
Abstract
Introduction
Cancer is a complex and diverse group of diseases characterized by the abnormal and uncontrollable growth of cells, often leading to the formation of malignant tumors capable of infiltrating nearby tissues and metastasizing to other areas of the body. 1 The cervix is a vital, pear-shaped organ that connects the lower part of a woman’s uterus to the vagina. Cervical cancer is one of the deadliest cancers occurring in the cells of the cervix, mostly caused by the human papillomavirus (HPV). According to the annual report of the World Health Organization (WHO), it is the fourth-leading cancer among women around the globe. 2 The documented data for the year 2020 indicates an estimated 6,04,000 new cases and 3,42,000 deaths. 3 Moreover, it revealed a substantial increase in the number of new global cases, surpassing 700,000 within a mere 12 years from 2018 to 2030, representing a significant growth from the current figure of 570,000. An alarming 90% of these new cases and deaths were reported in low- and middle-income countries. This highlights the disproportionate impact of the disease in these regions, as the mortality rate for cervical cancer is increasing annually at a significant rate. 4 This is due to the lack of regular screening programs, limited healthcare access, and awareness about early-stage risk factors. In Bangladesh, cervical cancer is the second most common cancer in females. In the absence of a proper intervention, a cumulative total of 505,703 women in Bangladesh are projected to die of cervical cancer by the year 2070. Furthermore, this figure is expected to increase to 1,042,859 by the year 2120. 5
The alarming statistics necessitate urgent attention and calls for immediate action to ensure early detection of cervical cancer. When detected in the early stage, this fatal disease is highly treatable. Regular screenings, pap smears, HPV tests, and cervical biopsies are effective in detecting abnormalities in the cervical cell wall. Although the expenses and discomfort associated with these surgical processes emphasize the necessity for more cost-effective and reliable approaches to the detection of cervical cancer. Identifying the risk factors for this cancerous condition also eliminates suffering and distress and improves the quality of life. Multiple research studies have demonstrated that early detection of cervical cancer greatly enhances the chances of a patient’s swift recovery. 6 Therefore, by identifying the risk factors, healthcare providers can significantly improve the prognosis of individuals at risk of developing cervical cancer.
Applications of machine learning in ensuring digital healthcare
Artificial intelligence and machine learning (AI–ML) has become a transformative tool in the healthcare sector, enabling more accurate diagnoses, personalized treatments, and efficient healthcare management. 7 By leveraging different sizes of medical data, dealing with inherent discrepancies, and handling challenges imposed by real-world inconsistent data, ML algorithms assist healthcare professionals in making informed decisions, reducing errors, and improving patient outcomes. One of the primary aspects of the application of ML in healthcare is designing optimized algorithms for the early diagnosis of diseases and highlighting the key influencing factors. 8
Additionally, ML models, particularly deep learning algorithms, have demonstrated exceptional performance in diagnosing diseases such as cancer, cardiovascular conditions, and brain-related disorders. Image-based diagnostics using advanced computer vision algorithms have significantly improved radiology, pathology, and dermatology by providing automated and highly accurate image analysis and segmentation techniques. Furthermore, beyond diagnostics and personalized treatment planning, AI–ML is extensively being utilized in interdisciplinary research in biomedical, health informatics, and drug discovery. 9 As ML technology continues to evolve, its integration into healthcare holds immense potential to enhance medical practice and improve overall public health.
AI-powered predictive and histopathological analysis for cervical cancer
AI plays a critical role in cervical cancer detection and classification, offering innovative solutions to enhance the accuracy, efficiency, and accessibility of diagnostic procedures. 10 Recent advances in AI hold tremendous potential for improving the automated detection of cervical pre-cancer and cancer, leading to more accurate and objective outcomes. Moreover, AI has significant potential in recognizing molecular markers linked to cervical cancer, facilitating its diagnosis. ML, a subset of AI, is a powerful tool to identify underlying patterns in input data and discover key indicators of cervical cancer. 11 The demand for applying cutting-edge computational models such as AI and ML has greatly increased due to recent advancements in this field.
ML algorithms are highly effective in handling imbalanced datasets, a prime concern in the healthcare industry where instances are unevenly distributed across target classes. An imbalanced dataset can potentially bias toward the majority class, resulting in the deterioration of the prediction model’s performance. 12 AI and ML algorithms have demonstrated remarkable potential in enhancing diagnostic precision and forecasting patient outcomes by addressing such real-world imbalanced data. Consequently, the healthcare sector actively incorporates these technologies into various areas of patient care and administrative procedures to identify high-risk individuals and develop personalized intervention strategies. This can ultimately lead to earlier detection and more effective treatment of cervical cancer.
Conversely, explainable AI (XAI) methods break down the complex decision-making processes of various sophisticated ML models to ensure transparency and interpretability.13,14 Different XAI methods determine the key factors influencing the prediction model, revealing which features are more important for accurate diagnosis. This ensures the understandability and trustworthiness of the ML models. While most studies primarily concentrate on enhancing classification accuracy through various advanced techniques contributing to feature selection and model development, some research has shifted its focus to XAI for elucidating black-box models using diverse XAI tools.
However, these studies often overlook the integration of domain experts’ opinions and their alignment with XAI explainability. This gap can lead to mismatches in certain cases, necessitating efforts to minimize such discrepancies and gain the trust of domain experts in AI tools. The identified gaps in existing studies motivate us to propose a new direction in research, aiming to enhance transparency for both users and experts in this field.
The primary focus of this investigation is to establish a connection between traditional healthcare methods and advanced AI through XAI. The goal is to address the outlined challenges by leveraging the extensive capacities of ML. To achieve this, a cutting-edge ML system integrated with XAI and domain knowledge is proposed. The ML system aims to make accurate predictions and explain its decisions through XAI techniques. The system improves its interpretability and trustworthiness in critical decision-making processes by incorporating domain knowledge. Furthermore, integrating traditional healthcare methods with advanced AI and XAI can revolutionize patient care and treatment by providing valuable insights and explanations for medical practitioners. This innovative approach can enhance diagnostic accuracy, optimize treatment plans, and ensure that medical decisions are transparent and understandable to healthcare professionals and patients. Ultimately, this research aims to bridge the gap between healthcare and AI, paving the way for more informed and efficient healthcare delivery.
Contributions
The main contributions of this study are summarized as follows:
We propose and design an ML-based cervical cancer risk prediction system, integrating domain knowledge to enhance black-box model explainability for secondary and primary data. We propose a novel hybrid feature selection process combining filter and wrapper methods and introduce a comprehensive preprocessing pipeline that addresses missing values, detects and removes outliers, and handles imbalanced data, resulting in improved outcomes for the ML models to ensure optimal performance. We design a stacking ensemble model to predict cervical cancer with enhanced accuracy and stability, as measured by the precision, recall, and F1 score for individual classes. We integrate two generative AI models in the prediction system to compare the prediction capability of the proposed ML model with generative AI approaches for tabular data. We employ an exploratory data analysis (EDA) system and XAI methods, providing global and local explainability to uncover the underlying patterns within the dataset. We validate the efficacy of XAI explainability by conducting surveys with domain experts, establishing a robust relationship at different levels of understanding.
The paper is structured as follows: Section “Related studies” presents the related literature, Section “Methodology” outlines the methodology, Section “Results” discusses the results, and Section “Conclusion and future work” concludes the findings while pinpointing some future research directions.
Related studies
Cervical cancer detection and prediction have witnessed significant advancements by integrating ML techniques. ML models analyze vast amounts of patient data, assisting in early detection and prognosis. Consequently, numerous researchers have focused on using diverse images and numerical datasets to predict and detect the onset of cervical cancer in its initial phases. Wu and Zhou 15 applied a support vector machine (SVM) classifier to the “Cervical Cancer (Risk Factors)” dataset. 15 The dataset comprises 858 subjects, each with 36 unique attributes. The authors combined SVM with feature selection techniques such as recursive feature elimination (RFE) and principal component analysis (PCA) to identify the top 10 risk factors contributing most to the model’s prediction outcomes. The experimental results showed the superiority of traditional SVM over SVM-RFE and SVM-RF.
Subsequently, Hariprasad et al. 16 utilized the extreme gradient boosting (XGB) model on the same dataset to develop an innovative approach for predicting cervical cancer risk. 16 They extracted the most prominent features and concluded that the random forest (RF) was the best performer, achieving 98.7% accuracy after applying the oversampling technique. Ensemble models have also demonstrated encouraging results in the early prediction of cervical cancer. One study utilized several ensemble methods, including bagging, boosting, and stacking. 17 The results indicate that using a combination of RF, SVM, ExtraTreeClassifier, XGB, and bagging in a stacked ensemble produces the highest classification accuracy of 94.4%. Another recent study, in 2024, proposed such an ensemble model with extensive preprocessing techniques to identify the presence of cervical cancer. 18 This study aimed to enhance the predictive power of the ML model by introducing an RF-based ensemble model. They incorporated two different datasets, namely the “Cervical Cancer (Risk Factors)” dataset from the UCI ML repository and the Behavioral risk dataset (sobar-72) to achieve accuracies of 98.06% and 95.45%, respectively.19,20 Ilyas and Ahmad 21 implemented a voting ensemble classification approach that achieved 94% accuracy, surpassing other models such as decision tree (DT), SVM, KNN, RF, Naïve Bayes, etc. 21 They explored both the aforementioned behavioral risk dataset and the earlier UCI dataset. Researchers conducted a meta-analysis of available literature concerning ML-driven cervical cancer diagnosis, particularly emphasizing ensemble learning methodologies. Kumawat 22 applied six traditional ML algorithms, including an artificial neural network, a Bayesian network, an SVM, a random tree (RT), a logistic tree, and an XGB tree. 22 Although the authors applied three different feature selection algorithms, namely relief rank, wrapper method, and least absolute shrinkage and selection operator regression, the maximum accuracy they could achieve is only 94.94% utilizing all 36 features. This significantly increased the overall model training time and, therefore, model overhead.
Segmentation of cervical cell images has proven to be effective in diagnosing cervical cancer, allowing the tracking of changes in cell walls and lesions. In a study by Song et al., 23 a dynamic multitemplate deformation model was designed to segment each cell from pap-smear images. 23 One major challenge in segmentation tasks is the issue of cell overlapping. Lee and Kim 24 proposed a superpixel partitioning model combined with the triangle threshold for automatically segmenting multiple overlapping cervical cells, demonstrating competitive results compared to other approaches. 24 Another study integrated a data-mining approach with traditional ML algorithms. 25 The authors proposed a two-level cascade integration system combining CR4.5 and logistic regression (LR), achieving an abnormal cell recognition rate of 95.642%, surpassing individual classifiers. Devi et al. 26 implemented a graph-cut-based segmentation model for efficient cervical cancer detection. Applying their method to the Herlev dataset improved overall accuracy by 5.24%. 27
In 2021, a statistical analysis utilized instance-based K-nearest neighbor (KNN), K-Star, split-point and attribute reduced classifier (SPAARC), RT, and RF algorithms. 28 The dataset was collected from both Kaggle and UCI ML repositories, and RF performed best, achieving 98.33% accuracy. In a recent study in 2022, hyperparameter tuning was conducted for early risk prediction of cervical cancer using grid search cross-validation. 29 The performance of various models, including KNN, DT, SVM, RF, and multilayer perceptron (MLP), was thoroughly analyzed, resulting in an accuracy of 93.33%. Kumari et al. 30 applied PCA to overcome the potential problems imposed by the high-dimensional data. 30 After reducing the size of the dataset, they fed the input data into a deep neural network (DNN) classifier. The experimental investigation secured a maximum accuracy of 87.4%.
The predominant focus of research in this domain revolves around improving classifier performance by integrating various preprocessing techniques. Glučina et al. 31 explored different class balancing techniques to tackle the challenge imposed by employing an imbalanced dataset. 31 They achieved the highest area under the curve (AUC) score of 0.95 utilizing MLP and KNN combined with random oversampling, synthetic minority over-sampling technique (SMOTE), and SMOTE Tomek (SMOTETomek). Some studies also explore the elucidation of black-box models using XAI tools, shedding light on diverse aspects of cervical cancer. A study by AlMohimeed et al. 32 introduced a stacked ensemble model for predicting early stage cervical cancer. 32 The authors employed different wrapper and embedded approaches for feature selection, optimized using Bayesian optimization, and finally applied Shapley additive explanations (SHAP) for global explainability, achieving 99.44% accuracy. To ensure model transparency at both local and global scales, another group of researchers incorporated local interpretable model-agnostic explanations (LIME) alongside SHAP. 33 Although the proposed ensemble model achieved 94.5% accuracy, the authors tried to explain clinical observations and interpret features. However, there remains an opportunity to enhance classifier performance further. It is essential in health informatics to craft models that demonstrate superior precision and recall. Consequently, an immediate need exists to align global explainability with local explainability. Equally vital is forging a link between the perspectives of domain experts and the results of XAI tools. This approach fosters trust from domain experts and maximizes the benefits of such studies.
Methodology
Approach overview
In this study, we employ baseline ML models and introduce a stacking ensemble model for the prediction of cervical cancer. The dataset used is sourced from the UCI ML repository, and Figure 1 outlines our two-phase data preprocessing and balancing technique to ensure data consistency and quality.

Overview of the proposed methodology, including data processing, explainable artificial intelligence (AI) tools, and model evaluations.
To make the dataset suitable for ML training, we perform basic preprocessing steps such as handling missing values, detecting and removing outliers, etc. We apply oversampling and undersampling methods to address the challenge of imbalanced classes and investigate the impact of different sampling techniques. The top features are selected using our proposed hybrid feature selection mechanism, which combines filter and wrapper methods. The final preprocessed data is split into training and testing sets and fed into the ML classifiers. Subsequently, we employ XAI tools such as SHAP, ELI5, and LIME to align the results with domain experts and determine the significance of individual features, establishing their impact on the classifiers.
The nature of this study is retrospective and analytical, utilizing publicly available cervical cancer datasets. Additionally, for domain knowledge-driven explainability, this method collects data from the domain experts. This study was conducted from January 2024 to April 2024 in Bangladesh. Most of the data are collected virtually through a Google form by some questionnaire and we meet some of the respondents face to face and collect the information.
Description of the dataset
The dataset employed in this study is the “Cervical Cancer (Risk Factors)” dataset, sourced from the UCI ML repository. 19 Collected from the “Hospital Universitario de Caracas” in Caracas, Venezuela, this dataset encompasses detailed medical records of 858 patients. It comprises 32 attributes and includes four target classes: Hinselmann, cytology, Schiller, and biopsy. Biopsy involves microscopic examination to determine the presence of abnormal cells. In this study, the use of biopsy as the target variable indicates the presence of cervical cancer based on biopsy samples. The target variable comprises two classes: positive, indicating the presence of cervical cancer, and negative, indicating its absence. Table 1 concisely describes the dataset.
Description of the detailed attributes of the dataset.

AIDS: acquired immune deficiency syndrome; CIN: cervical intraepithelial neoplasia; HIV: human immunodeficiency virus; HPV: human papillomavirus; IUD: intrauterine device; STD: sexually transmitted disease.
Data preprocessing pipeline
This research involves a two-phase data processing approach. Initially, we undertake fundamental preprocessing tasks, addressing issues such as handling missing values and detecting outliers. In the subsequent phase, we introduce a novel feature selection process to identify the essential features within the dataset. To evaluate the impact of various data balancing techniques, we employ SMOTE 34 and adaptive synthetic (ADASYN) 35 as oversampling methods, NearMiss as the undersampling method, 36 and the combined over and undersampling technique SMOTETomek. 37 A systematic evaluation of each algorithm is conducted to assess its effectiveness.
Handling missing values
Handling missing values in datasets is crucial to prevent biased results and maintain the precision of ML algorithms. In this study, we substitute the mean for continuous variables and the median for discrete values to address missing values.
Outlier detection
Detecting outliers is crucial in dataset analysis, as these anomalies can significantly impact the effectiveness of ML algorithms. 38 One statistical method for outlier detection is the interquartile range (IQR). This technique calculates the IQR, representing the range between the first quartile (Q1) and the third quartile (Q3). Emphasizing the central tendency of the data, IQR outlier detection provides a measure of variability that is less susceptible to the influence of extreme values than some other statistical approaches.
Handling imbalance data
When dealing with imbalanced datasets, where classification categories are not evenly distributed, the performance of a model may be compromised. Resampling techniques, such as oversampling and undersampling, are frequently employed to overcome this challenge. In this research, three methods—SMOTE, NearMiss, and the SMOTETomek ensemble method—address imbalances in the data. 37
SMOTE acts as a data augmentation method, creating synthetic data samples for the minority class through interpolation among existing data samples. 34 ADASYN is a data balancing technique designed to generate synthetic examples for the minority class, particularly focusing on skewed class distributions. 35 NearMiss, on the other hand, as an undersampling technique, identifies samples from the majority class that are most similar to those from the minority class and retains only a subset of those samples. 36 The SMOTETomek approach combines under- and oversampling strategies. SMOTE is employed to oversample the minority class, while Tomek Links—a method for finding pairs of closely related samples from different classes—is used to delete samples from the majority classes. 37 This research aims to improve the classification model’s performance and accuracy by addressing the challenges posed by imbalanced datasets through various resampling strategies.
Feature selection techniques
This is the most significant phase in the study since it contributes to decreasing the dimensionality of the data, which improves model performance because only relevant data is utilized, and the model can more accurately represent the underlying patterns. To identify the optimal features, we devise a streamlined hybrid feature selection technique that integrates correlation-based feature selection (a filter method) with subsequent RFE (a wrapper method).39,40 Algorithm 1 represents the proposed hybrid feature selection method.
Hybrid feature selection hfs

 α
α Inclusion and exclusion criteria
We list the inclusion and exclusion criteria of this study below.
Inclusion criteria
Patients with cervical cancer-related medical records are available in the dataset. Complete records with sufficient feature availability (i.e., essential clinical, demographic, and diagnostic variables required for model training). Subjects with labeled outcomes (e.g. diagnosed with or without cervical cancer) for supervised learning. We have collected data from the responses through face-to-face meetings and online survey questionnaires with the respondent’s proper consent.
Exclusion criteria
Patients with missing or incomplete data for key variables such as age, medical history, or risk factors. We handle the missing values with proper methods. We have handled the imbalanced data and removed the inconsistent information from the dataset before analysis.
ML classifiers
We use several state-of-the-art ML algorithms from secondary data to predict the risk of cervical cancer. We employ various probabilistic, distance-based, and tree-based ML models in this study to make predictions and evaluate their performance. The algorithms were chosen based on meticulous considerations to comprehensively explore the full spectrum of ML techniques and identify the optimal approach for predicting the presence of cervical cancer. The details of the models are as follows:
Existing ML classifier
Support vector classifier (SVC) is a commonly employed ML method utilized for both regression and classification tasks.
41
To classify data points, it employs hyperplanes in
Generative AI approaches
Generative models are ML algorithms designed to generate new data samples that resemble a given training dataset. These algorithms generate synthetic data samples without losing the essence of the real data by learning the underlying distribution of numerical data. Besides, the generative teaching networks (GTNs) represent an innovative approach to enhancing the efficiency and effectiveness of training ML models. This is achieved by generating optimal training data and/or training environments. These DNNs excel at creating synthetic data specifically designed to expedite the learning process of a newly generated neural network. 52
Proposed stacking SXRL ensemble classifier
For better classification, we propose an ensemble classifier using a stacking procedure. Stacking is leveraging predictions from multiple models to construct a new model, which is subsequently directed to utilize these predictions on the test set. RF, XGB, and LR are in the level 0 estimator, and RF is the final estimator in this new proposed model. Stacking outperforms other ensembles by leveraging a meta-model to learn from multiple base model predictions.53–55 Unlike voting or blending, it captures complex relationships and dependencies among classifiers. By optimizing feature representation through diverse learners, stacking reduces bias and variance, improving generalization and predictive performance over traditional ensemble methods. We have designed different ensembles and show their result in the result section to demonstrate the purpose of choosing the stacking approach in this study. An overview block diagram of this ensemble classifier is in Figure 2.

The proposed stacking SRXL ensemble classifier.
The primary objective of an ensemble model is to diminish the variance in the data, thereby enhancing its suitability for ML models. Firstly, the LR operates. LR classifies the target as: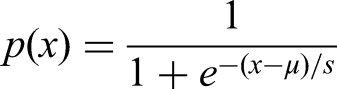

We all know that boosting is a sequential ensemble learning technique where each model in the series aims to rectify the errors of its predecessor. Subsequent models are intricately linked to the performance of the preceding model, creating a cumulative improvement in predictive accuracy throughout the boosting process. To get this advantage, we add RF in the stacking classifier to get a good result.
To reduce the computation, prevent overly complex tree creation, and contribute to better model generalization, we add XGB in the stacking process. The framework supports parallel processing, leveraging computational resources effectively for scalability. Then, RF is used as the final estimator for the classification. The pseudocode is in Algorithm 2.
Stacking SRXL built upon XGB, RF, and LR
Hyperparameter tuning using GridSearch
Hyperparameter tuning is a strategy used to determine the best combination of hyperparameters for an ML model. We utilized GridSearch 56 for this purpose, which returned the best configuration settings for our proposed SRXL model to predict the presence of cervical cancer accurately. GridSearch systematically searches through a predefined grid of hyperparameters to find the optimal values that yield the best performance for the model.
XAI techniques
XAI is designed as a solution to improve model transparency, changing AI from a mysterious black-box ML model into a more understandable one for the users. 57 The goal of XAI is to develop a variety of strategies that produce models with enhanced explainability while maintaining performance. 58 In this study, we use LIME, SHAP, ELI5 XAI tools, and DT surrogate model explainablity to make the model more understandable.
Shapley Additive Explanations (SHAP)
SHAP stands as the all-encompassing method for interpreting models, 59 serving both local and global explainability purposes. This approach, independent of specific models, aims to unravel the details of complex models such as ensemble methods and DNNs. Moreover, the SHAP framework employs SHAP values, a concept from coalitional game theory, to elucidate the individual contributions of each feature to the model output. 60 SHAP provides comprehensive and fair feature importance values, enhancing the interpretability and trustworthiness of ML models.
Local interpretable model-agnostic explanations (LIME)
The LIME framework is designed to explain a single instance. 61 Its functionality provides a localized explanation of the classification by identifying the smallest features that significantly influence the likelihood of a specific class outcome for a given observation. In this study, we assess the efficacy of LIME explanations. LIME provides model-agnostic interpretability for ML predictions, enhancing transparency and trust by generating human-understandable explanations.
ELI5
ELI5, a Python module, aids in the debugging of ML classifiers and offers straightforward explanations for their predictions. 62 It is designed for non-experts and uses simple language, making it a handy tool for a wide range of applications. ELI5 offers simplified, intuitive explanations for ML models, promoting transparency and interpretability in complex decision-making processes.
DT surrogate model
Another popular method to explain the overall behavior of a “black box” model involves using a global surrogate model. 63 The aim of training a global surrogate model is to approximate the predictions of a black-box model. We can make conclusions about the black-box model by analyzing the surrogate model. This research uses DT as the surrogate model to make the tree-based visual representation. These models provide transparent and interpretable insights into complex ML models, aiding in the understanding and trustworthiness of predictions.
Performance measurement metrics
ML models’ accuracy and efficacy are assessed using performance-measurement methods. These methods offer measurements and metrics that evaluate a model’s performance and can be used to inform model selection, model improvement, and parameter tuning. The below equations display commonly used techniques in this study as performance measures of the classifiers.
Receiver operating characteristics (ROC)
The area under the rate plot of the true positive versus false positive.
Area under the curve (AUC)
The ability of the classifier to discriminate between positive and negative classifications.
In the equations, true positive, true negative, false positive, false negative, positive rate, precision (P), and recall (R) are used as TP, TN, FP, FN, PR, P, and R, respectively. These performance metrics provide insightful information about the operation of ML models, assisting in assessment and advancement. The individual task, dataset, and goals of the ML project determine the appropriate technique.
Domain knowledge integrated explainability
In our research, we also conducted another experiment that correlates the domain expert’s opinion with the XAI tool’s output. To assess and compare the explainability of XAI and the expert’s viewpoint, we engaged in an extensive process, illustrated in Figure 3 as a block diagram.

An overview of domain knowledge-driven explainability mapping and comparison with XAI tools explainability.
Feature importance
This experiment established a significant alignment between the domain expert’s opinion and the explanations provided by the XAI tool. We assigned varying weight values to distinguish between features based on their significance in the medical field. We met with several medical experts to discuss the dataset’s features and gather their insights. The weight for individual features was determined according to the recommendations of these domain experts. Subsequently, we developed an online questionnaire to collect. This section is subdivided into several subsections to convey a comprehensive grasp of the study’s contributions on a five-degree Likert scale. Furthermore, we granted experts the flexibility to express their opinions independently. After the data collection procedure, we computed the importance of features using our proposed explainable method, outlined in Algorithm 3.
Results
This section is subdivided into several subsections to convey a comprehensive grasp of the study’s contributions. Initially, we present the dataset’s EDA to comprehend its inherent nature. Subsequently, we showcase the classifier’s performance across various stages and objectives. The results of XAI tools are presented to enhance interpretability. Lastly, we align the domain experts’ opinions with the outcomes of XAI tools, establishing a connection between expert insights and explainability measures. This structured approach provides a holistic overview of the study’s findings and their significance in different dimensions.
EDA to understand the nature of the dataset
One of the primary concerns encountered when dealing with this dataset was effectively managing the imbalanced distribution of data samples across different cases for our target class “biopsy.” Figure 4 illustrates the clear imbalance within the dataset. A mere 6.4% of the total data records indicate the presence of cancer-positive classes, highlighting the need for further investigation and attention to this critical issue.

Percentage of biopsy of individual class.
This study has effectively addressed this problem by implementing well-established balancing techniques, including SMOTE, ADASYN, NearMiss, and SMOTETomek. After applying the data balancing techniques, a significant improvement in the data distribution for each class can be observed in Table 2. This ensures a more balanced representation of the classes in our dataset.
Distribution of individual classes before and after applying the data balancing techniques.

ADASYN: adaptive synthetic; SMOTE: synthetic minority oversampling technique.
The following figures provide a comprehensive overview of the dataset’s behavior. Figure 5 clearly illustrates that the majority of patients belong to the age group between 20 and 40. It demonstrates that a significant portion of the patients underwent pregnancy between one and three times. Moreover, the majority of individuals engaged in their initial sexual experience between the ages of 15 and 20, and had been exposed to zero to five sexual partners. Therefore, it is evident from the plots that those who had their first sexual intercourse between 15 and 18 years of their life and experienced sexual interaction with multiple partners are at a higher risk of testing positive on the biopsy test.

Multivariate analysis on age and sexual habits versus biopsy.
Figures 6 and 7 establish the correlation between a patient’s smoking habits, sexual behaviors, and the target variable. The graphical visualization highlights that approximately 88% of the patients (700 samples) have a non-smoking background. This information primarily suggests that smoking may not be strongly correlated with the target variable, as the majority of patients do not have a smoking background. One important point to be noticed here is that individuals who smoke and have early age first sexual intercourse are at a higher risk of testing positive in a biopsy. Moreover, the average age of non-smoking cancer-positive patients is less than the average age of cancer-positive patients with a prior smoking history. This indicates that older women with a prolonged smoking history are more prone to be tested cancer-positive compared to young women who do not smoke.

Multivariate analysis on smoking and sexual habits versus biopsy.

Multivariate analysis on age and smoking habits versus biopsy.
Algorithms hyperparameters setting
In this study, we utilized a secondary dataset for binary classification purposes. Following the preprocessing steps, we employed eight ML models and one ensemble ML model for classification. Here, we presented the associated hyperparameters of the ML classifiers in Table 3. The values of the hyperparameters change for different data distributions and data properties.
Hyperparameter values of the ML classifiers in both without preprocessed and with preprocessed data.

ML: machine learning; SVC: support vector classifier; DT: decision tree; RF: random forest; GBC: gradient boosting classifier; LR: logistic regression; KNN: K-nearest neighbor; CB: CatBoost; XGB: extreme gradient boosting.
Results of different classifiers
We examined the behavior of the data and made predictions for cervical cancer by applying nine (9) classifiers on the risk factors dataset. Table 4 demonstrates the performance comparison between nine algorithms and different oversampling and undersampling techniques studied in this experiment. The presence of biases in the model is evident. While the overall accuracy may reach 94% to 96%, it is concerning that the performance for the minority class is significantly poorer and shows a lack of consistency without applying any preprocessing techniques. Moreover, the minority class exhibits significantly lower values in terms of precision, recall, and F1 score compared to the majority class. These imbalances highlight the urgent need to address the bias problem to obtain more accurate predictions for cervical cancer. To handle the imbalanced dataset, we applied the SMOTE balancing technique. SMOTE is a highly effective technique for oversampling that creates synthetic samples in the minority class by interpolating between neighboring examples. After applying SMOTE, we achieved a more balanced dataset, which improved the performance of different ML and deep learning models. The subsequent findings suggest the dominance of our proposed ensemble model over other classifiers in terms of every performance standard. ADASYN is an oversampling technique that balances the dataset by increasing the sample count for the minority class. The results demonstrate that by implementing ADASYN along with the hybrid feature selection method, we were able to enhance the overall performance of the models significantly. This improvement is especially noteworthy compared to their previous performance on the initial imbalanced dataset. However, it is noticeable that the ML classifiers could not surpass their performance with SMOTE. SVC showed the least accuracy among them, achieving only 62%, while the proposed model is proven to be the most capable one with 97% accuracy.
Performance comparison of accuracy and F1-score across algorithms and preprocessing techniques.

Acc.: accuracy; SMOTE: synthetic minority oversampling technique; ADASYN: adaptive synthetic; SVC: support vector classifier; DT: decision tree; RF: random forest; GBC: gradient boosting classifier; LR: logistic regression; KNN: K-nearest neighbor; CB: CatBoost; XGB: extreme gradient boosting.
After applying an undersampling technique, NearMiss, the results are reported as an improvement of the overall model prediction compared to the initial findings. However, the performance considerably deteriorated for most of the classifiers this time. Once more, the top-performing model is the proposed ensemble model, achieving a 95% accuracy, while the poorest performer is XGB, with an accuracy of 82%. On the other hand, SMOTETomek significantly enhanced the performance metrics for all classifiers, effectively addressing bias for both majority and minority classes. SMOTETomek is a hybrid sampling technique combining both up and downsampling. Despite achieving impressive results, SMOTETomek still fell short of outperforming SMOTE. From the above discussion, we can conclude that oversampling techniques can be extremely useful when dealing with imbalanced data.
Confusion matrix of the proposed method in different state
The confusion matrix depicted in Figure 8 denotes the model performance at different stages using different oversampling and undersampling techniques. It is visible that the model performance has been significantly improved and is stable when the hybrid feature selection method was applied combined with the oversampling techniques. The proposed model’s performance improved significantly, utilizing the SMOTE oversampling technique to handle the imbalanced dataset.

Confusion matrices of different stages (a) normal setup, (b) feature selection with SMOTE, (c) feature selection with ADASYN, (d) feature selection with NearMiss, and (e) feature selection with SMOTETomek. SMOTE: synthetic minority oversampling technique; ADASYN: adaptive synthetic.
Figure 9 of the AUC–ROC curves further establishes the superiority of our proposed stacking ensemble model. The ensemble model outperformed the traditional ML and deep learning models in accurately classifying cervical cancer, demonstrating remarkable performance with an AUC of 0.995 with SMOTE. The graph clearly shows that the ROC curve becomes unstable when using ADASYN, NearMiss, and SMOTETomek balancing techniques with other ML and deep learning classifiers. In contrast, stability is achieved in Figure 9(b) when using SMOTE. This indicates the superior classification performance of the proposed model, along with the robustness and consistency of the proposed classification pipeline.

ROC curve of different stages (a) normal setup, (b) feature selection with SMOTE, (c) feature selection with ADASYN, (d) feature selection with NearMiss, and (e) feature selection with SMOTETomek. ROC: receiver operating characteristics; SMOTE: synthetic minority oversampling technique; ADASYN: adaptive synthetic.
Cross validation and different ensemble approach’s result
To verify the robustness and generalizability of our proposed ensemble model, we conducted a 10-fold cross-validation. The results are demonstrated in Table 5. This iterative process helps smooth out variations in model performance, providing a more stable and reliable assessment while minimizing the potential scope of overfitting. The results indicate a consistency in stable performance across all the ML algorithms used in this study. However, the proposed SRXL model consistently outperforms them, achieving higher predictive accuracy which demonstrates its effectiveness in handling complex unseen patterns within the dataset. This superior performance highlights its potential for real-world applications where reliability and robustness are crucial.
Result of the 10-fold cross validation of the models.

SVC: support vector classifier; DT: decision tree; RF: random forest; GBC: gradient boosting classifier; LR: logistic regression; KNN: K-nearest neighbor; CB: CatBoost; XGB: extreme gradient boosting.
We present a comparative analysis of different ensemble techniques, evaluating their performance based on accuracy, precision, recall, and F1-score in Table 6. The ensemble models compared include voting ensemble, blending ensemble, stacking with basic ML models, and the proposed SRXL model.
Results of different ensemble techniques.

LR: logistic regression; DT: decision tree; KNN: K-nearest neighbor; SVC: support vector classifier; RF: random forest; XGB: extreme gradient boosting; ML: machine learning.
The voting ensemble, which combines LR, DT, KNN, and SVC, achieves an accuracy of 0.95. It maintains balanced performance across precision, recall, and F1-score, each reaching 0.94. Although this technique leverages multiple models, its performance is limited by the averaging nature of voting, which may not optimally capture complex patterns in the data. The blending ensemble, incorporating LR, DT, and SVC, slightly improves performance over voting, reaching 0.96 accuracy and 0.95 across other metrics. This improvement suggests that weighted blending of models is more effective than simple voting, potentially due to better capturing the strengths of individual classifiers. However, it still lags behind the more advanced ensemble techniques. The stacking ensemble, which utilizes LR, DT, KNN, and SVC, significantly enhances performance, achieving 0.97 accuracy along with precision, recall, and an F1-score of 0.96. Stacking generally outperforms voting and blending because it leverages a meta-model that learns from the predictions of base models, improving decision boundaries and reducing biases inherent in individual classifiers. The proposed SRXL model, which integrates RF, XGB, and LR, exhibits the highest performance, achieving an accuracy of 0.98. It also outperforms other methods in precision (0.98), recall (0.97), and F1-score (0.98). This suggests that SRXL benefits from the powerful feature selection and ensemble learning capabilities of RF and XGB while maintaining the interpretability of LR. The superior results indicate that this combination is more effective in capturing complex data relationships and minimizing errors compared to traditional ensemble techniques.
The results highlight that while all ensemble models improve classification performance, SRXL is the most effective due to its advanced ensemble learning approach, leveraging the strengths of RF, XGB, and LR. This makes it a promising technique for applications requiring high accuracy and robustness.
Result of different generative AI approaches
Table 7 presents the results obtained by applying variational autoencoder (VAE) to generate artificial data and then utilizing RF as the ultimate classifier. On the other hand, Table 8 depicts the GTNs’ performance. These models are evaluated across different data balancing techniques and batch sizes.
Performance of VAEs-enabled RF.

VAE: variational autoencoder; RF: random forest; Acc: accuracy; P: precision; R: recall; SMOTE: synthetic minority oversampling technique; ADASYN: adaptive synthetic.
Performance of GTNs.

GTN: generative teaching network; Acc: accuracy; P: precision; R: recall; SMOTE: synthetic minority oversampling technique; ADASYN: adaptive synthetic.
The tables present the performance of the VAEs-enabled RF and GTNs model, respectively, using batch sizes of 32 and 64, 500 epochs, and stochastic gradient descent optimizer across different data balancing techniques. The first state indicates the model performance on the original imbalanced dataset, showing high accuracy but poor precision, recall, and F1 scores, particularly for the minority class. Using SMOTE and SMOTETomek, the model shows improved precision, recall, and F1 scores, indicating better handling of the imbalanced data. ADASYN also improves these metrics, resulting in lower accuracy, reinforcing that aggressive undersampling might be detrimental due to significant information loss. Comparing the two batch sizes, a batch size of 64 generally provides slightly better results than a batch size of 32 across most metrics and techniques.
Although VAEs and GTNs excel at capturing the intricate probability distribution of data, they may not be ideal for achieving precise classification on tabular data. Generative models lack the discriminative capability to differentiate between classes based on input features. Moreover, they encounter challenges in handling categorical data, a common occurrence in tabular datasets. In addition, VAEs and GTNs frequently entail intricate training processes and are susceptible to mode and posterior collapses. This significantly reduces their effectiveness in classification tasks. Conversely, discriminative ML models such as LR, DT, RF, gradient-boosting machine (GBM), and SVM are generally more suitable for classification tasks because they handle nonlinear relationships and interactions between features. These models can effectively capture the structure of tabular data, better handle categorical features, and make more accurate and reliable predictions for tabular data classification problems.
Explainability results
Model explainability in ML ensures transparency by revealing how models make predictions. Techniques such as SHAP, LIME, and ELI5 provide insights into the importance of features, helping users understand complex algorithms. XAI is vital for trust and ethical deployment in critical areas such as healthcare and finance, allowing stakeholders to validate decisions, identify biases, and enhance model performance. The results of the model’s explainability using different tools are given below.
Global explainability
Explainability adds the essence of transparency to the models’ prediction. Figure 10 ranks the top 10 features contributing most to the overall prediction of the classification model. The results indicate that the feature “Hormonal Contraceptives (years)” has the highest importance, followed by “First Sexual Intercourse” and “Age.” These features provide valuable insights into the decision-making process of the model. The mean absolute contribution reveals that hormonal contraceptives have the most significant impact on the model’s predictions.

Feature importance using Shapley additive explanations (SHAP).
In Table 9, we can see a comprehensive breakdown of each feature and their corresponding weights, listed in descending order of importance. The number of years spent consuming hormonal contraceptives is given the highest priority, while the number of smoking years is given the lowest priority. The numerical value shown in the table is the result of combining the individual feature weight with its corresponding tolerance. For instance, the individual feature weight for age is 0.0240, meaning that even the smallest alteration in the age value could impact the model prediction by 0.0064. Furthermore, in Figure 10, we can observe that most features correspond to the table representation. This confirms the validity of our findings.
Individual feature’s weight and tolerance to the classifiers.

STD: sexually transmitted disease; IUD: intrauterine device; Dx:HPV: presence of human papilloma virus after the diagnosis; Dx:Cancer: presence of cancer after the diagnose; Dx:CIN: presence of cervical intraepithelial neoplasia after the diagnosis.
Local explainability
Impact of individual features
This section explains the effect of the individual feature’s impact on the final prediction of the classification model. Figure 11(a) and (b) shows that the longer a woman uses hormonal contraceptives, the higher her probability of being diagnosed with cervical cancer. The subsequent two figures unveil the significant impact of a woman’s sexual habits on the classifiers’ predictions. Figure 11(c) illustrates the impact of early sexual exposure on the classifier’s prediction, while Figure 11(d) depicts the influence of sexual preferences in terms of the count of sexual partners. These insights shed light on the significance of the predictive model. Based on these findings, it can be concluded that women who engage in early sexual intercourse and have multiple sexual partners are at a significantly higher risk of being diagnosed with cervical cancer. This further emphasizes the importance of comprehensive sex education and access to reproductive health services for young women.

Individual features explainability.
Figure 11(e) to (j) portrays the significant factors that contribute to the patient’s condition, including age, the number of STDs detected, the number of pregnancies, and the presence of HPV. The data indicates that women diagnosed with STDs and other conditions such as cancer, CIN, or HPV are at a higher risk of developing cancer. Therefore, healthcare professionals must take into account these factors when evaluating an individual’s cancer risk. Furthermore, we can observe the impact of the woman’s age on the prediction accuracy, with younger women tending to have a lower likelihood of the predicted outcome. More precisely, older women with similar conditions are more susceptible to risk compared to younger women.
Explainability on individual instances
Figure 12 shows the impact of the features on individual patient records. It is evident from the figure that when our extracted top features from Figure 10 contribute inversely to the patient’s condition, it is less likely to be diagnosed with cancer. On the contrary, when the extracted top features contribute mostly to the outcome, the patient is at high risk of cervical cancer (see Figure 13(a) and (b)).

Individual instance explainability.

Prediction probability of an individual instant and features impact on it using local interpretable model-agnostic explanations (LIME).
Figure 14 displays a comprehensive comparison of the significance of various features and their respective contributions to the prediction of the outcome. We have selected 10 random data samples from the dataset to analyze the contribution of different features to the model’s predictions. As shown in the compare plot, features such as “Hormonal Contraceptives (years),” “Number of pregnancies,” and “Number of sexual partners” exhibit greater variation in their contributions (more scattered lines) compared to others. This indicates a higher standard deviation for these features, suggesting they have a more significant and variable impact on the model’s final predictions compared to features with smaller deviations. As the top features contribute more, the models’ predictions also improve. This highlights the significance of selecting and incorporating the most influential features in our predictive models. It further establishes the superiority of these top features to achieve more accurate and reliable predictions.

Comparison of 10 random instants feature impact.
DT surrogate model explainability
A surrogate model is the graphical representation of the predictions made by the classification model at each step. It explains the complex decision-making task by splitting the overall process based on several features and their respective values. In Figures 15 and 16, two surrogate models have been shown at different depth levels. In these figures, the internal or parent nodes represent the features that serve as the conditions for splitting, while the terminal nodes represent the ultimate prediction results based on the specified criteria for splitting. This approach allows for a more transparent understanding of the decision-making process and provides insights into how the model arrives at its predictions. Visualizing the surrogate models at different depth levels makes it easier to comprehend the impact of various features on the final prediction. In these figures, the DT surrogate model uses different features obtained from the patient’s medical records such as “Hormonal Contraceptives (years),” “STDs,” “Num of pregnancy,” etc. to determine the probability of cervical cancer. If the conditions for splitting exceed a certain threshold, the model accurately predicts a positive cancer diagnosis for the patient. Conversely, if the conditions fall below the threshold, the patient is not at a high risk for cancer. Furthermore, the DT surrogate model considers various factors such as age, smoking habits, and sexual activity duration to obtain a more accurate prediction of cervical cancer risk. By analyzing these features, the model aims to assist in determining the top contributing features and better prediction of the disease.

Decision tree (DT) surrogate model explainability in depth 3.

Decision tree (DT) surrogate model explainability in depth 5.
Result of domain knowledge integrated explainability and XAI tools mapping
In this study, we compared the insights provided by domain experts with the outcomes revealed by utilizing integrated XAI tools. This approach allowed us to identify areas of agreement and potential discrepancies between the model and human experts. Figure 17(a) depicts the weighted average calculated for individual features. The proposed feature selection method categorizes the top features into three weighted categories, W1, W2, and W3, and assigns labels to the features based on their contribution to the final predicted outcome. The two main factors that have the greatest impact on the likelihood of developing cervical cancer are HPV infection and having multiple sexual partners. These factors are given the highest level of importance, indicated by a weighting of W3. On the other hand, age, hormonal contraceptives, and smoking are assigned the least weighting of W1, indicating a lesser impact on cancer risk. The domain experts’ response exhibits an indexing pattern similar to the previous figure. It is illustrated in Figure 17(b). Experts have confirmed that the main factors contributing to the risk of developing cervical cancer in the future are engaging in sexual activity with multiple partners and contracting the HPV. Furthermore, they identified early sexual activity, a long history of hormonal contraceptive use, and the presence of other STDs as major risk factors for the development of cervical cancer.

Importance of individual features from the domain experts.
Figure 18 visualizes the primary factors leading to cervical cancer as identified by domain experts. These reasons include HPV infection, smoking, hormonal contraceptives, multiple sexual partners, and poor hygiene practices. Further analysis of the data reveals that these factors often interact with one another, exacerbating the risk of cervical cancer. A clear dominance of HPV infection and engagement with multiple sexual partners can be observed with 90% and 55% scores, respectively. This further confirms that our proposed model, integrated with XAI, accurately detected the indicators of cervical cancer. The majority of experts agree that the prolonged use of hormonal contraceptives for over 10 years, particularly during a woman’s reproductive years, significantly increases the risk of developing cervical cancer (see Figure 19).

Major risk factors for cervical cancer listed by domain experts.

Visualizing the insights provided by domain experts: (a) How many years of having oral contraceptive pills can lead to cervical cancer? (b) What age range do you consider women more susceptible to contracting cervical cancer?.
The model’s predicted feature importance differs and may not always align perfectly with the risk factors identified by the experts. This is due to various factors such as data quality, sample size, and modeling assumptions. Figures 17 and 18 clearly illustrate that although experts assert oral hormonal contraceptives as a major contributor to cervical cancer, our proposed method assigned it the least weight, W1. Additionally, experts emphasized the significance of early sexual intercourse, a crucial aspect that was not addressed in the proposed model. This indicates that even with the impressive capabilities of advanced AI and explainability tools in uncovering hidden patterns in patient data and identifying key features that influence model outcomes, there is still room for improvement to match the expertise of human domain experts. Further research and refinement are essential to ensure these AI models reach their full potential in the medical field. However, this comparison provided detailed insights into the decision-making processes of both the model and the experts, effectively bridging the gap.
Discussion
Medical diagnosis data is used to create highly accurate advanced machine-learning models that can make precise predictions. These models serve as valuable tools for healthcare professionals, empowering them to make more accurate and informed diagnoses for their patients. However, the primary hurdles lie in the limited access to real-world datasets and their imbalanced nature. It negatively affects the ML model’s overall prediction, leading to a bias toward one class and subpar performance when classifying the minority class. The proposed study introduces a two-level pipeline that combines a hybrid feature selection method with an ensemble model and domain knowledge. This approach is designed to address the complexities of this challenging task effectively. By incorporating a hybrid feature selection method and stacking ensemble model, the proposed methodology aims to address and mitigate the issue of biased predictions and improve the model’s performance in classifying both the majority and the minority class. This comprehensive approach ensures that the model not only guarantees accuracy for individual classes but also exhibits the ability to recognize both positive and negative outcomes. Table 10 presents the overall comparison of our proposed pipeline with other recent research.
Comparison with recent works.

RF: random forest; DNN: deep neural network; PCA: principal component analysis; XGB: extreme gradient boosting.
We experimented with various oversampling and undersampling techniques such as SMOTE, SMOTETomek, ADASYN, and NearMiss to assess their effects and compare the predictive results with the original imbalanced dataset. By applying these techniques, this study observed how each method affected the model’s performance, allowing the selection of the most appropriate approach for the enhanced performance and stability of the ML models. In this case, it has been shown that oversampling techniques outperformed undersampling techniques, with SMOTE being the most effective. Along with our proposed SRXL model, other ML models performed better, such as DT, LR, CB, etc. This emphasizes the importance of preprocessing, as proposed in the study, which can significantly enhance the performance of ML models. Moreover, this study conducted a thorough analysis of the data, harnessing the potential of ML to uncover concealed patterns within the dataset. The findings revealed novel insights and correlations that were previously unrecognized. Additionally, the results obtained from the analysis of different generative AI approaches indicate their incapability in handling tabular datasets. The proposed hybrid feature selection method effectively ranked the most important features contributing to the model’s predictions. The features were subsequently utilized to develop a predictive model, showcasing remarkable accuracy in forecasting the target outcome. Furthermore, the study conducted an in-depth analysis of the importance of features that further facilitate the early prediction of cervical cancer and ensure timely treatment.
Furthermore, tools for explainability, such as SHAP, ELI5, and LIME, have increased the transparency and reliability of the pipeline. This incorporated advanced automated AI algorithms in the professional health domain. SHAP and LIME are powerful tools for providing global and local explanations. We integrated the expert opinion of the domain and healthcare professionals to map the findings. We facilitate one-to-one interviews to assign weights to individual features and rank their contribution. By conducting personalized interviews, this study evaluates the importance of different factors and establishes their impact on the final ranking. Therefore, healthcare professionals can better understand the decision-making process. This potentially increases the acceptance and adoption of the developed predictive model in clinical practice.
Limitations
This study is based on a single publicly available dataset. Additionally, we collected expert opinions from domain experts in a single country. Ideally, gathering insights from domain experts across different regions would enhance the study’s robustness, but due to resource constraints, this was not feasible. Incorporating more diverse perspectives from experts and collecting additional data would further improve the study’s explainability and practical applicability.
Conclusion and future work
In conclusion, our study addresses the intricate challenges of real-world data analysis, particularly focusing on the “Cervical Cancer (Risk Factors)” dataset. The prevalence of imbalanced class distributions, noise, missing values, and duplicate records in healthcare datasets emphasizes the need for a meticulous preprocessing pipeline. Our proposed stacking ensemble model has exhibited exceptional performance, achieving a remarkable 98% accuracy and an outstanding AUC score of 0.995, surpassing traditional ML and deep learning models.
Applying SHAP, LIME, ELI5, and DT surrogate models enhances our model’s interpretability. We have successfully ranked influential features such as hormonal contraceptives, women’s age, sexual partners, sexually transmitted disease (STD) infections, and other habits, providing valuable insights into cervical cancer predictions. Validation through expert interviews reinforces the robustness of our model.
Further work will focus on integrating more datasets in this domain in a distributed manner where datasets are not gathered centrally to enhance security. More relevant features will be added to analyze cervical cancer more deeply. Additionally, we will explore ways to mitigate the mismatch in domain experts’ opinions on the explainability of the XAI tools.