
Abstract
Introduction
Combustion of coal will emit a large amount of air pollutants, including suspended particulates (PM10), fine suspended particulates (PM2.5), nitrogen oxides (NOx), sulphur oxides (SO2) and carbon dioxide (CO2). 1 A number of past studies, such as Agarwal et al., 2 Abdolahnejad et al., 3 Li et al. 4 and the World Health Organization, 5 warned that PM10 and PM2.5 can cause respiratory- and cardiovascular-related diseases and even death. In addition, the excessive concentration of SO2 may cause asthma, chest tightness and shortness of breath in asthmatic people. 6 Furthermore, SO2 and NOx are the main causes of acid rain. 7 CO2 is also the main gas responsible for the greenhouse effect. 8 As the main component of ground-level ozone, NOx not only causes chronic obstructive pulmonary disease 9 but also has adverse effects on the respiratory tract and eyes and is one of the main culprits of the greenhouse effect and acid rain. 10
Thermal power plants take various treatments to eliminate pollutant emissions to reduce threats to the human body, such as respiratory diseases, heart disease, lung disease and even lung cancer. 11 Many such treatments have been extensively investigated, such as load reduction, the installation of pollution prevention and control equipment (including selective non-catalyst denitration and selective catalytic reduction (SCR) equipment), the optimization of boiler configuration and combustion conditions (e.g. combustion temperature, oxidizing or reducing atmosphere and residence time) and the reduction of coal combustion ratio (coal reduction).12–14 Some studies have also predicted the NOx concentration according to the parameters and settings of the combustion process and equipment.15–17 However, how to reduce coal-fired NOx emissions through the selection of coal is rarely discussed. This study aims to fill this gap.
This study aims to propose a methodology to optimize the coal composition before combustion to reduce possible NOx emission, and then, other treatments can also be taken to optimize the boiler configuration and combustion conditions with the aid of pollution prevention and control equipment. In other words, the methodology in this study is a pretreatment.
Some state-of-the-art methods for similar purposes are reviewed below. First, the topic discussed in this study is clearly a big data problem, where big data analysis techniques such as dimensionality reduction and deep learning (deep neural networks (DNNs)) are usually applied.
18
For example, Yang et al.
19
reduced the number of possible factors (i.e. the parameters and conditions of a decentralized control system (DCS)) for predicting NOx emission using principal component analysis (PCA). Then, a long short-term memory (LSTM) network was constructed to predict NOx emission. Furthermore, some basic forecasting methods for predicting NOx emissions are often compared to select the most suitable predictor. For example, Yuan et al.
20
proposed a stacked-generalization ensemble method (SGEM) combining back propagation network (BPN), support vector regression (SVR), decision tree and linear regression to accurately predict NOx emissions inside a denitration reactor. Thirty factors including total airflow rate, total coal flow rate, total primary air rate, total secondary air rate and overfire air (OFA) were considered. PCA was also used for dimensionality reduction. In addition, data decomposition has also been proven to be a feasible treatment. For example, to accurately predict NOx emissions from a power plant, Wang et al.
21
applied the completely integrated empirical mode decomposition adaptive noise (CEEMDAN) method to decompose the collected time-series data into parts from which relevant data features were extracted. For each part, a LSTM was constructed. In sum, the existing methods have the following problems:
Prediction of NOx concentration emitted from coal combustion based on coal composition has not been studied in the past. Dimensionality reduction, predictor composition and data classification (or clustering) are three big data analysis techniques commonly used to predict NOx emissions. However, there are no absolute rules for classifying the collected data. Past research in the field has rarely considered this uncertainty. In addition, past studies have attempted to find the most appropriate predictors for each part of the data. However, applying multiple predictors to the same part may yield better predictive performance.
To tackle these problems, a fuzzy big data analytics approach is proposed in this study to predict NOx emissions from coal combustion. The fuzzy big data analytics approach includes the application of some existing (big) data analytics techniques, such as random forest (RF), recursive feature elimination (RFE), fuzzy c-means (FCM),22,23 deep learning and feedforward neural network (FNN).24,25 These techniques are used for feature selection, data clustering, forecasting and aggregation, respectively, as described in Table 1. In the proposed methodology, the collected data are fuzzy clustered so that multiple predictors can be applied to each cluster simultaneously, which is expected to further improve the predictive performance.
Mapping the parts of the proposed methodology to big data analytics functionalities.

Literature review
Some relevant references are reviewed below. Prediction of NOx emissions is a very challenging task. The current state of the art for this purpose can be broadly divided into two categories, namely traditional combustion mechanism modelling techniques and data-driven predictive models.26,27
Traditional combustion mechanism modelling techniques are time-consuming, laborious and complex and require relevant background knowledge about various thermodynamic phenomena such as heat, combustion and transformation of mass to represent the combustion process as a mathematical model. 28
To build a data-driven predictive model, there are many factors that affect NOx emissions, including boiler design, coal composition and conditions that must be controlled during combustion (such as boiler load, oxygen content and air intake). When building the model, the amount of data required is large, and there are many parameters related to the combustion process that must be considered. 29 Nonlinear transformation processes and correlations between variables make forecasting even more difficult. 30 Therefore, it is a very difficult task to build an accurate model to predict NOx emissions, and the prediction accuracy will decrease with the aging of related equipment such as boilers. 31
Hill and Smoot 17 discussed the modelling of NOx emissions from some combustion systems, especially coal-fired systems. They also introduced the control technology of NOx emissions, the reaction process, the calculation of the chemical kinetics in the flame and some applications of NOx emission modeling.
Dıez et al. 16 applied computational fluid dynamics (CFD) to conduct numerical simulation based on NOx chemistry model, fluid, particle flow, solid fuel combustion, etc. and then suggested to reduce NOx emissions using OFA operations.
Belosevic et al. 15 built several combustion models for mathematical analysis in order to improve the combustion efficiency of the boiler. They also predicted NOx emissions by considering combustion conditions such as exhaust gas temperature, NO concentration and velocity field.
Madhavan et al. 32 constructed an artificial neural network (ANN) to predict NOx emissions from power plant boilers. First, inputs to the ANN were chosen from 15 variables using F-test as boiler load, coal flow, air flow, humidity, volatile carbon, nitrogen and excess air. The ANN was a generalized regression neural network, the most important hyperparameter of which, the smoothing factor, was determined using a genetic algorithm. According to experimental results, the mean absolute error (MAE) of predicting NOx emissions could be reduced to 6.58 mg/Nm3.
Zhou et al. 33 built a SVR model combined with an ant colony optimization (ACO) algorithm to optimize two important hyperparameters of the SVR: C and Gaussian kernel, so as to predict NOx emissions from coal-fired power plant boilers. Although the current continuous emission monitoring system used to detect NOx and other exhaust gases was highly reliable, it was too expensive and laborious to maintain. Another alternative was to use a portable pollution measurement device that derived NOx emissions from related parameters. Therefore, if the relationship between NOx and these parameters during combustion can be clarified, the detection cost will be greatly reduced. In total, 22 parameters were considered by Zhou et al., including boiler pressure, primary wind speed, secondary wind speed, oxygen content and total air flow. They compared the performance of the SVR + ACO method with those of three existing methods. According to experimental result, ACO + SVR achieved the best derivation performance. MAE was only 1.60 mg/Nm3.
Yang et al. 34 believed that NOx is the main pollutant emitted by thermal power plants and an accurate prediction model should be established so that the prediction result serves as a benchmark for NOx reduction. They first applied PCA to remove the coupling between the original variables and then constructed an LSTM neural network to predict NOx emissions. In this way, NOx emissions from coal combustion were considered as a dynamic, continuous process and current emissions were influenced by previous emissions, which was a time-series problem. The original inputs contained 35 variables collected from a DCS: primary and secondary air flow rate, temperature, boiler load, total air flow, steam temperature, etc., which were reorganized into 6 new variables via PCA. More than 10,000 continuous data have been collected. The LSTM model consisted of one input layer, two hidden layers and one output layer. The results showed that the LSTM model outperformed several existing methods including a recurrent neural network (RNN) and a least squares support vector machine (LSSVM) by reducing root mean squared error (RMSE) to only 2.73 mg/Nm3 in less than 2 min.
Yuan et al. 20 applied the SGEM to accurately predict NOx emissions inside a denitration reactor, in which BPN, SVR and decision tree were regarded as level 0 models (base models) and linear regression was used as the level 1 model (meta model) to aggregate the prediction results of the above three basic models. Based on past research and the experience of engineers, 31 variables were chosen, including total airflow rate, total coal flow rate, total primary air rate, total secondary air rate and OFA. Before inputting these variables into the model, feature extraction was conducted using PCA to reduce the high dimensionality of data. Next, feature selection was performed based on the mutual information between the variables. Finally, 12 features were selected as the input variables of the model. A total of 8640 data were collected, of which 80% were used as the training set and the remaining 20% were used as test set. Experimental results showed that the SGEM method achieved the minimum RMSE that was only 12.12 mg/Nm3.
Methodology
Procedure
In order to predict NOx emissions, a fuzzy big data analytics approach is proposed in this study, which is composed of six steps, namely feature selection, fuzzy clustering, prediction model construction, prediction, aggregation and performance evaluation:
Step 1. Select relevant features using RF-RFE. Step 2. Cluster the collected data using FCM. Step 3. Build a prediction model for each cluster and optimize the model. Step 4. Apply the prediction models of all clusters to make predictions. Step 5. Aggregate the prediction results by considering the membership to each cluster. Step 6. Evaluate the forecasting performance.
Feature selection
In this study, RF-RFE is used to screen input features that are more relevant to NOx emission prediction. Based on certain feature selection criteria, the least relevant features are removed one by one from all features.
Input features include Specify the minimum number of features Initialize a feature set containing all features. Train a RF with the feature set to get the importance of each feature. Sort these features by their importance. Remove the feature with the lowest importance to get a new feature set. If the number of features <
Data clustering
Clustering the collected data before making predictions has proven to be an effective way to deal with prediction problems involving big data. 35 RFs, decision trees and classification and regression trees (CARTs) cluster data before making predictions. 36 However, not all features are taken into account when clustering data. The priorities of different properties might not be equal. Nonetheless, clustering based on the minimization of the prediction error is a clear advantage, even if the prediction mechanism is simplistic. In addition, there is no absolute way to cluster data. For these reasons, FCM37,38 is applied in the proposed methodology to cluster the collected data.
FCM clusters the collected data by minimizing the following objective function:
The objective function can be optimized according to the following procedure: 39
Step 1. Establish an initial clustering result.
Step 2. (Iterations) Obtain the centroid of each cluster as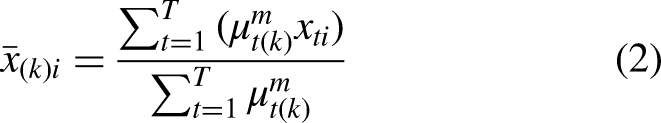


Step 3. Re-measure the distance of each example to the centroid of every cluster, and recalculate the membership.
Step 4. Stop if the following condition is satisfied. Otherwise, return to Step 2:
Furthermore, to determine the optimal number of clusters (i.e. 




Another way to determine the optimal number of clusters is through trial and error, i.e. to maximize the forecasting accuracy by varying the number of clusters.
Building prediction models
Five types of prediction models are built in the proposed methodology: DNNs (FNNs with multiple hidden layers), SVR, CART, extreme gradient boosting (XGBoost) and RFs. These methods have been widely used and are briefly introduced as follows.
DNN
DNNs are the combination of deep learning and ANNs, and there are various ways to form such combinations. In the proposed methodology, the DNN is an FNN with multiple hidden layers, as illustrated in Figure 1.

Architecture of the DNN.
The inputs to the DNN are the factors related to predicting the NOx emission of example 


Between two successive hidden layers, the following operations are performed:





To determine the values of network parameters, the DNN is trained using the Levenberg–Marquardt (LM) algorithm in the proposed methodology. For details refer to Suzuki. 42
SVR
As an extension of support vector machine (SVM), the concept of SVR is to use a kernel function to map data to a high-dimensional space to find a hyperplane and then create a decision boundary on both sides of it. If an example falls outside the boundary, the loss is calculated, as illustrated in Figure 2. Depending on the kernel function, SVM can handle linear or nonlinear problems. One advantage of SVR is that it is less prone to overfitting problems.

The concept of SVR.
SVR aims to fit a multiple regression function to predict the output according to the inputs. The multiple regression function can be written as:




CART
The procedure for constructing a CART is composed of three stages: tree growing, stopping and pruning. The first stage is growing a tree using a recursive partitioning technique that selects a variable and a split point according to the prespecified criterion. Common criteria include Gini, towing, ordered towing and maximum-deviance reduction. 43 This study adopts the last criterion.
Let 


XGBoost
XGBoost is a popular machine learning algorithm in recent years. The algorithm was proposed by Chen and Guestrin. 44 It is an extension of gradient boosting decision tree (GBDT) that combines the advantages of bagging and boosting. The former performs feature sampling in a random manner; the latter generates trees in a sequential manner. A tree generated later is related to the previous tree and can correct the error of the latter.
RF
A RF consists of multiple decision trees, each of which is constructed based on a replaceable sampling of the training data, that is, bootstrapping. Due to replacement after random sampling, some data may be double-selected and some will never be selected. The latter is called out-of-bag (OOB) data. Random samples are used to build/train a forest of multiple decision trees to predict the NOx emission. The trained decision trees are then applied to make predictions for the OOB data. The predictions produced by all decision trees are averaged; on this basis, the prediction performance is evaluated in terms of RMSE:
Aggregation
An example can be classified into multiple clusters to various degrees using FCM. Therefore, the prediction models of these clusters can be applied to make predictions for the example. Then, these prediction results are aggregated. To this end, three aggregators are considered: FNN,45,46 SVR and RF, as illustrated in Figure 3. Inputs to these aggregators are the memberships of the example to various clusters and the corresponding prediction results. Among possible aggregators, the most accurate one that minimizes RMSE will be chosen. The output from the aggregator, the aggregation result, is the predicted NOx emission.
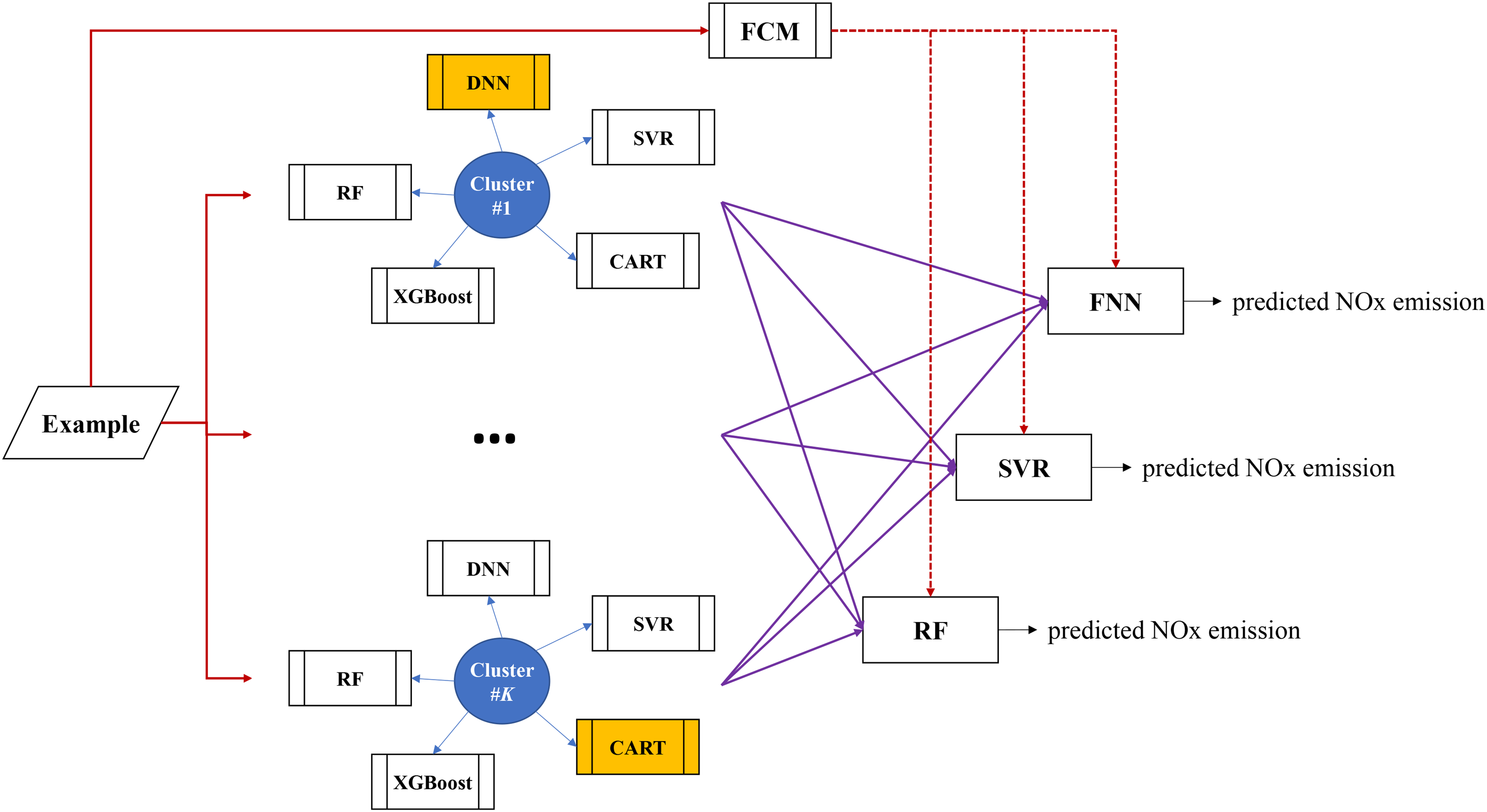
The aggregation process.
Case study
Background
To illustrate the applicability of the proposed methodology, it has been applied to analyze the coal combustion-related data provided by a thermal power plant in Taiwan. In the proposed methodology, XGBoost, SVR, RF and decision trees were implemented using Python, which selected hyperparameters using grid search to facilitate model optimization. FCM and FNNs (or DNNs) were constructed using the related toolboxes of MATLAB.
The data collection period was from January 2019 to December 2019. The collected data included 317 examples (i.e. coal batches). Input variables to each prediction model were the specification and composition of coal in terms of 19 features: heating value (as received), heating value (air dried), ash, sulphur, volatile nitrogen, coke nitrogen, total moisture, inherent moisture, grinding rate, Na2O, CaO, MgO, Fe2O3, K2O, SiO2, Al2O3, TiO2, softening point and air. The output from the prediction model was the NOx emission (ppm).
Application of the proposed methodology
First, box-and-whisker plots were used to identify outliers, that is, values that fell outside 1.5 times the interquartile range of Q1 and Q3, to remove them. As a result, the number of examples reduced to 243.
Then, feature selection was carried out using RF-RFE with cross-validation. The importance of features evaluated by RF were ranked. The result is presented in Table 2. In the subsequent process of combustion, volatile nitrogen and coke nitrogen are burned to generate NOx and N2 respectively, so the final products of fuel nitrogen after complete combustion are NOx and nitrogen. After removing the least important features, the model was re-trained. Finally, the best number of features was determined as 15. CV was set to 3. Therefore, input variables to each prediction model included heating value (as received), ash, sulphur, volatile nitrogen, coke nitrogen, inherent moisture, grinding rate, Na2O, CaO, MgO, Fe2O3, K2O, SiO2, softening point and air. The prediction accuracy, in terms of mean absolute percentage error (MAPE) and RMSE, using various prediction models before and after feature selection is compared in Table 3. After feature selection, the prediction accuracy of most forecasting models was improved.
Ranking the importance of features.

Comparison of prediction performances using various models before and after feature selection.

Subsequently, the collected data were divided into two and three clusters using FCM, and the most suitable model for each cluster was identified. Then, the data of each cluster were randomly divided into 60% for training the prediction model (XGBoost, SVR, RF, decision tree or DNN), 30% for training the aggregation model (FNN, SVR or RF) and 10% for evaluating the prediction performance. The hyperparameters of XGBoost, SVR, RF and decision trees were optimized using grid search by setting CV to 3, as shown in Table 4. In addition, the number of hidden layers in the DNN and the number of neurons in each hidden layer were selected by trial and error. Each configuration of the DNN was trained 10 times, and the optimal configuration was determined based on the average performance.
Hyperparameters of various prediction models.

First, the collected data were divided into two clusters. By assigning each example to the cluster with the highest membership, the first cluster had 70 examples, and the second cluster had 75 examples. Then, a suitable prediction model was constructed for each cluster. After comparison, DNN and SVR were suitable for the two clusters in predicting the NOx emission, as shown in Table 5. Subsequently, the collected data were divided into three clusters. The prediction models suitable for the three clusters are summarized in Table 6.
Suitable prediction model for each cluster (two clusters).

Suitable prediction model for each cluster (three clusters).

When a new example came in, the prediction models of all clusters were applied to make predictions, since it was not possible to absolutely classify the example to a single cluster. Then, all prediction results were aggregated. The predicted value by the prediction model of each cluster and the membership that the example belonged to the cluster were used as inputs to the aggregation model.47,48 The output was the predicted NOx emission. The prediction performances using various aggregators were compared. According to the comparison results, RF and SVR were the most suitable aggregators, respectively, when there were two and three clusters, as shown in Table 7. In contrast, without data clustering, the prediction accuracy was MAE = 10.7% and RMSE = 17.72 (ppm). Obviously, dividing the collected into three clusters helped improve the prediction performance.
Prediction performance after aggregation.

Discussion
According to the experimental results, the following discussion was carried out:
From Table 7, it can be easily seen that after feature selection, dividing the collected data into three clusters and then aggregating the prediction results of all clusters with SVR achieved quite good prediction performance. MAPE was only 8.9%, while RMSE also dropped to 14.55 ppm. However, if the collected data were divided into only two clusters, the improvement in the prediction performance was not significant. The effects of different input variables on the output value were not equal. In addition, such effects varied across different prediction models. Table 8 lists the top three input variables that have the most significant effects on the predicted NOx emission in different prediction models. It can be found that volatile nitrogen, air and grinding rate had the top three effects on the predicted NOx emission in most prediction models, so the three factors can be adjusted if the predicted NOx emission is to be reduced, as shown in Table 9. Using most prediction models, the predicted NOx emission increases when volatile nitrogen decreases or grinding rate increases. In addition, when air decreases, the NOx emission drops as well.
Top three input variables with the most significant effects on the predicted NOx emission in various prediction models.

Adjusting three input variables to reduce the predicted NOx emission.

Comparison with existing methods
To further elaborate the effectiveness of the proposed methodology, 10 existing methods have also been applied to the collected data for comparison: LSTM,
19
XGBoost,
49
RFECV + XGBoost, SVR, RFECV + SVR, RF,
49
RFECV + RF, decision trees,
49
RFECV + decision trees, DNN and RFECV + DNN.
50
In the LSTM method, the learning rate varied from 0.005 to 0.05 and the selection of the timestep was set to 5. The forecasting accuracy, in terms of MAPE and RMSE, using various methods is summarized in Table 10. Obviously:
The proposed methodology achieved a better forecasting accuracy by minimizing MAPE and RMSE. The advantage over existing methods was up to 30% in reducing MAPE. Feature selection using RFECV was conducive to the prediction performances of most existing methods except decision trees. The effect was most significant when RFECV was applied to DNN. Compared with the benchmark study by Yang et al.,
19
the predictive performance using the LSTM method was worse when coal composition is considered instead of combustion parameters and conditions. However, as a pretreatment, coal screening by composition remains an interesting attempt, as this has added value for optimizing subsequent combustion processes.
Prediction accuracy using various methods.

Conclusions
With the rise of environmental awareness, more and more people are paying attention to the impact of air quality on health. As one of the main sources of air pollution, thermal power generation has attracted much attention. Governments around the world are also targeting the pollutants emitted by thermal power plants. A series of preventive measures have been taken to prevent pollution, including installing high-efficiency electrostatic precipitators to reduce the escape of fine aerosols, installing flue gas desulfurization equipment to reduce the production of SO2 and building low-NOx burners and SCR equipment for NOx.
The proportion of NOx in the pollutants of coal-fired units is the largest. Therefore, the accurate prediction of NOx emissions after coal combustion is very important for the prevention and control of air pollution. For this purpose, from a novel perspective, this study proposes a fuzzy big data analytics approach, which takes the coal composition as input, and predicts the NOx emission level after coal combustion using fuzzy big data analytics techniques such as feature selection, fuzzy clustering and fuzzy aggregation. The contribution of this study is the selection of better coal for combustion to reduce NOx emissions, in addition to ex post pollution reduction strategies. It provides a new approach for thermal power plants to reduce NOx emissions.
The effectiveness of the fuzzy big data analytics approach has been examined using a real case study. According to experimental results:
If the data were not clustered, XGBoost and RF achieved the best prediction performances. Their MAPEs were only 9.6% and 10.04%, respectively. Feature selection has improved the prediction performances of most existing prediction models. Clustering the collected data into three clusters also improved the prediction accuracy. After clustering the collected data into three clusters, SVR and DNN were the most suitable prediction models for these clusters in optimizing the prediction accuracy. SVR was shown to be the most effective method in aggregating the prediction results of all clusters.
In future studies, different clustering methods such as mean-shift algorithm, Gaussian mixture model, density based spatial clustering algorithm with noise and density peak clustering can be applied to compare their results. In addition, PCA can be applied in data preprocessing to project high-dimensional data into a low-dimensional space through linear transformation, which can reduce the complexity and remove noise.
Contributorship
All authors contributed equally to the writing of this paper.