
Abstract
Introduction
In formal argumentation, one would sometimes like to show that a particular argument is (credulously) accepted according to a particular argumentation semantics, without having to construct the entire extension the argument is contained in. For instance, to show that an argument is in a preferred extension, it is not necessary to construct the entire preferred extension. Instead, it is sufficient to construct a set of arguments that is
The concept of strong admissibility was introduced by Baroni and Giacomin [1] as one of the properties to describe and categorise argumentation semantics. It was subsequently studied by Caminada and Dunne [3,6] who further developed strong admissibility in both its set and labelling form. In particular, the strongly admissible sets (resp. labellings) were found to form a lattice with the empty set (resp. the all-
As a strongly admissible set (labelling) can be used to explain that a particular argument is in the grounded extension (for instance, by using the discussion game of [4]) a relevant question is whether one can identify an expanation that is
(1) a strongly admissible set that contains
(2) a strongly admissible labelling that labels
It has been found that the problem of computing (1) is NP-hard [11, Theorem 2]1 whereas the verification problem of (2) is co-NP-complete [7, Theorem 2].2 Moreover, it has also been observed that even computing a
The complexity results related to minimal strong admissibility pose a problem when the aim is to provide the user with a relatively small explanation of why a particular argument is in the grounded extension. For this, one can either apply an algorithmic approach that yields an absolute minimal explanation, but has a worst-case exponential runtime, or one can apply an algorithmic approach that has a less than exponential runtime, but does not come with any formal guarantees of how close the outcome is to an absolute minimal explanation [11]. The former approach is taken in [11]. The latter approach is taken in our current paper.
In the absence of a dedicated algorithm for strong admissibility, one may be tempted to simply apply an algorithm for computing the grounded extension or labelling instead (such as [12,13]) if the aim is to do the computation in polynomial time. Still, from the perspective of minimality, this would yield the absolute worst outcome, as the grounded extension (labelling) is the maximal strongly admissible set (labelling). In the current paper we therefore introduce an alternative algorithm which, like the grounded semantics algorithms, runs in polynomial time but tends to produce a strongly admissible set (resp. labelling) that is significantly smaller than the grounded extension (resp. labelling). As the complexity results from [11] prevent us from giving any theory-based guarantees regarding how close the outcome of the algorithm is to an absolute minimal strongly admissible set, we will instead assess the performance of the algorithm using a wide range of benchmark examples.
The remaining part of the current paper is structured as follows. First, in Section 2 we give a brief overview of the formal concepts used in the current paper, including that of a strongly admissible set and a strongly admissible labelling. In Section 3 we then proceed to provide the proposed algorithm, including the associated proofs of correctness. Then, in Section 4 we assess the performance of our approach, and compare it with the results yielded by the approach in [11] both in terms of outcome and runtime. We round off with a discussion of our findings in Section 5.
Preliminaries
In the current section, we briefly restate some of the basic concepts in formal argumentation theory, including strong admissibility. For current purposes, we restrict ourselves to finite argumentation frameworks.
An
As for notation, we use lower case letters at the end of the alphabet (such as
When it comes to defining argumentation semantics, one can distinguish the
Let
Let an admissible set iff a complete extension iff a grounded extension iff a preferred extension iff
As mentioned in the introduction, the concept of strong admissibility was originally introduced by Baroni and Giacomin [1]. For current purposes we will apply the equivalent definition of Caminada [3,6].
Let

An example of an argumentation framework.
As an example (taken from [6]), in the argumentation framework of Figure 1 the strongly admissible sets are
It can be shown that each strongly admissible set is conflict-free and admissible [6]. The strongly admissible sets form a lattice (w.r.t. ⊆), of which the empty set is the bottom element and the grounded extension is the top element [6].
The above definitions essentially follow the extension based approach as described in [10]. It is also possible to define the key argumentation concepts in terms of argument labellings [2,8].
Let if if if
As a labelling is essentially a function, we sometimes write it as a set of pairs. Also, if
Let
Let the grounded labelling iff a preferred labelling iff
We refer to the
The next step is to define a strongly admissible labelling. In order to do so, we need the concept of a min-max numbering [6].
Let if if
It has been proved that every admissible labelling has a unique min-max numbering [6]. A strongly admissible labelling can then be defined as follows [6].
A
As an example (taken from [6]), consider again the argumentation framework of Figure 1. Here, the admissible labelling
It has been shown that the strongly admissible labellings form a lattice (w.r.t. ⊑), of which the all-
The relationship between extensions and labellings has been well-studied [2,8]. A common way to relate extensions to labellings is through the functions
In the current section, we present an algorithmic approach for computing a relatively small3 strongly admissible labelling. For this, we provide three different algorithms. The first algorithm (Algorithm 1) basically constructs a strongly admissible labelling bottom-up, starting with the arguments that have no attackers and continuing until the main argument (the argument for which one want to show membership of a strongly admissible set) is labelled
Algorithm 1
The basic idea of Algorithm 1 is to start constructing the grounded labelling bottom-up, until we reach the main argument (that is, until we reach the argument that we are trying to construct a strongly admissible labelling for; this argument should hence be labelled

Obtaining the min-max numbering is important, as it can be used to show that the obtained admissible labelling is indeed
Instead of first computing the strongly admissible labelling and then proceeding to compute the min-max numbering, we want to compute both the strongly admissible labelling and the min-max numbering in just a single pass, in order to achieve the best performance.
To see how the algorithm works, consider again the argumentation framework of Figure 1. Let
We now proceed to prove some of the formal properties of the algorithm. The first property to be proved is termination.
As for the first loop (the for loop of lines 9–18) we observe that it terminates as the number of arguments in Ar is finite.
As for the second loop (the while loop of lines 21–37) we first observe that no argument can be added to
Next, we need to show that the algorithm is correct. That is, we need to show that the algorithm yields a strongly admissible labelling
Consider the value of if Suppose if Suppose
The next lemma presents an intermediary result that will be needed further on in the proofs.
We prove this by induction over the number of arguments that are added to Suppose the while loop has not yet added any arguments to Suppose that at a particular point, the while loop has added
Algorithm 1 (especially line 22 and line 30) implements a FIFO queue for the
As an example, consider again the argumentation framework of Figure 1. Let
One of the conditions of a min-max numbering is that the min-max number of an
The key to understanding how Algorithm 1 manages to always yield the correct min-max numbering is that the
To make sure that arguments are processed in the order of their min-max numbers, we need to apply a FIFO queue instead of the set that was applied by [13]. The following two lemmas (Lemma 4 and Lemma 5) state that the
We first observe that this property is satisfied just after finishing the for loop of lines 9–18. This is because the for loop makes sure that for each argument Suppose no arguments have yet been added to Suppose the property holds after n arguments have been added to it follows that
In either case, we obtain that
This follows directly from Lemma 4, together with the fact that additions to and removals from
We proceed to show the correctness of
We prove this by induction over the number of loop iterations.
As for the basis of the induction (n = 1), let us consider the first loop iteration. This is just after the for loop of lines 9–18 has finished. We need to prove that if Suppose if This is trivially the case, as at the end of the for loop (lines 9–18) no argument is labelled out.
As for the induction step, suppose that at the start of a particular loop iteration, if We distinguish two cases: if We distinguish two cases:
As we now observed that
In both cases, we obtain that
In order for a labelling to be strongly admissible, its min-max numbering has to contain natural numbers only (no
We prove this by induction over the number of iterations of the while loop at lines 21–37.
As for the basis of induction(n = 1), let us consider the first loop iteration. This is just after the for loop at lines 9–18 has finished. We need to prove that for each if Let if This is trivially the case as the end of the for loop at lines 9–18, no argument is labelled if We distinguish two cases: if We distinguish two cases:
As for the induction step, suppose that at the start of a particular loop iteration, for each
Although most of our results so far are about the algorithm itself, we also need an additional theoretical property of grounded semantics, stated in the following lemma.
First of all, it has been observed that the grounded labelling is both strongly admissible [6] and complete (Definition 7). We proceed to prove that it is also the
If we would not finish the algorithm after hitting the main argument and instead continued to execute the algorithm until
We first observe that This can be proved in a similar way as Lemma 2. This can be proved in a similar way as Lemma 6. This can be proved in a similar way as 7.
We proceed to show that if Suppose if Suppose if
Suppose
This, together with the fact that
From the thus obtained facts that
Using the above lemmas, we now proceed to show the correctness of the algorithm.
We first observe that as This follows directly from Lemma 2. To see that this is the case, we distinguish two cases: The return statement that was triggered was the one at line 16. In that case, The return statement that was triggered was the one at line 33. In that case, Lemma 6 tells us that the value of To see that this is the case, we distinguish two cases: The return statement that was triggered is the one at line 16. In that case, for each The return statement that was triggered is the one at line 33. In that case, Lemma 7 tells us that at the start of the last iteration of the while loop,
It turns out that the algorithm runs in polynomical time (more specific, in cubic time). Let
The basic idea of Algorithm 2 is to prune the part of the strongly admissible labelling that is not needed, by identifying the part that actually is needed. This is done in a top-down way, starting by including the main argument (which is labelled

To see how the algorithm works, consider again the argumentation framework of Figure 1. Let
We now proceed to prove some of the formal properties of the algorithm. The first property to be proved is termination.
At the while loop of lines 12–25, we observe that only a finite number of arguments can be added to
Next, we prove that the labelling that is yielded by the algorithm is smaller or equal to the labelling the algorithm started with.
In order to prove that
Let
Let
Next, we prove that the output of the algorithm is at least admissible (the fact that it is also
The fact that if Let if Let
Next, we prove that the algorithm does not change the min-max values of the arguments it labels
This follows from Theorem 13 and lines 9, 17 and 22 of Algorithm 2.
Next, we prove that the output numbering is actually the correct min-max numbering of the output labelling.
Since if Let if Let
We are now ready to state one of the main results of the current section: the output labelling is strongly admissible.
In order to show that
It turns out that the algorithm runs in polynomial time (more specific, in cubic time).
Let
The idea of Algorithm 3 is to combine Algorithm 1 and Algorithm 2, by running them in sequence. That is, the output of Algorithm 1 is used as input for Algorithm 2.

As an example, consider again the argumentation framework of Figure 1. Let
Given the properties of Algorithm 1 and Algorithm 2, we can prove that Algorithm 3 terminates, correctly computes a strongly admissible labelling and its associated min-max numbering, and runs in polynomial time (more specific, in cubic time).
This follows from Theorem 1 and Theorem 12.
This follows from Theorem 10, Theorem 14, Theorem 16 and Theorem 17.
This follows from Theorem 11 and Theorem 18.
This follows from Theorem 13, together with Theorem 10 and the way Algorithm 3 is defined (by successively applying Algorithm 1 and Algorithm 2).
Now that the correctness of our algorithms has been proved and their computational complexity has been stated, the next step is to empirically evaluate their performance. For this, we compare both their runtime and output with that of other computational approaches.
Minimality
Although Algorithm 3 aims to find a relatively small strongly admissible labelling, it is not guaranteed to find an absolute smallest. This is because the problem of finding the absolute smallest admissible labelling is coNP-complete, whereas Algorithm 3 is polynomial (Theorem 21). In essence, we have given up absolute minimality in order to achieve tractability. The question, therefore, is how much we had to compromise on minimality. That is, how does the outcome of Algorithm 3 compare with what would have been an absolute minimal outcome? In order to make the comparison, we apply the ASPARTIX ASP encodings of [11] to determine the absolute minimal strongly admissible labelling.
Apart from comparing the strongly admissible labelling yielded by our algorithm with an absolute
For queries, we considered the argumentation frameworks in the benchmark sets of ICCMA’17, ICCMA’19 and ICCMA’21.5 For each of the argumentation frameworks we generated a query argument that is in the grounded extension (provided the grounded extension is not empty). We used the queried argument when one was provided by the competition (for instance, when considering the benchmark examples of the
We conducted our experiments on a MacBook Pro 2020 with 8 GB of memory and an Intel Core i5 processor. To run the ASPARTIX system we used clingo v5.6.2. We set a timeout limit of 1000 seconds and a memory limit of 8 GB per query.
For each of the selected benchmark examples, we have assessed the following:
the size of the grounded labelling (determined using the modified version of Algorithm 1 as described in Lemma 9)
the size of the strongly admissible labelling yielded by Algorithm 1
the size of the strongly admissible labelling yielded by Algorithm 3
the size of the absolute minimal strongly admissible labelling (yielded by the approach of [11])
We start our analysis with comparing the output of Algorithm 1 and Algorithm 3 with the grounded labelling regarding the size of the respective labellings. We found that the size of the strongly admissible labelling yielded by Algorithm 1 tends to be smaller than the size of the grounded labelling. More specifically, the strongly admissible labelling yielded by Algorithm 1 is smaller than the size of the grounded labelling in 63% of the 277 examples we tested for. In the remaining 37% of the examples, their sizes are the same.

The size of output of Algorithm 1 (as a percentage of the grounded labelling).
Figure 2 provides a more detailed overview of our findings, in the form of a bar graph. The rightmost bar represents the 37% of the cases where the output of Algorithm 1 has the same size as the grounded labelling (that is, where the size of the output of Algorithm 1 is 100% of the size of the grounded labelling). The bars on the left of this are for the cases where the size of the output of Algorithm 1 is less than the size of the grounded labelling. For instance, it was found that in 10% of the examples, the size of output of Algorithm 1 is 80% to 89% of the size of the grounded labelling. On average, we found that the size of the output of Algorithm 1 is 76% of the size of the grounded labelling.

The size of output of Algorithm 3 (as a percentage of the grounded labelling).
As for Algorithm 3, we found an even bigger improvement in the size of it’s output labelling compared to the grounded labelling. More specifically, the size of the strongly admissible labelling yielded by Algorithm 3 is smaller than the grounded labelling in 88% of the 277 examples we tested for. Figure 3 provides a more detailed overview of our findings in a similar way as we previously did for Algorithm 1. On average, we found that the output of Algorithm 3 has a size that is 25% of the size of the grounded labelling.

The size of output of Algorithm 1 compared to the output Algorithm 3 (as a percentage of the size of the grounded labelling).
Apart from comparing Algorithm 1 and Algorithm 3 with the grounded labelling, it can also be insightful to compare the two algorithms with each other. In Figure 4, each dot represents one of the 277 examples.6 The horizontal axis represents the size of the output of Algorithm 1, as a percentage of the size of the grounded labelling. The vertical axis represents the size of the output of Algorithm 3 as a percentage of the size of the grounded labelling. For easy reference, we have included a dashed line indicating the situation where the output of Algorithm 1 has the same size as the output of Algorithm 3. Any dots below the dashed line represent the cases where Algorithm 3 outperforms Algorithm 1, in that it yields a smaller strongly admissible labelling. Any dots above the dashed line represents the cases where Algorithm 3 under performs Algorithm 1 in that it yields a bigger strongly admissible labelling. Unsurprisingly, there are no such cases as Theorem 22 states that the output of Algorithm 3 cannot be bigger than the output of Algorithm 1. We found that for 95% of the examples, Algorithm 3 produces a smaller labelling than Algorithm 1. Moreover, we found that on average, the output of Algorithm 3 is 32% smaller than output of Algorithm 1.

The size of output of Algorithm 3 compared to a smallest strongly admissible labelling (as a percentage of the size of the grounded labelling).
The next question is how the output of our best performing algorithm (Algorithm 3) compares with what would have been the ideal output. That is, we compare the size of the output of Algorithm 3 with the size of a minimal strongly admissible labelling for the main argument, as computed using the ASPARTIX encodings of [11]. The results are shown in Figure 5.
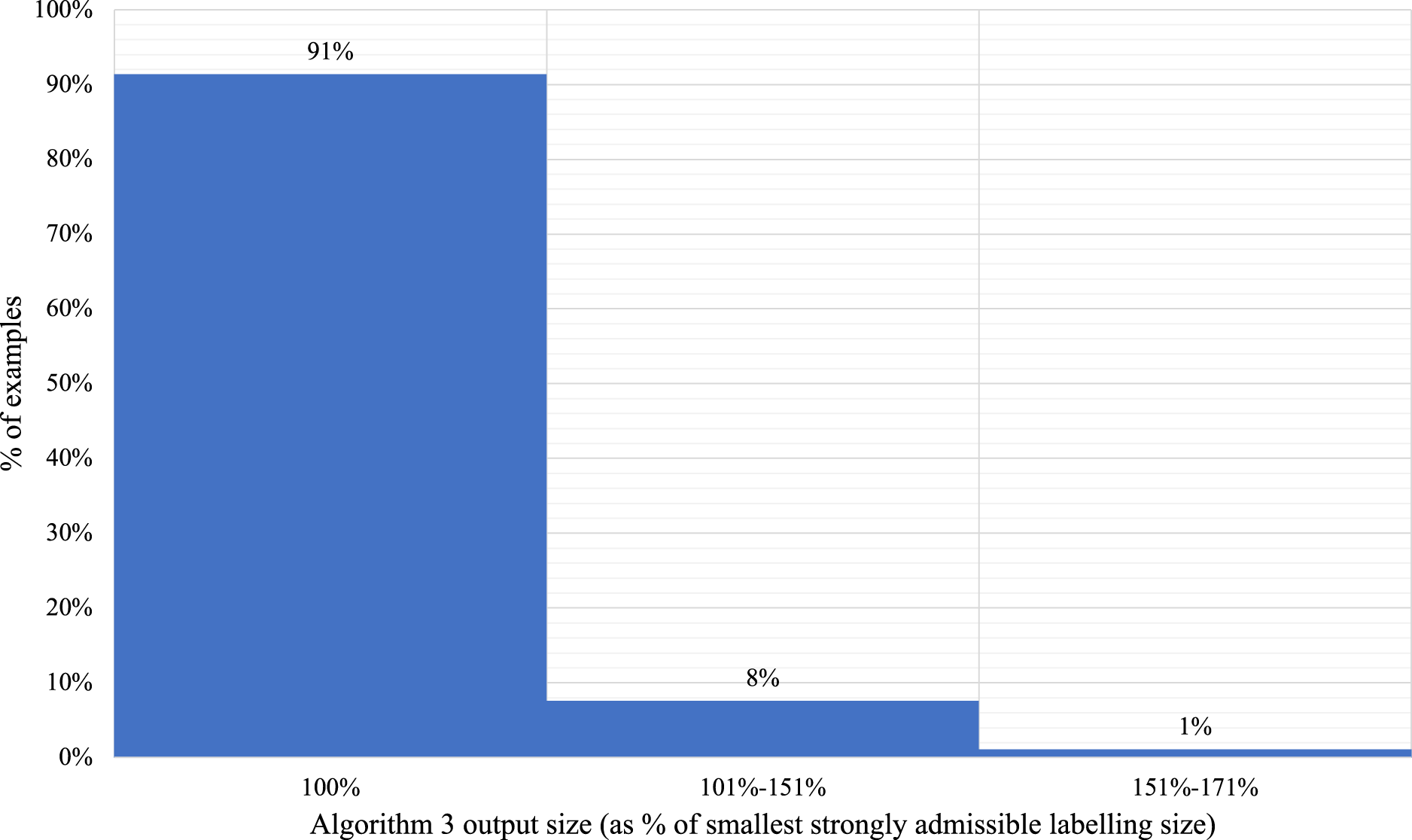
The size of output of Algorithm 3 compared to a smallest strongly admissible labelling.
We found that in 91% of the 277 examples, the output of Algorithm 3 is of the same size as the smallest strongly admissible labelling for the output of the main argument. For the other 9% of the examples, the output of Algorithm 3 has a bigger size. On average, we found that the output of Algorithm 3 is 3% bigger than the smallest strongly admissible labelling for the main argument. Figure 6, provides a more detailed overview of how much bigger the output of Algorithm 3 is compared to the smallest strongly admissible labelling for the main argument.
The next thing to study is how the runtime of our algorithms compares with the runtime of some of the existing computational approaches. In particular, we compare the runtime of Algorithm 1 and Algorithm 3 with the runtime of the ASPARTIX-based approach of [11].

The runtime of Algorithm 3 compared to the runtime of computing the grounded labelling using Algorithm 3 of [13].
We first compare the runtime of Algorithm 3 to the runtime of the modified version of Algorithm 3 of [13] for computing the grounded labelling. It turns out that the runtimes of these algorithms are very similar. On average, Algorithm 3 of [13] took 0.02 seconds (3%) more than Algorithm 3 to solve the test instances. These runtime results of Algorithm 3 and Algorithm 3 of [13] are shown in Figure 7.

The runtime of computing a smallest admissible labelling using the ASPARTIX encodings compared with the runtime of Algorithm 3.
The next question is how does the runtime of computing Algorithm 3 compare to the runtime of the ASPARTIX encoding for minimal strongly admissibility. It was observed that the runtime of ASPARTIX encoding is significantly longer than the runtime of Algorithm 3. A detailed overview of the difference in runtimes of Algorithm 3 and the ASPARTIX encoding on minimal strong admissibility is shown in Figure 8. On average, the ASPARTIX framework took 12.5 seconds (907%) more than Algorithm 3 to solve the test instances.
In the current paper, we provided two algorithms (Algorithm 1 and Algorithm 3) for computing a relatively small strongly admissible labelling for an argument that is in the grounded extension. We proved that both algorithms are correct in the sense that each of them returns a strongly admissible labelling (with associated min-max numbering) that labels the main argument
The next question we examined is how small the output of Algorithm 1 and Algorithm 3 is compared to the smallest strongly admissible for the main argument. Unfortunately, previous findings make it difficult to provide formal theoretical results on this. This is because the c-approximation problem for strong admissibility is NP-hard, meaning that a polynomial algorithm (such as Algorithm 1 and Algorithm 3) cannot provide any guarantees of yielding a result within a fixed parameter
Hence, instead of developing theoretical results, we decided to approach the issue of minimality in an empirical way, using a number of experiments. These experiments were based on the benchmark examples that were submitted to ICCMA’17, ICCMA’19 and ICCMA’21. We compared the output of Algorithm 1 and Algorithm 3 with both the biggest and the smallest strongly admissible set for the main argument (the biggest was computed using Algorithm 3 described in [13] and the smallest was computed using the ASPARTIX based approach on computing minimal strong admissibility in [11]). Overall, we found that Algorithm 3 yields results that are only marginally bigger than the smallest strongly admissible labelling, with a run-time that is a fraction of the time that would be required to find this smallest strongly admissible labelling. The outputs of both algorithms return a strongly admissible labelling that is significantly smaller than the biggest strongly admissible labelling (the grounded labelling), with the output of Algorithm 3 on average being only 25% of the size of the biggest strongly admissible labelling.
Although our Algorithm 3 tends to yield good results in most cases (obtaining an absolute smallest strongly admissible labelling in 91% of the examples we tested for) there are some argumentation frameworks where it will not perform well. An example of such an argumentation framework is shown in Figure 9.

An example of an argumentation framework where Algorithm 3 yields a strongly admissible labelling that is not minimal.
For the argumentation framework of Figure 9, Algorithm 3 will yield the strongly admissible labelling
To understand how such a suboptimal result was produced, it is important to realise that Algoritm 2, when choosing an
Algorithm 1 requires that the main argument (argument
Algorithm 2 could to some extent be optimised by adding an extra condition to line 15, so that the for-loop only runs for attackers that are not yet labelled
The research of the current paper fits into our long-term research agenda of using argumentation theory to provide explainable formal inference. In our view, it is not enough for a knowledge-based system to simply provide an answer regarding what to do or what to believe. There should also be a way for this answer to be explained. One way of doing so is by means of (formal) discussion. Here, the idea is that the knowledge-based system should provide the argument that is at the basis of its advice. The user is then allowed to raise objections (counterarguments) which the system then replies to (using counter-counter-arguments), etc. In general, we would like such a discussion to be (1) sound and complete for the underlying argumentation semantics, (2) not be unnecessarily long, and (3) be close enough to human discussion to be perceived as natural and convincing
As for point (1), sound and complete discussion games have been identified for grounded, preferred, stable and ideal semantics [4]. As for point (2), this is what we studied in the current paper, as well as in [3,6]. As for point (3), this is something that we are aiming to report on in future work.
For future research, it is possible to conduct a similar sort of analysis (as in this paper) on minimal admissible labellings. It was reported obtaining an absolute minimal admissible labelling for a main argument is also of coNP-complete complexity [3,6] therefore, it would be interesting to look into developing an algorithm that generates a small admissible labelling in polynomial time complexity. Similarly, it would also be interesting to look at the complexity and empirical results on generating minimal ideal sets.