
Abstract
Keywords
Introduction
The integration of artificial intelligence (AI) systems across various domains significantly enhances their efficacy in diverse tasks. These AI systems primarily rely on complex machine learning (ML) models, achieving outstanding performance in tasks such as prediction, recommendation, and decision-making support.1–5 However, these models, characterized as “black-box models,” maintain opacity in their internal processes, prevalent in current AI systems leveraging deep learning models and ensemble methods like bagging and boosting. 6 While these models boast exceptional performance, their lack of transparency poses inherent risks, including potential biases derived from training on unfair data. 7 Such lack of transparency can lead to decisions lacking complete interpretability and may potentially contravene ethical principles. The integration of ML models into AI products and applications, as witnessed in the current business landscape, heightens the risks associated with compromising safety and trust, particularly in high-stakes decision-making domains like medicine, finance, and automation. 8 The enactment of the General Data Protection Regulation (GDPR) by the European Parliament in May 2018 introduced provisions regarding automated decision-making, emphasizing the right to explanation. 9 These regulations aimed at enabling individuals to acquire ‘‘meaningful explanations of the underlying logic” behind automated decisions. While legal experts differ in their interpretations of these provisions, there is a consensus regarding the pressing need to implement such principles, representing a notable contemporary scientific challenge.
In response to the practical and ethical challenges posed by the opacity of black-box models in AI, the field of eXplainable (XAI) has witnessed a surge in the development of explanation methods from both academia and industry. 10 XAI seeks to address these concerns by making the internal logic of AI models more interpretable and accessible, which is critical for fostering trust, transparency, and accountability—especially in high-stakes domains such as healthcare, finance, and law. As AI becomes increasingly integrated into decision-making pipelines, ensuring that stakeholders can understand and verify algorithmic outputs is both a technical and ethical imperative. 9 Importantly, these efforts must consider the diverse nature of data encountered, including structured data such as electronic health records and unstructured data like medical images 1 and clinical notes, each of which presents unique challenges for explainability.11,12 Furthermore, there have been significant advances in XAI approaches specifically tailored for healthcare applications, such as interpretability techniques for medical imaging, natural language explanations for clinical notes, and causal inference models for patient outcomes,13–15 all of which enrich the current XAI landscape and should be considered to provide a holistic overview.
However, the landscape of XAI methods is highly heterogeneous and fragmented, posing significant challenges for both researchers and practitioners. 16 Explanation techniques differ not only in their algorithmic formulation but also in the type and granularity of interpretability they provide, where interpretability refers to the extent to which a human can understand or predict a model’s behavior. For instance, feature attribution methods such as SHAP 17 and integrated gradients 18 quantify the contribution of individual input features to a specific model prediction. These methods offer fine-grained, localized insights suitable for instance-level analysis. By contrast, rule-based approaches like RuleFit 19 and anchors 20 derive human-readable if-then rules or logic programs that approximate the decision boundaries of a model, making them more amenable to global or structural interpretation. In an effort to bridge the gap between interpretability and predictive accuracy, recent research has explored knowledge transfer approaches that leverage complex black-box models to inform inherently interpretable white-box algorithms, aiming to combine the strengths of both. 21
Moreover, explanation techniques vary in scope and assumptions: local methods provide explanations for individual predictions—typically by approximating the model’s decision boundary in a small neighborhood of the input—while global methods aim to summarize the overall decision logic of the model across the entire dataset. 22 Some methods are inherently model-agnostic—meaning they can be applied to any black-box model without needing access to internal parameters—while others are model-specific, requiring access to internal gradients or structures (e.g. weights or layers). This diversity complicates the development of a unified evaluation framework: metrics such as fidelity and identity are often applied to local methods, whereas distributional similarity or rule complexity might be more relevant for global or rule-based approaches. Yet, these metrics are not universally applicable, and their interpretation often depends on the nature of the explanation task being evaluated. Reproducibility and stability—critical in high-risk domains—are also inconsistently assessed across methods, particularly those involving random sampling or local approximation.
To address the complexity and fragmentation in evaluating XAI methods, we propose a unified evaluation framework that systematically compares both local and global explanation techniques across multiple interpretability paradigms. Our work builds on previous studies—including our own earlier benchmark focused on local model-agnostic methods in healthcare 23 —by significantly expanding the scope to include rule-based and global explanation methods, and by aligning evaluation metrics more precisely with explanation tasks. In contrast to prior work that often focuses narrowly on a single method type or metric, this framework evaluates explanation quality using a suite of clearly defined and task-relevant metrics. 24 We conduct experiments on real-world healthcare datasets, a domain where explanation reliability and usability are especially critical. The selected methods represent a balanced spectrum of explanation paradigms—including feature attribution techniques and rule-based models—and we explicitly define the XAI task setting (e.g. local vs. global) for each method. Our goal is twofold: (1) to offer evidence-based guidance for practitioners seeking interpretable solutions in safety-critical applications; and (2) to contribute to the broader discourse on how explanation quality can be rigorously, fairly, and transparently evaluated across heterogeneous XAI techniques.
Related work
The domain of explainable AI methods has arisen more recently within academic circles in comparison to the broader expanse of AI literature. This emergence has been prompted by the widespread integration of AI models across diverse sectors in contemporary society, signifying its growing importance.1,23,25,26 XAI tools are differentially categorized into local or global methods, each designed to elucidate the decision-making processes of AI models across varying levels. The local methods specifically target the comprehension of an AI algorithm’s behavior at a more granular, low-level hierarchical tier.1,27–29 The global set of XAI approaches, in contrast, are directed towards comprehending the behavior of AI algorithms at a higher hierarchical level. 30 These methodologies assist users in gauging how features contribute to predictions across entire datasets or collections of datasets. Another way to categorize explanation techniques is based on whether the technique adopted to explain can work only on a specific black-box model (model-specific) or can be adopted on any black-box (model agnostic). Model-agnostic techniques are applicable to any model, offering valuable insights into the factors influencing their decisions. These tools operate post-hoc, meaning they are applied after the model has been trained. Importantly, they do not require access to the model’s internal details; rather, they only necessitate the capability to test the model predictions. 11
Another branch of literature focuses on the quantitative and qualitative evaluation of explanation methods assessing the quality and utility of returned explanations, considering aspects like their effectiveness and relevance.6,16,23,31–33 Quantitative evaluation primarily focuses on metrics measuring aspects like fidelity, 34 stability. 35 These metrics assess the ability of explainers to mimic the behavior of the underlying model, and the consistency of their output. Despite the availability of these quantitative metrics, there is no wide agreement about a specific set of metrics to determine the ‘‘best” explainer. This highlights the complexity and subjectivity inherent in the evaluation process. Wilson et al. 36 propose three proxy metrics aimed at evaluating the quality of explanations within these frameworks. These metrics, namely completeness, correctness, and compactness, play a pivotal role in gauging the effectiveness and reliability of explanations. Completeness pertains to the audience’s ability to verify the validity of the explanation, specifically the extent to which it covers instances. Correctness focuses on the accuracy of the explanation. Compactness delves into the degree of succinctness an explanation can achieve, such as the number of conditions within a decision rule that elucidates a specific instance. Qualitative assessment focuses on evaluating the usability of explanations from the end-user’s perspective, encompassing aspects such as providing meaningful insights, ensuring safety, social acceptance, and fostering trust. Doshi et al.37–39 propose qualitative evaluation criteria that categorize into three groups: functionally grounded metrics, application-grounded evaluation methods, and human-grounded metrics. Functionally grounded metrics leverage formal definitions to evaluate explainability, eliminating the need for human validation. Application-grounded evaluation methods involve human experts to validate specific tasks, typically in domain-specific settings. In contrast, human-grounded metrics evaluate explanations through non-expert human users, aiming to measure the overall understandability of explanations in simplified tasks.
Methods
This section outlines the methodology used to benchmark explainability techniques. It introduces the explanation frameworks considered in this study and describes the metrics employed to evaluate their performance. These methods were selected based on their relevance, popularity, and compatibility with both local and global interpretability goals.
Evaluated explainability frameworks
Local interpretable model-agnostic explanations (LIME)
The LIME
28
is a local model-agnostic explainer that produces feature importance vectors by generating explanations around an instance being explained
Contextual importance and utility (CIU)
CIU is a local, post-hoc, model-agnostic explainer grounded in the concept that the significance of a feature can vary across different contexts. 40 CIU employs two algorithms for elucidating predictions rendered by black-box methods.41,42 Originating from established decision-making theory, this method posits that the importance of a feature and the efficacy of its values dynamically evolve contingent upon other feature values. 42 Contextual importance (CI) serves to approximate the aggregate importance of a feature within the prevailing context, while contextual utility (CU) offers an estimation of the favorability, or lack thereof, of the current feature value concerning a designated output class.
Anchor
Anchor is a model-agnostic method providing rule-based explanations called
RuleFit
RuleFit is a global explainability framework designed for constructing rule ensembles.
19
The process involves two main phases: rule extraction and weight optimization. In the extraction phase, RuleFit trains a tree ensemble model on a sample
RuleMatrix
RuleMatrix is a model-agnostic explanation technique designed to offer both local and global explanations with a focus on visualizing extracted rules.
43
The technique comprises four main steps. Initially, the distribution of the provided training data
Table 1 presents a comprehensive summary of the explanation methods considered in our study, including framework name, publication year, citations per year, along with their capabilities in handling various data types distinguishing between tabular (TAB) and any data (ANY). Furthermore, Table 1 classifies these explanation methods into two distinct categories: Global explanations (G) and Local explanations (L).
Key characteristics of explanation methods used in this study.

LIME: local interpretable model-agnostic explanations; CIU: contextual importance and utility; TAB: tabular; ANY: any data; G: global explanations; L: local explanations.
Evaluation metrics for explainability methods
This section provides a comprehensive overview of established quantitative evaluation metrics utilized in the subsequent benchmarking process.

where
The three following metrics—entropy ratio, Kullback-Leibler divergence, and Gini coefficient—are used to assess the explainability of a model based on the distribution of feature importance.
48
They allow for a comparison between the actual feature importance distribution and a uniform benchmark distribution. Let us consider a set of feature importance denoted as
Experimenatal setup
Summary of datasets used in this study. Dataset references are provided in the bibliography.

Results
This section presents the quantitative outcomes of our benchmarking study on local and global explanation methods using a range of evaluation metrics. Results are reported objectively without interpretation.
Local interpretability results
Table 3 summarizes the performance of LIME, CIU, RuleFit, RuleMatrix, and Anchor across several datasets on eight local interpretability metrics:
Metric scores for different local explanation techniques on tabular data.

LIME: local interpretable model-agnostic explanations; CIU: contextual importance and utility.
Global interpretability
In this section, we present a comprehensive examination of various global explanation methods evaluated across a diverse array of datasets, as highlighted in Table 4.
Discussion
The benchmarking results reveal distinct trade-offs among the evaluated interpretability methods. RuleFit and RuleMatrix demonstrated strong performance in reproducibility, fidelity, and correctness, which are critical for deployment in clinical and regulatory contexts. However, their explanations often exhibited higher complexity, which may increase the cognitive effort required for interpretation. Anchor offered competitive correctness and fidelity but showed notable limitations in reproducibility and latency. These constraints can reduce its applicability in time-sensitive or reliability-critical settings. LIME and CIU stood out in terms of separability and low effective complexity, making them attractive for settings where simplicity and differentiation between instances are important. LIME and CIU often scored 0% in identity, indicating a lack of consistency in the explanations. LIME and Anchor often scored 0% in global identity as well, which raises concerns about the reproducibility and reliability of the explanations these methods generate in practice. These findings underscore that no explanation method dominates across all metrics or use cases. The appropriate choice depends on the application’s interpretability demands, whether prioritizing auditability, simplicity, model alignment, or computational efficiency. Finally, our evaluation does not incorporate human-centered assessments such as usability or clinician feedback. This limits our ability to judge the practical effectiveness of explanations in real-world decision-making. Future work should incorporate expert-in-the-loop studies and assess performance on diverse data modalities.
Metric scores for different global explainability techniques on tabular data.
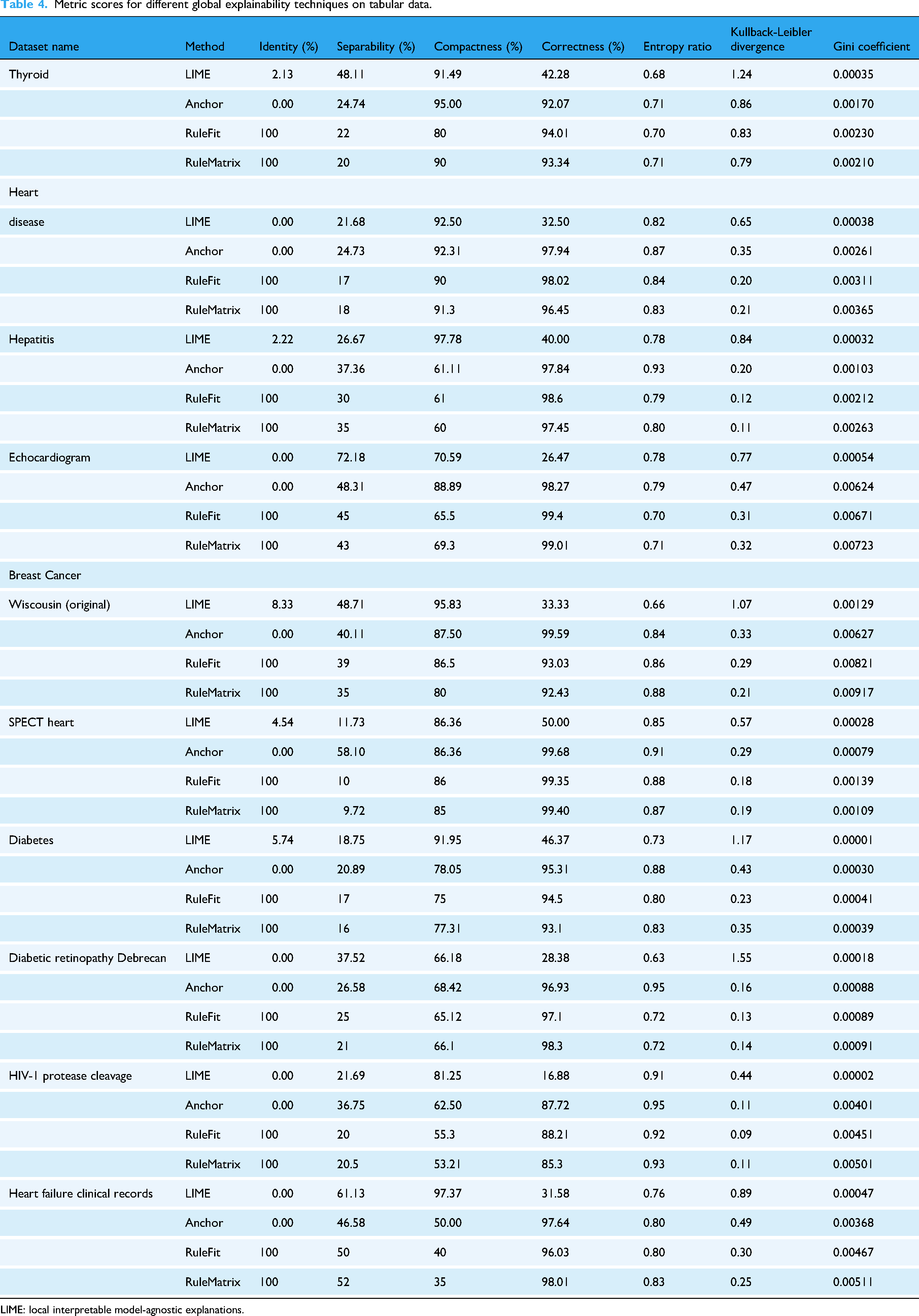
LIME: local interpretable model-agnostic explanations.
Conclusion
This study quantitatively evaluates local (LIME, CIU, RuleFit, RuleMatrix, and ILIME) and global (LIME, Anchor, RuleFit, and RuleMatrix) explanation methods using healthcare datasets. Among global explainability techniques, RuleFit and RuleMatrix consistently perform well, providing clear and robust model interpretations. In contrast, LIME, which prioritizes simplicity, exhibits lower correctness, indicating potential misalignment with the underlying model. For local explainability, RuleFit and RuleMatrix excel in identity, stability, and fidelity metrics, demonstrating strong alignment with model behavior. The variation in performance across different metrics highlights the need for nuanced method selection, emphasizing the importance of prioritizing criteria based on the specific application and carefully considering trade-offs between explainability dimensions. Despite the comprehensive scope of this study, several limitations warrant consideration. First, the analysis focuses on a specific subset of explainability techniques, primarily rule-based and surrogate model approaches. This excludes other prominent families of XAI methods, such as gradient-based saliency techniques and counterfactual explanations, which may behave differently under the same evaluation metrics. Second, the experimental evaluation is limited to structured, tabular datasets derived from clinical settings. Consequently, the generalizability of the findings to unstructured data domains (e.g. medical imaging, clinical notes, or time-series data) remains unexamined. Third, the study emphasizes quantitative assessment metrics—including identity, fidelity, and stability—but does not incorporate human-centered evaluations. In particular, the cognitive and practical interpretability of the generated explanations from a domain expert’s perspective (e.g. clinicians or healthcare practitioners) is not assessed, which is critical for real-world deployment. Lastly, the current evaluation does not explore the computational cost or scalability of the methods, factors that may influence their feasibility in time-sensitive or resource-constrained environments. Furthermore, it is important to acknowledge that not all explanations are equivalent in purpose, granularity, or interpretive utility. Different XAI methods offer fundamentally distinct forms of explanations—ranging from rule-based abstractions to local perturbation-driven approximations—each suited to different users and contexts. For instance, a high-fidelity explanation may not be understandable to a non-technical audience, while a more intuitive explanation may oversimplify model behavior. These epistemic trade-offs highlight the need for incorporating expert-in-the-loop validation protocols to assess explanation relevance, plausibility, and actionability from a domain-specific perspective. In healthcare, engaging clinicians to validate whether the explanations align with clinical reasoning and decision-making pathways is essential. Such human-centered evaluations are a critical next step for ensuring the practical reliability and ethical deployment of explainable AI in high-stakes environments.