. Nevertheless, in our article, we will test the ARIMA model at first to prove its ability to make accurate forecasts in the food company as a priori study.
In our article, we are interested the most in the time series approach: autoregressive integrated moving average (ARIMA) models, 11 –14 multivariate transfer function models, 11,15 dynamic models, 11 and generalized autoregressive conditional heteroskedasticity (GARCH) models 16 have also been proposed. Certainly, ARCH and GARCH models are increasingly utilized and are considered as important tools in the analysis of time series data, especially in the case of financial applications. But, they are specifically dedicated to the analysis and forecasting of volatility which is not our aim in this current article.
In all sectors, demand forecasts are of great importance. Indeed, predicting the demand facilitates the decision on the amount to produce and thus on the supply of the raw material and inventory management. In our case, we will work in a food company—which requires more than in other sectors—forecasts that are very reliable and accurate as long as it will affect the production of perishable goods. Besides, products in a food company having steady predictable demand need efficient supply chains that shorten lead times and support limited inventory.
A robust supply chain management system requires the presence of managers who are aware of the necessity of collaboration between different functions: planning, procurement, manufacturing, and logistics. Let’s take the example of the collaboration of planning function with suppliers. Over time, we feed our database to build a history that will be used to make our forecasts. After developing our model, which is the purpose of our article, we will easily have the planned application transmitted to the planning function. The latter carries out its production plan related to suppliers.
The aim is therefore to devise an optimal production plan based on accurate forecasts to minimize the total production cost composed by the procurement, processing, storage, and distribution costs. Expected benefits from these forecasts are reduced inventories, lower supply chain costs, increased return on assets, greater customer satisfaction, and reduced lead times. However, this optimal production plan should meet different company constraints among others: production capacity, minimum production lots, and so on.
We will be interested in the evolution by making forecasts of the demand in a Moroccan food company. To achieve its objectives, the company must rely on precise forecasts. In this context, our article aims mainly to study the demand to provide precise forecasts and to respect the permissible error margin. The main idea is that forecasting accuracy drives the performance of inventory management.
The aim of the present study is the modeling and forecasting of demand by using Box–Jenkins time series approach, especially the ARIMA. To achieve this goal, we used large and consistent historical demand data: from January 2010 until December 2015. Several ARIMA models were developed and evaluated by four performance criteria: Akaike criterion (AIC), Schwarz Bayesian criterion (SBC), maximum likelihood, and standard error. The adequate model was validated by new historical demand data under the same conditions. In this article, the second section presents a literature review about demand forecasting studies. The third section is consecrated to the results and discussions of our case study. Finally, the article concludes with a summary and the future work.
Literature review
Forecasting demand
In today’s organizations, which are subject to abrupt and enormous changes that affect even the most established of structures and where all requirements of business sector need accurate and practical reading into future, the forecasts are becoming very crucial since they are the sign of survival and the language of business in the world. A forecast is a science of estimating the future level of some variables. The variable is most often demand, but it can also be something else, such as supply or price. 17 Forecasting is the operation of making assumption about the future values of studied variables. 18
In manufacturing, forecasting demands is among the most crucial issues in inventory management 19 ; it can be used in various operational planning activities during the production process: capacity planning, used-product acquisition management. 20
For both types of supply chain processes “push/pull,” the demand forecasts are considered the ground of supply chain’s planning. The pull processes in the supply chain are realized with reference to customer demand, while all push processes are realized in anticipation of customer demand. 21 A company must take into consideration such factors before selecting a suitable forecasting methodology because the choice of a methodology is not as simple as it seems. Forecasting methods are categorized according to four types: qualitative, time series, causal, and simulation. 21
A time series is nothing but observations according to the chronological order of time. 17 Time series forecasting models use mathematical techniques that are based on historical data to forecast demand. It is founded on the hypothesis that the future is an expansion of the past; that’s why we can definitely use historical data to forecast future demand. 1
Many studies about demand forecasting by time series analysis have been done in several domains. They encircle demand forecasting for food product sales, 22 tourism, 23 maintenance repair parts, 19,24 electricity, 25,26 automobile, 27 and some other products and services. 28,29,30
By time series analysis, the forecasting accuracies depend on the characteristics of time series of demand. If the transition curves show stability and periodicity, we will reach high forecasting accuracies, whereas we can’t expect high accuracies if the curves contain highly irregular patterns. 27
Autoregressive integrated moving average
To model time series, we can work with the traditional statistical models including moving average, exponential smoothing, and ARIMA. These models are linear since the future values are cramped to be linear functions of past data.
During the past few decades, researchers have been focusing much on linear models since they had proved simplicity in comprehension and application.
Time series forecasting models are mostly used to predict demand. Under an autoregressive moving average hypothesis, Kurawarwala and Matsuo 31 calculated the seasonal variation of demand by using historical data and validated the models by examining the forecast performance. Miller and Williams 32 mixed seasonal factors in their model to improve forecasting accuracy, the seasonal factors are calculated from multiplicative model. Hyndman 33 widened Miller and Williams’ 32 work by applying different relationships between trend and seasonality under seasonal ARIMA hypothesis. The classical ARIMA approach becomes prohibitive, and in many cases, it is impossible to determine a model, when seasonal adjustment order is high or its diagnostics fail to indicate that time series is stationary after seasonal adjustment. In such cases, the static parameters of the classical ARIMA model are considered the principal constraint to forecasting high variable seasonal demand. Another constraint of the classical ARIMA approach is that it requires a large number of observations to determine the best fit model for a data series.
An ARIMA model is labeled as an ARIMA model (
The autoregressive process
Autoregressive models assume that

Literally, each observation consists of a random component (random shock,
The integrated process
The behavior of the time series may be affected by the cumulative effect of some processes. For example, stock status is constantly modified by consumption and supply, but the average level of stocks is essentially dependent on the cumulative effect of the instantaneous changes over the period between inventories. Although short-term stock values may fluctuate with large contingencies around this average value, the level of the series over the long term will remain unchanged. A time series determined by the cumulative effect of an activity belongs to the class of integrated processes. Even if the behavior of a series is erratic, the differences from one observation to the next can be relatively low or even oscillate around a constant value for a process observed at different time intervals. This stationarity of the series of differences for an integrated process is a crucial characteristic viewed from the statistical analysis side of the time series. Integrated processes are the archetype of nonstationary series. A differentiation of order 1 assumes that the difference between two successive values of

where the random perturbation
The moving average process
The current value of a moving averaging process is a linear combination of the current disturbance with one or more previous perturbations. The moving average order indicates the number of previous periods embedded in the current value. Thus, a moving average is defined by equation (3)

Box and Jenkins 34 was founded on the contributions of Yule 35 and Wold 36 to develop a practical approach in order to perform ARIMA models. The Box–Jenkins principle consists of three iterative steps of model identification, parameter estimation, and diagnostic checking steps 37 . The principle rule to identify the model is that if a time series is obtained from an ARIMA process, it should have some theoretical autocorrelation properties. By matching the theoretical and empirical autocorrelation patterns, we make it possible to identify one or several potential models for the given time series. Box and Jenkins 34 proposed to use the autocorrelation function (ACF) and the partial autocorrelation function (PACF) of the sample data as the basic tools to identify the order of the ARIMA model.
As far as the identification step is concerned, we should produce a stationary time series, which is a required condition to find the ARIMA model, so, we mostly need data transformation. The statistical characteristics of a stationary time series such as the mean and the autocorrelation structure are constant over time. We usually need to apply differencing and power transformation to the data to remove the trend and stabilize the variance before an ARIMA model can be fitted.
After that, it becomes easy to calculate the model parameters and then specify the model. These parameters are estimated so that the overall error is reduced.
Finally, we move to the diagnostic checking of model adequacy. In this last step, we make sure that the hypothesis we made about the errors are contended. The diagnostic statistics and plots of residuals can be used to assess the adequacy of future values to our data. If the model is not adequate, we have to make other estimation of parameters followed by the model validation. Diagnostic information can help us come up with new models.
Box–Jenkins model constitutes a process approach to follow and repeat till reaching a high degree of satisfaction about the model and having reduced errors. Consequently, we can freely use this model to forecast our variable.
Researchers approve that the estimation of parameters requires a large number of observations. Consequently, there are some limits for using ARIMA model. Nevertheless, once we apply ARIMA model, we reach a high quality in the opposite of the time series models.
Results and discussion
In this article, the demand forecasting of the final product in a food manufacturing is conducted based on real data, and the accuracy and characteristics are studied. This study examines the effectiveness of demand forecasting in a food manufacturing.
Based on the Box–Jenkins approach, our study will be carried out in three parts: identification, estimation, and verification. The model shown in Figure 1 is based on the demand of the final product in a Moroccan food manufacturing from January 2010 until December 2015.
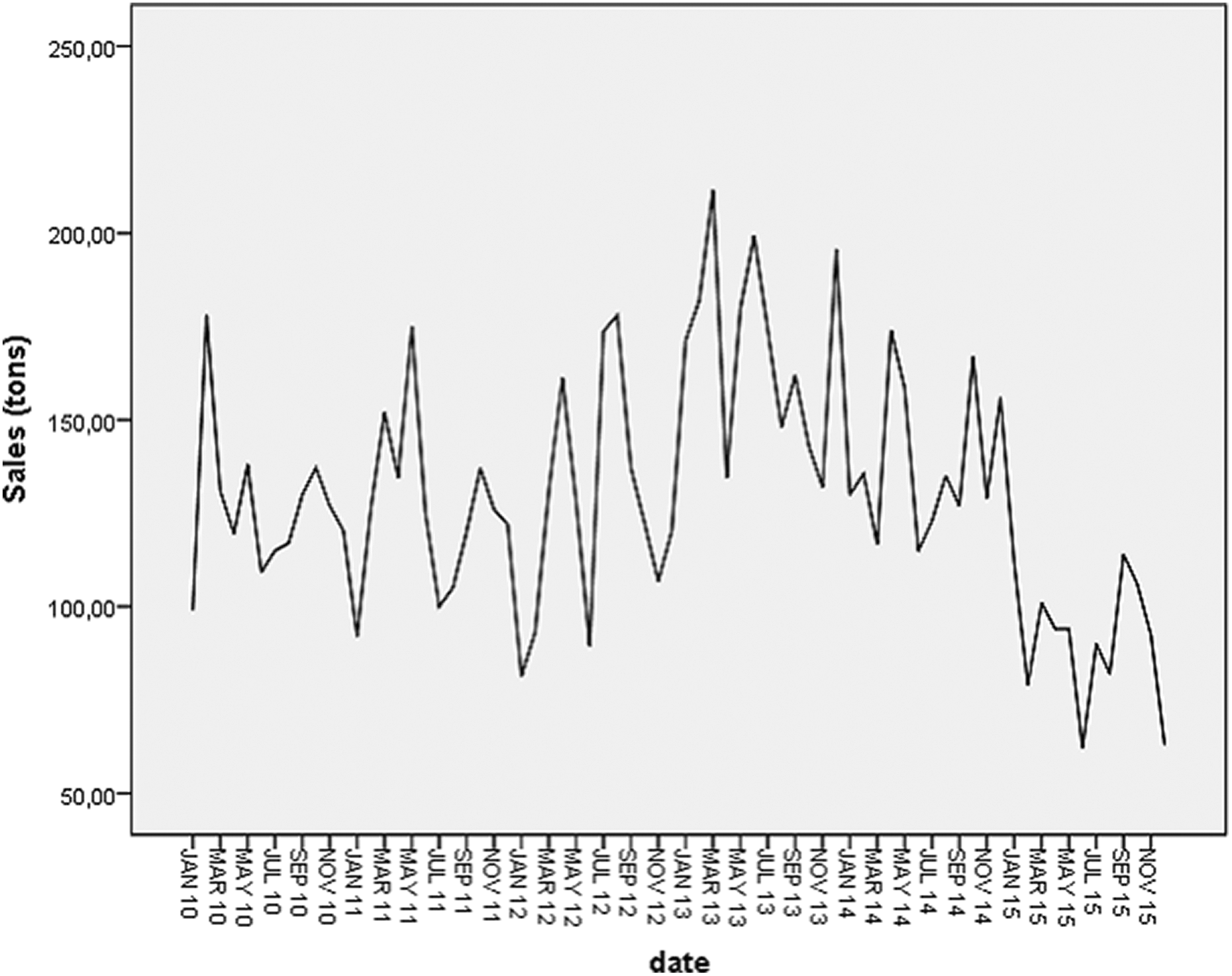
Evolution of the final product’s sales.
Identification of model
In this step, we start with the initial preprocessing of the data to make it stationary, and then we choose possible values of
For stationarity, the series shown in Figures 2 and 3, respectively, fluctuates around an average value and its ACF decays to zero fairly rapidly which proves the stationarity of the time series.

ACF correlograms of the demand series. ACF: autocorrelation function.

PACF correlograms of the demand series. PACF: partial autocorrelation function.
Moreover, to assess whether the data come from a stationary process we can perform the unit root test: Dickey–Fuller test for stationarity. After carrying out the test on the Xlstat software, the results are grouped in Table 1.
Test results.

Since the calculated
In our case, and after verification of the stationarity of the series, we notice from the ACF and PACF correlograms that our model is not pure AR or pure MA. We therefore tested several models to identify the most suitable one for sales.
Estimation of model’s coefficients
The ARIMA procedure of the SPSS time series module
38
allows estimating the coefficients of the models that we have previously identified by providing the parameters
The execution of the procedure adds new time series representing the values adjusted or predicted by the model, residuals (adjustment errors) and confidence intervals of the adjustment at a 95% confidence level. The best model is as simple as possible and minimizes certain criteria, namely AIC, SBC, variance and maximum likelihood.
43
–45
The chosen model is that of ARIMA (0, 1, 1). For the other models, either Student “
Table 2 summarizes the values of the different models and proves the choice of the model on which we will base our predictions. It is clear from Table 2 that the ARIMA model (1, 0, 1) is selected because all the coefficients are significantly different from 0 according to the Student test (|
Coefficients of different models.

SBC: Schwarz Bayesian criterion; AIC: Akaike criterion; ARIMA: autoregressive integrated moving average; SEB: Standard Error of B (B: Regression Coefficient).
The model residue is stationary and follows a white noise process in the range of ±40. The residue histogram shows whether the distribution of residues approximates a normal distribution. In our case, we have residues that distribute relatively normal around zero and with a relatively low dispersion at a 5% risk.
The chosen model parameters are presented in Table 3.
ARIMA model parameters.

ARIMA: autoregressive integrated moving average.
The developed model is given by equation (4)

with:
From Table 3, we can extract the coefficients of autoregressive and moving average processes. Therefore, equation (4) becomes as follows

Accuracy of ARIMA (1, 0, 1) model
The accuracy of the developed model was evaluated by comparing the experimental and the simulated sales in the same period. Figure 4 reports this comparison and reveals that the selected model has a high accuracy and ability to simulate the dynamic behavior of sales. Therefore, this model can be used to analyze and model the demand in this food manufacturing.

Sales, fit, LCL, and UCL. LCL: lower control limit; UCL: upper control limit.
From the graph, we notice that the model is validated since the predicted demand fluctuates around the fit. We also note that the predicted demand stayed between the upper limit and the lower limit.
We can see that the error variates but it is among the tolerance interval. In order to minimize this error, we propose a new approach in our future work.
Forecast
After we have defined the most appropriate model of demand in our case, we have to make the forecasting; to do this and so to predict trends and develop forecast, we used the IBM SPSS Forecasting. Table 4 and Figure 5 present the results of the sales forecasts that we obtained by applying our model ARIMA (1, 0, 1) for the next 10 months from January 2016 to October 2016.
Forecast sales from January 2016 to October 2016.

LCL: lower control limit; UCL: upper control limit.

Sales, fit, LCL, UCL, and forecasting. LCL: lower control limit; UCL: upper control limit.
We can clearly see that the model chosen can be used for modeling and forecasting the future demand in this food manufacturing, but each time we need to feed the historical data with the new data to enrich it in order to improve the new model and forecasting.
The forecasts obtained after modeling facilitated the decision on the production in this food company. In fact, the model enabled us to forecast the demand and make accurate predictions. Once we obtain a demand forecast, it will be much easier end very clear to make the right production planning and thus eliminate big cost losses. That will help us take right decisions related to supplying raw materials and determination of daily production. Moreover, that will affect the whole production process eliminating then any kind of loss.
Conclusion
Demand forecasting is an important function of managing supply chain. Its integration with other business functions makes it one of the most important planning processes business can deploy for future. In this context, we developed an ARIMA model to model the demand forecasting of the finished product in a food manufacturing by using Box–Jenkins time series approach. The historical demand data were used to develop several models and the adequate one was selected according to four performance criteria: SBC, AIC, standard error, and maximum likelihood. The model that we selected and which minimizes the four previous criteria is ARIMA (1, 0, 1). The results obtained proves that this model can be used for modeling and forecasting the future demand in this food manufacturing; these results will provide to managers of this manufacturing reliable guidelines in making decisions. As future work, we will develop other models by using a combination of qualitative and quantitative techniques to generate reliable forecasts and increase the forecast accuracy. We will also try neural network approach to compare it with ARIMA’s results in order to confirm the ANN’s strength in the food company. Furthermore, we will make an ARIMA-radial basis function (RBF) combination always to achieve the same goal: high accuracy.