
Abstract
Introduction
In information societies, operations, decisions and choices previously left to humans are increasingly delegated to algorithms, which may advise, if not decide, about how data should be interpreted and what actions should be taken as a result. 1 Examples abound. Profiling and classification algorithms determine how individuals and groups are shaped and managed (Floridi, 2012). Recommendation systems give users directions about when and how to exercise, what to buy, which route to take, and who to contact (Vries, 2010: 81). Data mining algorithms are said to show promise in helping make sense of emerging streams of behavioural data generated by the ‘Internet of Things’ (Portmess and Tower, 2014: 1). Online service providers continue to mediate how information is accessed with personalisation and filtering algorithms (Newell and Marabelli, 2015; Taddeo and Floridi, 2015). Machine learning algorithms automatically identify misleading, biased or inaccurate knowledge at the point of creation (e.g. Wikipedia's Objective Revision Evaluation Service). As these examples suggest, how we perceive and understand our environments and interact with them and each other is increasingly mediated by algorithms.
Algorithms are inescapably value-laden (Brey and Soraker, 2009; Wiener, 1988). Operational parameters are specified by developers and configured by users with desired outcomes in mind that privilege some values and interests over others (cf. Friedman and Nissenbaum, 1996; Johnson, 2006; Kraemer et al., 2011; Nakamura, 2013). At the same time, operation within accepted parameters does not guarantee ethically acceptable behaviour. This is shown, for example, by profiling algorithms that inadvertently discriminate against marginalised populations (Barocas and Selbst, 2015; Birrer, 2005), as seen in delivery of online advertisements according to perceived ethnicity (Sweeney, 2013).
Determining the potential and actual ethical impact of an algorithm is difficult for many reasons. Identifying the influence of human subjectivity in algorithm design and configuration often requires investigation of long-term, multi-user development processes. Even with sufficient resources, problems and underlying values will often not be apparent until a problematic use case arises. Learning algorithms, often quoted as the ‘future’ of algorithms and analytics (Tutt, 2016), introduce uncertainty over how and why decisions are made due to their capacity to tweak operational parameters and decision-making rules ‘in the wild’ (Burrell, 2016). Determining whether a particular problematic decision is merely a one-off ‘bug’ or evidence of a systemic failure or bias may be impossible (or at least highly difficult) with poorly interpretable and predictable learning algorithms. Such challenges are set to grow, as algorithms increase in complexity and interact with each other's outputs to take decisions (Tutt, 2016). The resulting gap between the design and operation of algorithms and our understanding of their ethical implications can have severe consequences affecting individuals, groups and whole segments of a society.
In this paper, we map the ethical problems prompted by algorithmic decision-making. The paper answers two questions: what kinds of ethical issues are raised by algorithms? And, how do these issues apply to algorithms themselves, as opposed to technologies built upon algorithms? We first propose a conceptual map based on six kinds of concerns that are jointly sufficient for a principled organisation of the field. We argue that the map allows for a more rigorous diagnosis of ethical challenges related to the use of algorithms. We then review the scientific literature discussing ethical aspects of algorithms to assess the utility and accuracy of the proposed map. Seven themes emerged from the literature that demonstrate how the concerns defined in the proposed map arise in practice. Together, the map and review provide a common structure for future discussion of the ethics of algorithms. In the final section of the paper we assess the fit between the proposed map and themes currently raised in the reviewed literature to identify areas of the ‘ethics of algorithms’ requiring further research. The conceptual framework, review and critical analysis offered in this paper aim to inform future ethical inquiry, development, and governance of algorithms.
Background
To map the ethics of algorithms, we must first define some key terms. ‘Algorithm’ has an array of meanings across computer science, mathematics and public discourse. As Hill explains, “we see evidence that any procedure or decision process, however ill-defined, can be called an ‘algorithm’ in the press and in public discourse. We hear, in the news, of ‘algorithms’ that suggest potential mates for single people and algorithms that detect trends of financial benefit to marketers, with the implication that these algorithms may be right or wrong…” (Hill, 2015: 36). Many scholarly critiques also fail to specify technical categories or a formal definition of ‘algorithm’ (Burrell, 2016; Kitchin, 2016). In both cases the term is used not in reference to the algorithm as a mathematical construct, but rather the implementation and interaction of one or more algorithms in a particular program, software or information system. Any attempt to map an ‘ethics of algorithms’ must address this conflation between formal definitions and popular usage of ‘algorithm’.
Here, we follow Hill's (2015: 47) formal definition of an algorithm as a
Accordingly, it makes little sense to consider the ethics of algorithms independent of how they are implemented and executed in computer programs, software and information systems. Our aim here is to map the ethics of algorithms, with ‘algorithm’ interpreted along public discourse lines. Our map will include ethical issues arising from algorithms as mathematical constructs, implementations (technologies, programs) and configurations (applications). 3 Where discussion focuses on implementations or configurations (i.e. an artefact with an embedded algorithm), we limit our focus to issues relating to the algorithm's work, rather than all issues related to the artefact.
However, as noted by Hill above, a problem with the popular usage of ‘algorithm’ is that it can describe “any procedure or decision process,” resulting in a prohibitively large range of artefacts to account for in a mapping exercise. Public discourse is currently dominated by concerns with a particular class of algorithms that make decisions, e.g. the best action to take in a given situation, the best interpretation of data, and so on. Such algorithms augment or replace analysis and decision-making by humans, often due to the scope or scale of data and rules involved. Without offering a precise definition of the class, the algorithms we are interested in here are those that make generally reliable (but subjective and not necessarily correct) decisions based upon complex rules that challenge or confound human capacities for action and comprehension. 4 In other words, we are interested in algorithms whose actions are difficult for humans to predict or whose decision-making logic is difficult to explain after the fact. Algorithms that automate mundane tasks, for instance in manufacturing, are not our concern.
Decision-making algorithms are used across a variety of domains, from simplistic decision-making models (Levenson and Pettrey, 1994) to complex profiling algorithms (Hildebrandt, 2008). Notable contemporary examples include online software agents used by online service providers to carry out operations on the behalf of users (Kim et al., 2014); online dispute resolution algorithms that replace human decision-makers in dispute mediation (Raymond, 2014; Shackelford and Raymond, 2014); recommendation and filtering systems that compare and group users to provide personalised content (Barnet, 2009); clinical decision support systems (CDSS) that recommend diagnoses and treatments to physicians (Diamond et al., 1987; Mazoué, 1990); and predictive policing systems that predict criminal activity hotspots.
The discipline of data analytics is a standout example, defined here as the practice of using algorithms to make sense of streams of data. Analytics informs immediate responses to the needs and preferences of the users of a system, as well as longer term strategic planning and development by a platform or service provider (Grindrod, 2014). Analytics identifies relationships and small patterns across vast and distributed datasets (Floridi, 2012). New types of enquiry are enabled, including behavioural research on ‘scraped’ data (e.g. Lomborg and Bechmann, 2014: 256); tracking of fine-grained behaviours and preferences (e.g. sexual orientation or political opinions; (Mahajan et al., 2012); and prediction of future behaviour (as used in predictive policing or credit, insurance and employment screening; Zarsky, 2016).
Analytics demonstrates how algorithms can challenge human decision-making and comprehension even for tasks previously performed by humans. In making a decision (for instance, which risk class a purchaser of insurance belongs to), analytics algorithms work with high-dimension data to determine which features are relevant to a given decision. The number of features considered in any such classification task can run into the tens of thousands. This type of task is thus a replication of work previously undertaken by human workers (i.e. risk stratification), but involving a qualitatively different decision-making logic applied to greater inputs.
Algorithms are, however, ethically challenging not only because of the scale of analysis and complexity of decision-making. The uncertainty and opacity of the work being done by algorithms and its impact is also increasingly problematic. Algorithms have traditionally required decision-making rules and weights to be individually defined and programmed ‘by hand’. While still true in many cases (Google's PageRank algorithm is a standout example), algorithms increasingly rely on learning capacities (Tutt, 2016).
Machine learning is “any methodology and set of techniques that can employ data to come up with novel patterns and knowledge, and generate models that can be used for effective predictions about the data” (Van Otterlo, 2013). Machine learning is defined by the capacity to define or modify decision-making rules autonomously. A machine learning algorithm applied to classification tasks, for example, typically consists of two components, a
As this explanation suggests, learning capacities grant algorithms some degree of autonomy. The impact of this autonomy must remain uncertain to some degree. As a result, tasks performed by machine learning are difficult to predict beforehand (how a new input will be handled) or explain afterwards (how a particular decision was made). Uncertainty can thus inhibit the identification and redress of ethical challenges in the design and operation of algorithms.
Map of the ethics of algorithms
Using the key terms defined in the previous section, we propose a conceptual map (Figure 1) based on six types of concerns that are jointly sufficient for a principled organisation of the field, and conjecture that it allows for a more rigorous diagnosis of ethical challenges related to the use of algorithms. The map is not proposed from a particular theoretical or methodological approach to ethics, but rather is intended as a prescriptive framework of types of issues arising from algorithms owing to three aspects of how algorithms operate. The map takes into account that the algorithms this paper is concerned with are used to (1) turn data into evidence for Six types of ethical concerns raised by algorithms.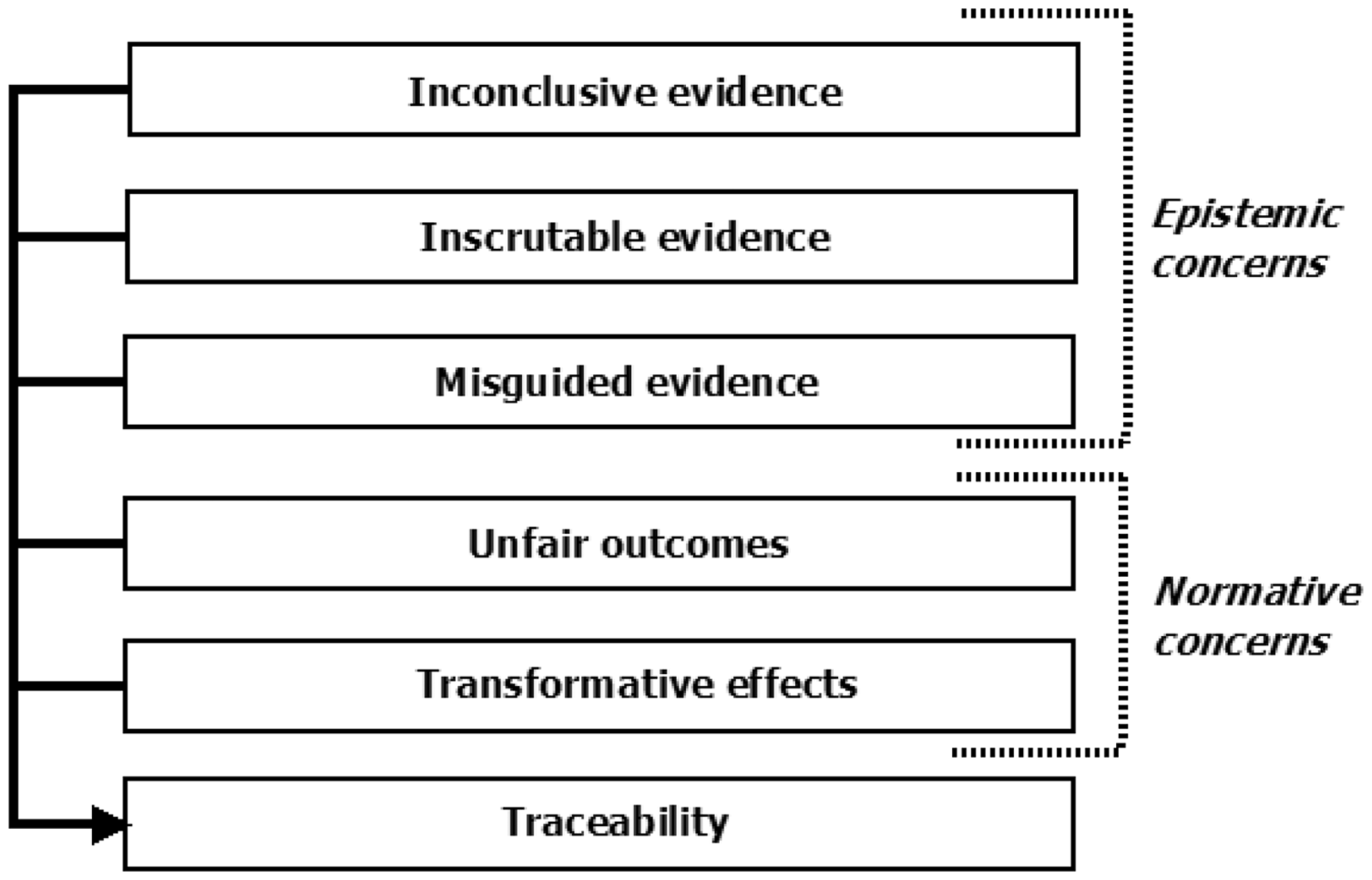
Inconclusive evidence
When algorithms draw conclusions from the data they process using inferential statistics and/or machine learning techniques, they produce probable
6
yet inevitably uncertain knowledge. Statistical learning theory (James et al., 2013) and computational learning theory (Valiant, 1984) are both concerned with the characterisation and quantification of this uncertainty. In addition to this, and as often indicated, statistical methods can help identify significant correlations, but these are rarely considered to be sufficient to posit the existence of a causal connection (Illari and Russo, 2014: Chapter 8), and thus may be insufficient to motivate action on the basis of knowledge of such a connection. The term
Algorithms are typically deployed in contexts where more reliable techniques are either not available or too costly to implement, and are thus rarely meant to be infallible. Recognising this limitation is important, but should be complemented with an assessment of how the risk of being wrong affects one's epistemic responsibilities (Miller and Record, 2013): for instance, by weakening the justification one has for a conclusion beyond what would be deemed acceptable to justify action in the context at hand.
Inscrutable evidence
When data are used as (or processed to produce) evidence for a conclusion, it is reasonable to expect that the connection between the data and the conclusion should be accessible (i.e. intelligible as well as open to scrutiny and perhaps even critique). 7 When the connection is not obvious, this expectation can be satisfied by better access as well as by additional explanations. Given how algorithms operate, these requirements are not automatically satisfied. A lack of knowledge regarding the data being used (e.g. relating to their scope, provenance and quality), but more importantly also the inherent difficulty in the interpretation of how each of the many data-points used by a machine-learning algorithm contribute to the conclusion it generates, cause practical as well as principled limitations (Miller and Record, 2013).
Misguided evidence
Algorithms process data and are therefore subject to a limitation shared by all types of data-processing, namely that the output can never exceed the input. While Shannon's mathematical theory of communication (Shannon and Weaver, 1998), and especially some of his information-inequalities, give a formally precise account of this fact, the informal ‘garbage in, garbage out’ principle clearly illustrates what is at stake here, namely that conclusions can only be as reliable (but also as neutral) as the data they are based on. Evaluations of the neutrality of the process, and by connection whether the evidence produced is misguided, are of course observer-dependent.
Unfair outcomes
The three epistemic concerns detailed thus far address the quality of
Transformative effects
The ethical challenges posed by the spreading use of algorithms cannot always be retraced to clear cases of epistemic or ethical failures, for some of the effects of the reliance on algorithmic data-processing and (semi-)autonomous decision-making can be questionable and yet appear ethically neutral because they do not seem to cause any obvious harm. This is because algorithms can affect how we conceptualise the world, and modify its social and political organisation (cf. Floridi, 2014). Algorithmic activities, like profiling, reontologise the world by understanding and conceptualising it in new, unexpected ways, and triggering and motivating actions based on the insights it generates.
Traceability
Algorithms are software-artefacts used in data-processing, and as such inherit the ethical challenges associated with the design and availability of new technologies and those associated with the manipulation of large volumes of personal and other data. This implies that harm caused by algorithmic activity is hard to debug (i.e. to detect the harm and find its cause), but also that it is rarely straightforward to identify who should be held responsible for the harm caused. 8 When a problem is identified addressing any or all of the five preceding kinds, ethical assessment requires both the cause and responsibility for the harm to be traced.
Thanks to this map (Figure 1), we are now able to distinguish epistemological, strictly ethical and traceability types in descriptions of ethical problems with algorithms. The map is thus intended as a tool to organise a widely dispersed academic discourse addressing a diversity of technologies united by their reliance on algorithms. To assess the utility of the map, and to observe how each of these kinds of concerns manifests in ethical problems already observed in algorithms, a systematic review of academic literature was carried out. 9 The following sections (4 to 10) describe how ethical issues and concepts are treated in the literature explicitly discussing the ethical aspects of algorithms.
Inconclusive evidence leading to unjustified actions
Much algorithmic decision-making and data mining relies on inductive knowledge and correlations identified within a dataset. Causality is not established prior to acting upon the evidence produced by the algorithm. The search for causal links is difficult, as correlations established in large, proprietary datasets are frequently not reproducible or falsifiable (cf. Ioannidis, 2005; Lazer et al., 2014). Despite this, correlations based on a sufficient volume of data are increasingly seen as sufficiently credible to direct action without first establishing causality (Hildebrandt, 2011; Hildebrandt and Koops, 2010; Mayer-Schönberger and Cukier, 2013; Zarsky, 2016). In this sense data mining and profiling algorithms often need only establish a sufficiently reliable evidence base to drive action, referred to here as actionable insights.
Acting on correlations can be doubly problematic. 10 Spurious correlations may be discovered rather than genuine causal knowledge. In predictive analytics correlations are doubly uncertain (Ananny, 2016). Even if strong correlations or causal knowledge are found, this knowledge may only concern populations while actions are directed towards individuals (Illari and Russo, 2014). As Ananny (2016: 103) explains, “algorithmic categories … signal certainty, discourage alternative explorations, and create coherence among disparate objects,” all of which contribute to individuals being described (possibly inaccurately) via simplified models or classes (Barocas, 2014). Finally, even if both actions and knowledge are at the population-level, our actions may spill over into the individual level. For example, this happens when an insurance premium is set for a sub-population, and hence has to be paid by each member. Actions taken on the basis of inductive correlations have real impact on human interests independent of their validity.
Inscrutable evidence leading to opacity
The scrutability of evidence, evaluated in terms of the transparency or opacity of algorithms, proved a major concern in the reviewed literature. Transparency is generally desired because algorithms that are poorly predictable or explainable are difficult to control, monitor and correct (Tutt, 2016). As many critics have observed (Crawford, 2016; Neyland, 2016; Raymond, 2014), transparency is often naïvely treated as a panacea for ethical issues arising from new technologies. Transparency is generally defined with respect to “the availability of information, the conditions of accessibility and how the information … may pragmatically or epistemically support the user's decision-making process” (Turilli and Floridi, 2009: 106). The debate on this topic is not new. The literature in information and computer ethics, for example started to focus on it at the beginning of the 21st century, when issues concerning algorithmic information filtering by search engines arose. 11
The primary components of transparency are
Granka (2010) notes a power struggle between data subjects’ interests in transparency and data processors’ commercial viability. Disclosing the structure of these algorithms would facilitate ill-intentioned manipulations of search results (or ‘gaming the system’), while not bringing any advantage to the average non-tech-savvy user (Granka, 2010; Zarsky, 2016). The commercial viability of data processors in many industries (e.g. credit reporting, high frequency trading) may be threatened by transparency. However, data subjects retain an interest in understanding how information about them is created and influences decisions taken in data-driven practices. This struggle is marked by information asymmetry and an “imbalance in knowledge and decision-making power” favouring data processors (Tene and Polonetsky, 2013a: 252).
Besides being accessible, information must be comprehensible to be considered transparent (Turilli and Floridi, 2009). Efforts to make algorithms transparent face a significant challenge to render complex decision-making processes both accessible and comprehensible. The longstanding problem of interpretability in machine learning algorithms indicates the challenge of opacity in algorithms (Burrell, 2016; Hildebrandt, 2011; Leese, 2014; Tutt, 2016). Machine learning is adept at creating and modifying rules to classify or cluster large datasets. The algorithm modifies its behavioural structure during operation (Markowetz et al., 2014). This alteration of how the algorithm classifies new inputs is how it learns (Burrell, 2016: 5). Training produces a structure (e.g. classes, clusters, ranks, weights, etc.) to classify new inputs or predict unknown variables. Once trained, new data can be processed and categorised automatically without operator intervention (Leese, 2014). The rationale of the algorithm is obscured, lending to the portrayal of machine learning algorithms as ‘black boxes’.
Burrell (2016) and Schermer (2011) argue that the opacity of machine learning algorithms inhibits oversight. Algorithms “are opaque in the sense that if one is a recipient of the output of the algorithm (the classification decision), rarely does one have any concrete sense of how or why a particular classification has been arrived at from inputs” (Burrell, 2016: 1). Both the inputs (data about humans) and outputs (classifications) can be unknown and unknowable. Opacity in machine learning algorithms is a product of the high-dimensionality of data, complex code and changeable decision-making logic (Burrell, 2016). Matthias (2004: 179) suggests that machine learning can produce outputs for which “the human trainer himself is unable to provide an algorithmic representation.” Algorithms can only be considered explainable to the degree that a human can articulate the trained model or rationale of a particular decision, for instance by explaining the (quantified) influence of particular inputs or attributes (Datta et al., 2016). Meaningful oversight and human intervention in algorithmic decision-making “is impossible when the machine has an informational advantage over the operator … [or] when the machine cannot be controlled by a human in real-time due to its processing speed and the multitude of operational variables” (Matthias, 2004: 182–183). This is, one again, the black box problem. However, a distinction should be drawn, between the technical infeasibility of oversight and practical barriers caused, for instance, by a lack of expertise, access, or resources.
Beyond machine learning, algorithms with ‘hand-written’ decision-making rules can still be highly complex and practically inscrutable from a lay data subject's perspective (Kitchin, 2016). Algorithmic decision-making structures containing “hundreds of rules are very hard to inspect visually, especially when their predictions are combined probabilistically in complex ways” (Van Otterlo, 2013). Further, algorithms are often developed by large teams of engineers over time, with a holistic understanding of the development process and its embedded values, biases and interdependencies rendered infeasible (Sandvig et al., 2014). In both respects, algorithmic processing contrasts with traditional decision-making, where human decision-makers can in principle articulate their rationale when queried, limited only by their desire and capacity to give an explanation, and the questioner's capacity to understand it. The rationale of an algorithm can in contrast be incomprehensible to humans, rendering the legitimacy of decisions difficult to challenge.
Under these conditions, decision-making is poorly transparent. Rubel and Jones (2014) argue that the failure to render the processing logic comprehensible to data subject's disrespects their agency (we shall return to this point in Section 8). Meaningful consent to data-processing is not possible when opacity precludes risk assessment (Schermer, 2011). Releasing information about the algorithm's decision-making logic in a simplified format can help (Datta et al., 2016; Tene and Polonetsky, 2013a). However, complex decision-making structures can quickly exceed the human and organisational resources available for oversight (Kitchin, 2016). As a result, lay data subjects may lose trust in both algorithms and data processors (Cohen et al., 2014; Rubel and Jones, 2014; Shackelford and Raymond, 2014). 12
Even if data processors and controllers disclose operational information, the net benefit for society is uncertain. A lack of public engagement with existing transparency mechanisms reflects this uncertainty, seen for example in credit scoring (Zarsky, 2016). Transparency disclosures may prove more impactful if tailored towards trained third parties or regulators representing public interest as opposed to data subjects themselves (Tutt, 2016; Zarsky, 2013).
Transparency disclosures by data processors and controllers may prove crucial in the future to maintain a trusting relationship with data subjects (Cohen et al., 2014; Rubel and Jones, 2014; Shackelford and Raymond, 2014). Trust implies the trustor's (the agent who trusts) expectations for the trustee (the agent who is trusted) to perform a task (Taddeo, 2010), and acceptance of the risk that the trustee will betray these expectations (Wiegel and Berg, 2009). Trust in data processors can, for instance, alleviate concerns with opaque personal data-processing (Mazoué, 1990). However, trust can also exist among artificial agents exclusively, seen for instance in the agents of a distributed system working cooperatively to achieve a given goal (Grodzinsky et al., 2010; Simon, 2010; Taddeo, 2010). Furthermore, algorithms can be perceived as trustworthy independently of (or perhaps even despite) any trust placed in the data processor; yet the question of when this may be appropriate remains open. 13
Misguided evidence leading to bias
The automation of human decision-making is often justified by an alleged lack of bias in algorithms (Bozdag, 2013; Naik and Bhide, 2014). This belief is unsustainable, as shown by prior work demonstrating the normativity of information technologies in general and algorithm development in particular 14 (e.g. Bozdag, 2013; Friedman and Nissenbaum, 1996; Kraemer et al., 2011; Macnish, 2012; Newell and Marabelli, 2015: 6; Tene and Polonetsky, 2013b). Much of the reviewed literature addresses how bias manifests in algorithms and the evidence they produce.
Algorithms inevitably make biased decisions. An algorithm's design and functionality reflects the values of its designer and intended uses, if only to the extent that a particular design is preferred as the best or most efficient option. Development is not a neutral, linear path; there is no objectively correct choice at any given stage of development, but many possible choices (Johnson, 2006). As a result, “the values of the author [of an algorithm], wittingly or not, are frozen into the code, effectively institutionalising those values” (Macnish, 2012: 158). It is difficult to detect latent bias in algorithms and the models they produce when encountered in isolation of the algorithm's development history (Friedman and Nissenbaum, 1996; Hildebrandt, 2011; Morek, 2006).
Friedman and Nissenbaum (1996) argue that bias can arise from (1) pre-existing social values found in the “social institutions, practices and attitudes” from which the technology emerges, (2) technical constraints and (3) emergent aspects of a context of use. Social biases can be embedded in system design purposefully by individual designers, seen for instance in manual adjustments to search engine indexes and ranking criteria (Goldman, 2006). Social bias can also be unintentional, a subtle reflection of broader cultural or organisational values. For example, machine learning algorithms trained from human-tagged data inadvertently learn to reflect biases of the taggers (Diakopoulos, 2015).
Technical bias arises from technological constraints, errors or design decisions, which favour particular groups without an underlying driving value (Friedman and Nissenbaum, 1996). Examples include when an alphabetical listing of airline companies leads to increase business for those earlier in the alphabet, or an error in the design of a random number generator that causes particular numbers to be favoured. Errors can similarly manifest in the datasets processed by algorithms. Flaws in the data are inadvertently adopted by the algorithm and hidden in outputs and models produced (Barocas and Selbst, 2015; Romei and Ruggieri, 2014).
Emergent bias is linked with advances in knowledge or changes to the system's (intended) users and stakeholders (Friedman and Nissenbaum, 1996). For example, CDSS are unavoidably biased towards treatments included in their decision architecture. Although emergent bias is linked to the user, it can emerge unexpectedly from decisional rules developed by the algorithm, rather than any ‘hand-written’ decision-making structure (Hajian and Domingo-Ferrer, 2013; Kamiran and Calders, 2010). Human monitoring may prevent some biases from entering algorithmic decision-making in these cases (Raymond, 2014).
The outputs of algorithms also require interpretation (i.e. what one should do based on what the algorithm indicates); for behavioural data, ‘objective’ correlations can come to reflect the interpreter's “unconscious motivations, particular emotions, deliberate choices, socio-economic determinations, geographic or demographic influences” (Hildebrandt, 2011: 376). Explaining the correlation in any of these terms requires additional justification – meaning is not self-evident in statistical models. Different metrics “make visible aspects of individuals and groups that are not otherwise perceptible” (Lupton, 2014: 859). It thus cannot be assumed that an observer's interpretation will correctly reflect the perception of the actor rather than the biases of the interpreter.
Unfair outcomes leading to discrimination
Much of the reviewed literature also addresses how discrimination results from biased evidence and decision-making. 15 Profiling by algorithms, broadly defined “as the construction or inference of patterns by means of data mining and … the application of the ensuing profiles to people whose data match with them” (Hildebrandt and Koops, 2010: 431), is frequently cited as a source of discrimination. Profiling algorithms identify correlations and make predictions about behaviour at a group-level, albeit with groups (or profiles) that are constantly changing and re-defined by the algorithm (Zarsky, 2013). Whether dynamic or static, the individual is comprehended based on connections with others identified by the algorithm, rather than actual behaviour (Newell and Marabelli, 2015: 5). Individuals' choices are structured according to information about the group (Danna and Gandy, 2002: 382). Profiling can inadvertently create an evidence-base that leads to discrimination (Vries, 2010).
For the affected parties, data-driven discriminatory treatment is unlikely to be more palatable than discrimination fuelled by prejudices or anecdotal evidence. This much is implicit in Schermer's (2011) argument that discriminatory treatment is not ethically problematic in itself; rather, it is the effects of the treatment that determine its ethical acceptability. However, Schermer muddles bias and discrimination into a single concept. What he terms discrimination can be described instead as mere bias, or the consistent and repeated expression of a particular preference, belief or value in decision-making (Friedman and Nissenbaum, 1996). In contrast, what he describes as problematic effects of discriminatory treatment can be defined as discrimination
It may be possible to direct algorithms not to consider sensitive attributes that contribute to discrimination (Barocas and Selbst, 2015), such as gender or ethnicity (Calders et al., 2009; Kamiran and Calders, 2010; Schermer, 2011), based upon the emergence of discrimination in a particular context. However, proxies for protected attributes are not easy to predict or detect (Romei and Ruggieri, 2014; Zarsky, 2016), particularly when algorithms access linked datasets (Barocas and Selbst, 2015). Profiles constructed from neutral characteristics such as postal code may inadvertently overlap with other profiles related to ethnicity, gender, sexual preference, and so on (Macnish, 2012; Schermer, 2011).
Efforts are underway to avoid such ‘redlining’ by sensitive attributes and proxies. Romei and Ruggieri (2014) observe four overlapping strategies for discrimination prevention in analytics: (1) controlled distortion of training data; (2) integration of anti-discrimination criteria into the classifier algorithm; (3) post-processing of classification models; (4) modification of predictions and decisions to maintain a fair proportion of effects between protected and unprotected groups. These strategies are seen in the development of privacy-preserving, fairness- and discrimination-aware data mining (Dwork et al., 2011; Kamishima et al., 2012). Fairness-aware data mining takes the broadest aim, as it gives attention not only to discrimination but fairness, neutrality, and independence as well (Kamishima et al., 2012). Various metrics of fairness are possible based on statistical parity, differential privacy and other relations between data subjects in classification tasks (Dwork et al., 2011; Romei and Ruggieri, 2014).
The related practice of personalisation is also frequently discussed. Personalisation can segment a population so that only some segments are worthy of receiving some opportunities or information, re-enforcing existing social (dis)advantages. Questions of the fairness and equitability of such practices are often raised (e.g. Cohen et al., 2014; Danna and Gandy, 2002; Rubel and Jones, 2014). Personalised pricing, for example, can be “an invitation to leave quietly” issued to data subjects deemed to lack value or the capacity to pay. 16
Reasons to consider discriminatory effects as
Transformative effects leading to challenges for autonomy
Value-laden decisions made by algorithms can also pose a threat to the autonomy of data subjects. The reviewed literature in particular connects personalisation algorithms to these threats. Personalisation can be defined as the construction of choice architectures which are not the same across a sample (Tene and Polonetsky, 2013a). Similar to explicitly persuasive technologies, algorithms can nudge the behaviour of data subjects and human decision-makers by filtering information (Ananny, 2016). Different content, information, prices, etc. are offered to groups or classes of people within a population according to a particular attribute, e.g. the ability to pay.
Personalisation algorithms tread a fine line between supporting and controlling decisions by filtering which information is presented to the user based upon in-depth understanding of preferences, behaviours, and perhaps vulnerabilities to influence (Bozdag, 2013; Goldman, 2006; Newell and Marabelli, 2015; Zarsky, 2016). Classifications and streams of behavioural data are used to match information to the interests and attributes of data subjects. The subject's autonomy in decision-making is disrespected when the desired choice reflects third party interests above the individual's (Applin and Fischer, 2015; Stark and Fins, 2013).
This situation is somewhat paradoxical. In principle, personalisation should improve decision-making by providing the subject with only relevant information when confronted with a potential information overload; however, deciding which information is relevant is inherently subjective. The subject can be pushed to make the “institutionally preferred action rather than their own preference” (Johnson, 2013); online consumers, for example, can be nudged to fit market needs by filtering how products are displayed (Coll, 2013). Lewis and Westlund (2015: 14) suggest that personalisation algorithms need to be taught to ‘act ethically’ to strike a balance between coercing and supporting users’ decisional autonomy.
Personalisation algorithms reduce the diversity of information users encounter by excluding content deemed irrelevant or contradictory to the user's beliefs (Barnet, 2009; Pariser, 2011). Information diversity can thus be considered an enabling condition for autonomy (van den Hoven and Rooksby, 2008). Filtering algorithms that create ‘echo chambers’ devoid of contradictory information may impede decisional autonomy (Newell and Marabelli, 2015). Algorithms may be unable to replicate the “spontaneous discovery of new things, ideas and options” which appear as anomalies against a subject's profiled interests (Raymond, 2014). With near ubiquitous access to information now feasible in the internet age, issues of access concern whether the ‘right’ information can be accessed, rather than any information at all. Control over personalisation and filtering mechanisms can enhance user autonomy, but potentially at the cost of information diversity (Bozdag, 2013). Personalisation algorithms, and the underlying practice of analytics, can thus both enhance and undermine the agency of data subjects.
Transformative effects leading to challenges for informational privacy
Algorithms are also driving a transformation of notions of privacy. Responses to discrimination, de-individualisation and the threats of opaque decision-making for data subjects' agency often appeal to informational privacy (Schermer, 2011), or the right of data subjects to “shield personal data from third parties.” Informational privacy concerns the capacity of an individual to control information about herself (Van Wel and Royakkers, 2004), and the effort required by third parties to obtain this information.
A right to identity derived from informational privacy interests suggests that opaque or secretive profiling is problematic. 17 Opaque decision-making by algorithms (see ‘Inconclusive evidence leading to unjustified actions’ section) inhibits oversight and informed decision-making concerning data sharing (Kim et al., 2014). Data subjects cannot define privacy norms to govern all types of data generically because their value or insightfulness is only established through processing (Hildebrandt, 2011; Van Wel and Royakkers, 2004).
Beyond opacity, privacy protections based upon identifiability are poorly suited to limit external management of identity via analytics. Identity is increasingly influenced by knowledge produced through analytics that makes sense of growing streams of behavioural data. The ‘identifiable individual’ is not necessarily a part of these processes. Schermer (2011) argues that informational privacy is an inadequate conceptual framework because profiling makes the identifiability of data subjects irrelevant.
Profiling seeks to assemble individuals into meaningful groups, for which identity is irrelevant (Floridi, 2012; Hildebrandt, 2011; Leese, 2014). Van Wel and Royakkers (2004: 133) argue that external identity construction by algorithms is a type of de-individualisation, or a “tendency of judging and treating people on the basis of group characteristics instead of on their own individual characteristics and merit.” Individuals need never be identified when the profile is assembled to be affected by the knowledge and actions derived from it (Louch et al., 2010: 4). The individual's informational identity (Floridi, 2011) is breached by meaning generated by algorithms that link the subject to others within a dataset (Vries, 2010).
Current regulatory protections similarly struggle to address the informational privacy risks of analytics. ‘Personal data’ is defined in European data protection law as data describing an
Traceability leading to moral responsibility
When a technology fails, blame and sanctions must be apportioned. One or more of the technology's designer (or developer), manufacturer or user are typically held accountable. Designers and users of algorithms are typically blamed when problems arise (Kraemer et al., 2011: 251). Blame can only be justifiably attributed when the actor has some degree of control (Matthias, 2004) and intentionality in carrying out the action.
Traditionally, computer programmers have had “control of the behaviour of the machine in every detail” insofar as they can explain its design and function to a third party (Matthias, 2004). This traditional conception of responsibility in software design assumes the programmer can reflect on the technology's likely effects and potential for malfunctioning (Floridi et al., 2014), and make design choices to choose the most desirable outcomes according to the functional specification (Matthias, 2004). With that said, programmers may only retain control in principle due to the complexity and volume of code (Sandvig et al., 2014), and the use of external libraries often treated by the programmer as ‘black boxes’ (cf. Note 7).
Superficially, the traditional, linear conception of responsibility is suitable to non-learning algorithms. When decision-making rules are ‘hand-written’, their authors retain responsibility (Bozdag, 2013). Decision-making rules determine the relative weight given to the variables or dimensions of the data considered by the algorithm. A popular example is Facebook's EdgeRank personalisation algorithm, which prioritises content based on date of publication, frequency of interaction between author and reader, media type, and other dimensions. Altering the relative importance of each factor changes the relationships users are encouraged to maintain. The party that sets confidence intervals for an algorithm's decision-making structure shares responsibility for the effects of the resultant false positives, false negatives and spurious correlations (Birrer, 2005; Johnson, 2013; Kraemer et al., 2011). Fule and Roddick (2004: 159) suggest operators also have a responsibility to monitor for ethical impacts of decision-making by algorithms because “the sensitivity of a rule may not be apparent to the miner … the ability to harm or to cause offense can often be inadvertent.” Schermer (2011) similarly suggests that data processors should actively searching for errors and bias in their algorithms and models. Human oversight of complex systems as an accountability mechanism may, however, be impossible due to the challenges for transparency already mentioned (see ‘Inscrutable evidence leading to opacity’ section). Furthermore, humans kept ‘in the loop’ of automated decision-making may be poorly equipped to identify problems and take corrective actions (Elish, 2016).
Particular challenges arise for algorithms with learning capacities, which defy the traditional conception of designer responsibility. The model requires the system to be well-defined, comprehensible and predictable; complex and fluid systems (i.e. one with countless decision-making rules and lines of code) inhibit holistic oversight of decision-making pathways and dependencies. Machine learning algorithms are particularly challenging in this respect (Burrell, 2016; Matthias, 2004; Zarsky, 2016), seen for instance in genetic algorithms that program themselves. The traditional model of responsibility fails because “nobody has enough control over the machine's actions to be able to assume the responsibility for them” (Matthias, 2004: 177).
Allen et al. (2006: 14) concur in discussing the need for ‘machine ethics’: “the modular design of systems can mean that no single person or group can fully grasp the manner in which the system will interact or respond to a complex flow of new inputs.” From traditional, linear programming through to autonomous algorithms, behavioural control is gradually transferred from the programmer to the algorithm and its operating environment (Matthias, 2004: 182). The gap between the designer's control and algorithm's behaviour creates an
Related segments of the literature address the ‘ethics of automation’, or the acceptability of replacing or augmenting human decision-making with algorithms (Naik and Bhide, 2014). Morek (2006) finds it problematic to assume that algorithms can replace skilled professionals in a like-for-like manner. Professionals have implicit knowledge and subtle skills (cf. Coeckelbergh, 2013; MacIntyre, 2007) that are difficult to make explicit and perhaps impossible to make computable (Morek, 2006). When algorithmic and human decision-makers work in tandem, norms are required to prescribe when and how human intervention is required, particularly in cases like high-frequency trading where real-time intervention is impossible before harms occur (Davis et al., 2013; Raymond, 2014).
Algorithms that make decisions can be considered blameworthy agents (Floridi and Sanders, 2004a; Wiltshire, 2015). The moral standing and capacity for ethical decision-making of algorithms remains a standout question in machine ethics (e.g. Allen et al., 2006; Anderson, 2008; Floridi and Sanders, 2004a). Ethical decisions require agents to evaluate the desirability of different courses of actions which present conflicts between the interests of involved parties (Allen et al., 2006; Wiltshire, 2015).
For some, learning algorithms should be considered moral agents with some degree of moral responsibility. Requirements for moral agency may differ between humans and algorithms; Floridi and Sanders (2004b) and Sullins (2006) argue, for instance, that ‘machine agency’ requires significant autonomy, interactive behaviour, and a role with causal accountability, to be distinguished from moral responsibility, which requires intentionality. As suggested above, moral agency and accountability are linked. Assigning moral agency to artificial agents can allow human stakeholders to shift blame to algorithms (Crnkovic and Çürüklü, 2011). Denying agency to artificial agents makes designers responsible for the unethical behaviour of their semi-autonomous creations; bad consequences reflect bad design (Anderson and Anderson, 2014; Kraemer et al., 2011; Turilli, 2007). Neither extreme is entirely satisfactory due to the complexity of oversight and the volatility of decision-making structures.
Beyond the nature of moral agency in machines, work in machine ethics also investigates how best to design moral reasoning and behaviours into autonomous algorithms as artificial moral and ethical agents 18 (Anderson and Anderson, 2007; Crnkovic and Çürüklü, 2011; Sullins, 2006; Wiegel and Berg, 2009). Research into this question remains highly relevant because algorithms can be required to make real-time decisions involving “difficult trade-offs … which may include difficult ethical considerations” without an operator (Wiegel and Berg, 2009: 234).
Automation of decision-making creates problems of ethical consistency between humans and algorithms. Turilli (2007) argues algorithms should be constrained “by the same set of ethical principles” as the former human worker to ensure consistency within an organisation's ethical standards. However, ethical principles as used by human decision-makers may prove difficult to define and rendered computable. Virtue ethics is also thought to provide rule sets for algorithmic decision-structures which are easily computable. An ideal model for artificial moral agents based on heroic virtues is suggested by Wiltshire (2015), wherein algorithms are trained to be heroic and thus, moral. 19
Other approaches do not require ethical principles to serve as pillars of algorithmic decision-making frameworks. Bello and Bringsjord (2012) insist that moral reasoning in algorithms should not be structured around classic ethical principles because it does not reflect how humans actually engage in moral decision-making. Rather, computational cognitive architectures – which allow machines to ‘mind read’, or attribute mental states to other agents – are required. Anderson and Anderson (2007) suggest algorithms can be designed to mimic human ethical decision-making modelled on empirical research on how intuitions, principles and reasoning interact. At a minimum this debate reveals that a consensus view does not yet exist for how to practically relocate the social and ethical duties displaced by automation (Shackelford and Raymond, 2014).
Regardless of the design philosophy chosen, Friedman and Nissenbaum (1996) argue that developers have a responsibility to design for diverse contexts ruled by different moral frameworks. Following this, Turilli (2007) proposes collaborative development of ethical requirements for computational systems to ground an operational ethical protocol. Consistency can be confirmed between the protocol (consisting of a decision-making structure) and the designer's or organisation's explicit ethical principles (Turilli and Floridi, 2009).
Points of further research
As the preceding discussion demonstrates, the proposed map (see ‘Map of the ethics of algorithms’ section) can be used to organise current academic discourse describing ethical concerns with algorithms in a principled way, on purely epistemic and ethical grounds. To borrow a concept from software development, the map can remain perpetually ‘in beta’. As new types of ethical concerns with algorithms are identified, or if one of the six described types can be separated into two or more types, the map can be revised. Our intention has been to describe the state of academic discourse around the ethics of algorithms, and to propose an organising tool for future work in the field to bridge linguistic and disciplinary gaps. Our hope is that the map will improve the precision of how ethical concerns with algorithms are described in the future, while also serving as a reminder of the limitations of merely methodological, technical or social solutions to challenges raised by algorithms. As the map indicates, ethical concerns with algorithms are multi-dimensional and thus require multi-dimensional solutions.
While the map provides the bare conceptual structure we need, it still must be populated as deployment and critical studies of algorithms proliferate. The seven themes identified in the preceding sections identify where the ‘ethics of algorithms’ currently lies on the map. With this in mind, in this section we raise a number of topics not yet receiving substantial attention in the reviewed literature related to the transformative effects and traceability of algorithms. These topics can be considered future directions of travel for the ethics of algorithms as the field expands and matures.
Concerning transformative effects, algorithms change how identity is constructed, managed and protected by privacy and data protection mechanisms (see ‘Transformative effects leading to challenges for informational privacy’ section). Informational privacy and identifiability are typically closely linked; an individual has privacy insofar as she has control over data and information about her. Insofar as algorithms transform privacy by rendering identifiability less important, a theory of privacy responsive to the reduced importance of identifiability and individuality is required.
Van Wel and Royakkers (2004) urge a re-conceptualisation of personal data, where equivalent privacy protections are afforded to ‘group characteristics’ when used in place of ‘individual characteristics’ in generating knowledge about or taking actions towards an individual. Further work is required to describe how privacy operates at group level, absent of identifiability (e.g. Mittelstadt and Floridi, 2016; Taylor et al., 2017). Real world mechanisms to enforce privacy in analytics are also required. One proposal mentioned in the reviewed literature is to develop privacy preserving data mining techniques which do not require access to individual and identifiable records (Agrawal and Srikant, 2000; Fule and Roddick, 2004). Related work is already underway to detect discrimination in data mining (e.g. Barocas, 2014; Calders and Verwer, 2010; Hajian et al., 2012), albeit limited to detection of
Concerning traceability, two key challenges for apportioning responsibility for algorithms remain under-researched. First, despite a wealth of literature addressing the moral responsibility and agency of algorithms, insufficient attention has been given to
Second, substantial trust is already placed in algorithms, in some cases affecting a
A related problem concerns malfunctioning and resilience. The need to apportion responsibility is acutely felt when algorithms malfunction. Unethical algorithms can be thought of as malfunctioning software-artefacts that do not operate as intended. Useful distinctions exists between errors of design (types) and errors of operation (tokens), and between the failure to operate as intended (dysfunction) and the presence of unintended side-effects (misfunction) (Floridi et al., 2014). Misfunctioning is distinguished from mere negative side effects by
Both types of malfunctioning imply distinct responsibilities for algorithm and software developers, users and artefacts. Additional work is required to describe fair apportionment of responsibility for dysfunctioning and misfunctioning across large development teams and complex contexts of use. Further work is also required to specify requirements for resilience to malfunctioning as an ethical ideal in algorithm design. Machine learning in particular raises unique challenges, because achieving the intended or “correct” behaviour does not imply the absence of errors 20 (cf. Burrell, 2016) or harmful actions and feedback loops. Algorithms, particularly those embedded in robotics, can for instance be made safely interruptible insofar as harmful actions can be discouraged without the algorithm being encouraged to deceive human users to avoid further interruptions (Orseau and Armstrong, 2016).
Finally, while a degree of transparency is broadly recognised as a requirement for traceability, how to operationalise transparency remains an open question, particularly for machine learning. Merely rendering the code of an algorithm transparent is insufficient to ensure ethical behaviour. Regulatory or methodological requirements for algorithms to be
All of the challenges highlighted in this review are addressable in principle. As with any technological artefact, practical solutions will require cooperation between researchers, developers and policy-makers. A final but significant area requiring further work is the translation of extant and forthcoming policy applicable to algorithms into realistic regulatory mechanisms and standards. The forthcoming EU General Data Protection Regulation (GDPR) in particular is indicative of the challenges to be faced globally in regulating algorithms. 21
The GDPR stipulates a number of responsibilities of data controllers and rights of data subjects relevant to decision-making algorithms. Concerning the former, when undertaking profiling controllers will be required to evaluate the potential consequences of their data-processing activities via a data protection impact assessment (Art. 35(3)(a)). In addition to assessing privacy hazards, data controllers also have to communicate these risks to the persons concerned. According to Art. 13(2)(f) and 14(2)(g) data controllers are obligated to inform the data subjects about existing profiling methods, its
On the rights of data subjects, the GDPR generally takes a self-determination approach. Data subjects are granted a right to object to profiling methods (Art. 21) and a right not to be subject to solely automated processed individual decision-making 23 (Art. 22). In these and similar cases the person concerned either has the right to object that such methods are used or should at least have the right to “obtain human intervention” in order to express their views and to “contest the decision” (Art. 22(3)).
At first glance these provisions defer control to the data subjects and enable them to decide how their data are used. Notwithstanding that the GDPR bears great potential to improve data protection, a number of exemptions limit the rights of data subjects. 24 The GDPR can be a toothless or a powerful mechanism to protect data subjects dependent upon its eventual legal interpretation: the wording of the regulation allows either to be true. Supervisory authorities and their future judgments will determine the effectiveness of the new framework. 25 However, additional work is required in parallel to provide normative guidelines and practical mechanisms for putting the new rights and responsibilities into practice.
These are not mundane regulatory tasks. For example, the provisions highlighted above can be interpreted to mean automated decisions must be
Conclusion
Algorithms increasingly mediate digital life and decision-making. The work described here has made three contributions to clarify the ethical importance of this mediation: (1) a review of existing discussion of ethical aspects of algorithms; (2) a prescriptive map to organise discussion; and (3) a critical assessment of the literature to identify areas requiring further work to develop the ethics of algorithms.
The review undertaken here was primarily limited to literature explicitly discussing algorithms. As a result, much relevant work performed in related fields is only briefly touched upon, in areas such as ethics of artificial intelligence, surveillance studies, computer ethics and machine ethics. 27 While it would be ideal to summarise work in all the fields represented in the reviewed literature, and thus in any domain where algorithms are in use, the scope of such as an exercise is prohibitive. We must therefore accept that there may be gaps in coverage for topics discussed only in relation to specific types of algorithms, and not for algorithms themselves. Despite this limitation, the prescriptive map is purposefully broad and iterative to organise discussion around the ethics of algorithms, both past and future.
Discussion of a concept as complex as ‘algorithm’ inevitably encounters problems of abstraction or ‘talking past each other’ due to a failure to specify a level of abstraction (LoA) for discussion, and thus limit the relevant set of observables (Floridi, 2008). A mature ‘ethics of algorithms’ does not yet exist, in part because ‘algorithm’ as a concept describes a prohibitively broad range of software and information systems. Despite this limitation, several themes emerged from the literature that indicate how ethics can coherently be discussed when focusing on algorithms, independently of domain-specific work.
Mapping these themes onto the prescriptive framework proposed here has proven helpful to distinguish between the kinds of ethical concerns generated by algorithms, which are often muddled in the literature. Distinct epistemic and normative concerns are often treated as a cluster. This is understandable, as the different concerns are part of a web of interdependencies. Some of these interdependencies are present in the literature we reviewed, like the connection between bias and discrimination (see ‘Misguided evidence leading to bias’ and ‘Unfair outcomes leading to discrimination’ sections) or the impact of opacity on the attribution of responsibility (see ‘Inscrutable evidence leading to opacity’ and ‘Traceability leading to moral responsibility’ sections).
The proposed map brings further dependencies into focus, like the multi-faceted effect of the presence and absence of epistemic deficiencies on the ethical ramifications of algorithms. Further, the map demonstrates that solving problems at one level does not address all types of concerns; a perfectly auditable algorithmic decision, or one that is based on conclusive, scrutable and well-founded evidence, can nevertheless cause unfair and transformative effects, without obvious ways to trace blame among the network of contributing actors. Better methods to produce evidence for some actions need not rule out all forms of discrimination for example, and can even be used to discriminate more efficiently. Indeed, one may even conceive of situations where less discerning algorithms may have fewer objectionable effects.
More importantly, as already repeatedly stressed in the above overview, we cannot in principle avoid epistemic and ethical residues. Increasingly better algorithmic tools can normally be expected to rule out many obvious epistemic deficiencies, and even help us to detect well-understood ethical problems (e.g. discrimination). However, the full conceptual space of ethical challenges posed by the use of algorithms cannot be reduced to problems related to easily identified epistemic and ethical shortcomings. Aided by the map drawn here, future work should strive to make explicit the many implicit connections to algorithms in ethics and beyond.