
Abstract
Introduction
Knowledge graphs (KGs) as a formalism for knowledge representation and management,
have emerged as underlying technology of many downstream AI tasks, including
recommendation systems and question-answering systems, and so on [6,25]. Example of such KGs are DBPedia [23], YAGO [33], and
NELL [12]. Generally, knowledge graphs
consist of a collection of triples representing real world facts, in the form of
Facts in the real world, often involve time, for which the representation in KGs need
to be extended beyond triples (e.g., quadruples, quintuples), to include the
temporal knowledge [11]. These type of KGS
are called temporal knowledge graphs (TKGs) such as ICEWS [9], GDELT [22] and
Wikidata [37]. In TKGs designed with
quadruples, the facts are represented with one timestamp in the form
Among different types of TKGEs, Tensor-based models which employ tensor decomposition techniques, have demonstrated remarkable efficacy in representing temporal facts [30,46]. As a remark, relations in TKGs serve as the connectors linking entities to form a fact, and time constitutes the temporal validity attribute of the fact. By decomposing the facts into tensors, quadruples are transformed into lower-dimensional embeddings, effectively mitigating complexity, and information from diverse attributes can be integrated to achieve comprehensive representations [24]. Different tensor decomposition methods, such as Canonical Polyadic (CP) decomposition [35] and Tucker decomposition [4], are leveraged in KGEs such as [4,20,30]. In these models, associations between entities, relations and timestamps are established through multiplication operations directly, thereby subject entities, relations, timestamps, object entities have the same status, and there is no clear distinction between them. However, generally in temporal facts, the connection between relations and semantics fundamentally diverges from the connection between time and semantics imposed by relations. As one relation constitutes the main part of a fact that represents the main semantics, the timestamp only gives the semantics an attribute about time. Therefore, when learning over temporal facts, it is important to not only account for the semantic aspects of these facts but also recognize the importance of the temporal attribute for each individual fact. For example, some relations, such as “parents of”, “brother of in” and so on, do not have obvious time dependence, therefore, the facts composed of these relations do not have significant characteristics about time in the temporal knowledge graph. In contrast, some relations exhibit significant temporal properties. However, those tensor-based models often prioritize considerations regarding how to accurately represent timestamps or the entirety of quadruples. The methods to derive connections among these three components through straightforward multiplication fail to align with the authentic meaning of some temporal facts. Consequently, they tend to overlook the intricate interplay between time and semantics inherent in real-world facts.
We introduce a novel model dubbed TRKGE, considering temporal relevance in temporal knowledge graph, which leverages the tensor decomposition method but facilitated to be aware of time importance. Temporal relevance is used to judge the importance of time in facts when learning their representation. For example, the semantics of facts formed by “visit” and “daughter of” have different temporal attributes, one is temporary and the other is permanent. Similar to other tensor decomposition models, our model is also built in the complex space. But the real and imaginary parts of our model represent different information. The real part learns the semantic features of facts with a bias based on temporal relevance, while the imaginary part learns characteristics without a bias. The real part of our model focuses on capturing temporal relevance within the facts. To ensure consistency between the transformation in the real part and complex multiplication, we employ rotation matrices in this part. These matrices effectively adjust entities based on relations and timestamps, facilitating a specific understanding of timestamps and semantics. Furthermore, we introduce attention mechanisms in the real part to learn the temporal relevance within the facts. This attention mechanism allows the model to learn the relational and temporal information of facts in a certain weighting to make them more relevant to the actual meaning. On the other hand, the imaginary part of our model utilizes half of the embeddings to learn the connections among diverse elements through direct multiplication. Then the imaginary part complements the real part in capturing complex relationships within temporal knowledge graphs. Experimental results underscore its performance in comparison to state-of-the-art baselines, thereby illustrating the ability of the proposed method in learning temporal relevance when representing temporal facts.
In this work, the main contributions include:
The following sections will dive into
these contributions in detail.
Related work
In this section, we review the existing literature on knowledge graph embedding methods, categorizing them into two main areas: Static KGE and Temporal KGE. Static KGE methods focus on representing the entities and relationships of knowledge graphs that remain constant over time. These models embed the nodes and edges into a fixed, continuous vector space, effectively capturing the structure and semantics of the graph. However, real-world knowledge graphs often include a temporal dimension, where each fact is associated with a specific time point or interval. This necessitates the development of Temporal KGE methods. These approaches extend static models by incorporating temporal information into the embeddings, capturing the evolution of facts across different time points. Below is a more detailed discussion on these two categories.
The TRKGE model: Time relevance in temporal knowledge graph embedding
In this section, we introduce the proposed model for which we first set the foundation by defining the mathematical notation and terms that will be consistently used throughout the discussion. Next, we explain the core concept of Temporal Relevance that represents temporal dynamics within data. Finally, we introduce the model itself, termed TRKGE (Temporal Relevance Knowledge Graph Embedding).
Notation and background for model formulation
As a lead-in to the model formulation, Table 1
provides an overview of the notations employed throughout this section. Now, let
us consider a temporal knowledge graph in which the facts are represented as
quadruples
An overview of the symbols used in TRKGE model formulation, along with
their corresponding meanings
An overview of the symbols used in TRKGE model formulation, along with their corresponding meanings
Temporal knowledge graph embedding models aim at completing such TKGs by learning embeddings of entities, relations, and timestamps. The score function of a TKGE model measures the likelihoods of quadruples, hence, new quadruples can be inferred, and their plausibility can be judged to complete the TKG. For temporal facts, relations have different time sensitivities. Therefore, when learning temporal information, the proportion of time information versus relational information in different facts is also needed to be considered. The proposed TRKGE model is capable of capturing these complexities of time relevance with rereads to relations. The rest of this section focuses on the mathematical concepts required to understand, details theories and development of our model TRKGE.
As all geometric TKGE models, our model embeds entities in a continuous vector space and uses geometric transformation to preserve information between subject and object entities.
A vector space
Interaction between subject and object entities is done via a variety of
geometric transformations. In the literature, many KGE models are built upon the
rotation transformation. Similarly, our model uses rotation. However, there is a
systematic difference between how the rotation transformation was used by other
models. In fact a two-dimensional representation of a rotation of angle
The proposed model is designed to capture temporal information in knowledge graphs by incorporating Temporal Relevance concept into its architecture.
To allow the model to selectively learn relational and temporal information based
on temporal relevance, we transform subject entities according to relation and
time embeddings, respectively. In order to gain the temporal relevance, subject
entity embeddings need to be transformed simultaneously by time and relation
embedding. In our model, when calculating the scores, the real part of final
transformed embeddings includes the temporal relevance, and the imaginary part
is the original imaginary part. And when learning the temporal relevance, both
real and imaginary part of subject entity embedding should be considered, The
transformation is defined as
We thereafter use the attention mechanism to quantify the proportion of temporal information and relational information in facts.
The attention mechanism is proven to have a very significant role in deep
learning models [13,36]. Since the semantics of facts is
intrinsically related to relations, the temporal relevance of the facts is also
determined by the relations. The attention mechanism allows TRKGE to use
relation-specific attention vector, defined as
Then, the transformed embedding, aware of temporal relevance, can be obtained by
However, as
The score function of the TRKGE model is defined as the real part of the
Hermitian inner product of embeddings of transformed subject entities,
relations, timestamps, and object entities. This is obtained as follows
Figure 1 shows how the TRKGE model framework is benefiting from complex space and the concept of temporal relevance in its score design.

A layered visualization of the TRKGE model and its scoring function and framework.
In Eq. (9), the real part of embeddings focus on the
temporal relevance, and the imaginary part is used to learn the relationships
between different elements in quadruples. However, both the real and imaginary
parts of embeddings are involved in the part of temporal relevance, during
training the original semantic information gradually loses, which is mainly
composed of relations. Therefore, inspired by TNTComplEx [35] that design an extra embedding for time property, we
also design an additional relation embedding to represent original semantic
information of facts, and use addition to combine it with the relation and time
embeddings to enhance the learning of original semantics. Therefore the final
score function is
Besides, a regularization term is added to the loss function to limit the
complexity of the model, thus reducing the overfitting of the model. It can also
improve the generalization ability of the model, so that the model can be better
generalized to unknown data. Regularization is used separately for all
embeddings. Because the relational part in the model is divided into two parts,
and scores of two relation embeddings are calculated separately, we propose the
following regularization.
During training, timestamp embeddings should behave smoothly over time to
facilitate a better representation, and the embeddings of adjacent timestamps
should be close together. For this, a temporal smoothness objective is used in
the loss function.
Therefore, the final loss function is:
Datasets and baseline models, and evaluation methodology
We compare our model with other baselines through temporal knowledge graph completion on three popular benchmarks namely ICEWS14, ICEWS05-15 and GDELT. The first two datasets are subsets of Integrated Crisis Early Warning System(ICEWS) dataset that contains information about international events. ICEWS14 collects the facts that occurred between January 1, 2014 and December 31, 2014, and ICEWS05-15 contain events from January 1, 2005 to December 31, 2015. GDELT is a subset of the The Global Database of Events, Language, and Tone (GDELT) that captures events and news coverage from around the world. This dataset includes conflict, cooperation, diplomatic, economic, humanitarian events and so on. GDELT is a very dense TKG, it has 3.4 million quadruples but only 500 entities and 20 relations. Table 2 is the statics of these three datasets.
Statistics for ICEWS14, Yago15k and GDELT
Statistics for ICEWS14, Yago15k and GDELT
In the experiments, baselines are chosen from both static KGE models and TKGE models. From the static KGE models, we use TransE [8], DisMult [44], QuatE [47]. We also compare our model with some state-of-the-art TKGE models, such as TTransE [21], HyTE [15], TA-DistMult [17], ATiSE [43], TeRo [42], RotateQVS [14], TCompleEx [20], TNTComplEx [20], BoxTE [26], TLT-KGE(Complex) [46] and TLT-KGE(Quaternion) [46], TASTER [38].
In this work, we perform the evaluations with a focus on link prediction task.
This means to replace
In our experiments, we utilize time-aware filters [18], which are also employed by the baseline models. This filter differs from the static models as it incorporates timestamps during the process of filtering out entities, which is meaningful for temporal knowledge graph representation.
Hyperparameters of TRKGE for ICEWS14, Yago15k and GDELT
Hyperparameters of TRKGE for ICEWS14, Yago15k and GDELT
We performed extensive evaluations ensuring to reflect the strength of the proposed model. First, we report the performance of the TRKGE model and other baselines on the three aforementioned benchmark datasets. The experimental results for these performance evaluations are shown in Table 4. The main result which can be seen in the table is that our model outperforms all other baseline models on 2000 dimensions in all the metrics. While on the ICEWS14 and ICEWS05-15 datasets, the TLT-KGE model performs better that other baseline models, our model still improves the results with a high margin. On the MRR metric, our model outperforms TLT-KGE model by a delta of 1.6%, on the ICEWS14 dataset and with a margin of 0.2% on the ICEWS05-15 dataset. On the GDELT dataset, TNTComplEx model is the best baseline model. But our model TRKGE outperforms TNTComplEx by 4.1% on GDELT. In 1500 dimensions that is the setting used by most of the baseline models, our model is performing better than any other model on the two ICEWS14 and GDELT datasets. Its results are comparative with the best of state-of-the-art results on ICEWS05-15. As a sign of robustness, our proposed model shows a constant performance increase on all these datasets which are challenging for the upfront models.
Experimental results on ICEWS14, ICEWS05-15 and GDELT. The results labeled
with * are from the paper [14].
The results of TComplEx and TNTComplEx on GDELT are produced from their
original code. Other results are reported in their own paper
Experimental results on ICEWS14, ICEWS05-15 and GDELT. The results labeled with * are from the paper [14]. The results of TComplEx and TNTComplEx on GDELT are produced from their original code. Other results are reported in their own paper
Table 4 also shows that most of the baseline models have different representation capabilities on the versions of ICEWS datasets and GDELT. For example, TLT-KGE performs well on both ICEWS14 and ICEWS05-15, but its performance is mediocre on the GDELT dataset. In contrast, the T(NT)ComplEx model performs well on GDELT, but badly on the other two datasets namely ICEWS14 and ICEWS05-15. This observation can be explained based on the significant structural and statistical differences between those datasets and lack of models in handling those differences. We observed three aspects on these differences including:
Density of Relations – This refers to the distribution of facts among relations. A dataset is considered denser if a higher number of relations have more facts associated with them.
Temporal Relevance – This is determined by the number of timestamps in the dataset. A dataset with more timestamps indicates richer temporal information.
Semantic Richness of Relations – This is determined by the number of facts associated with each relation. A dataset where most relations have a high number of facts indicates that the relations have rich semantics.
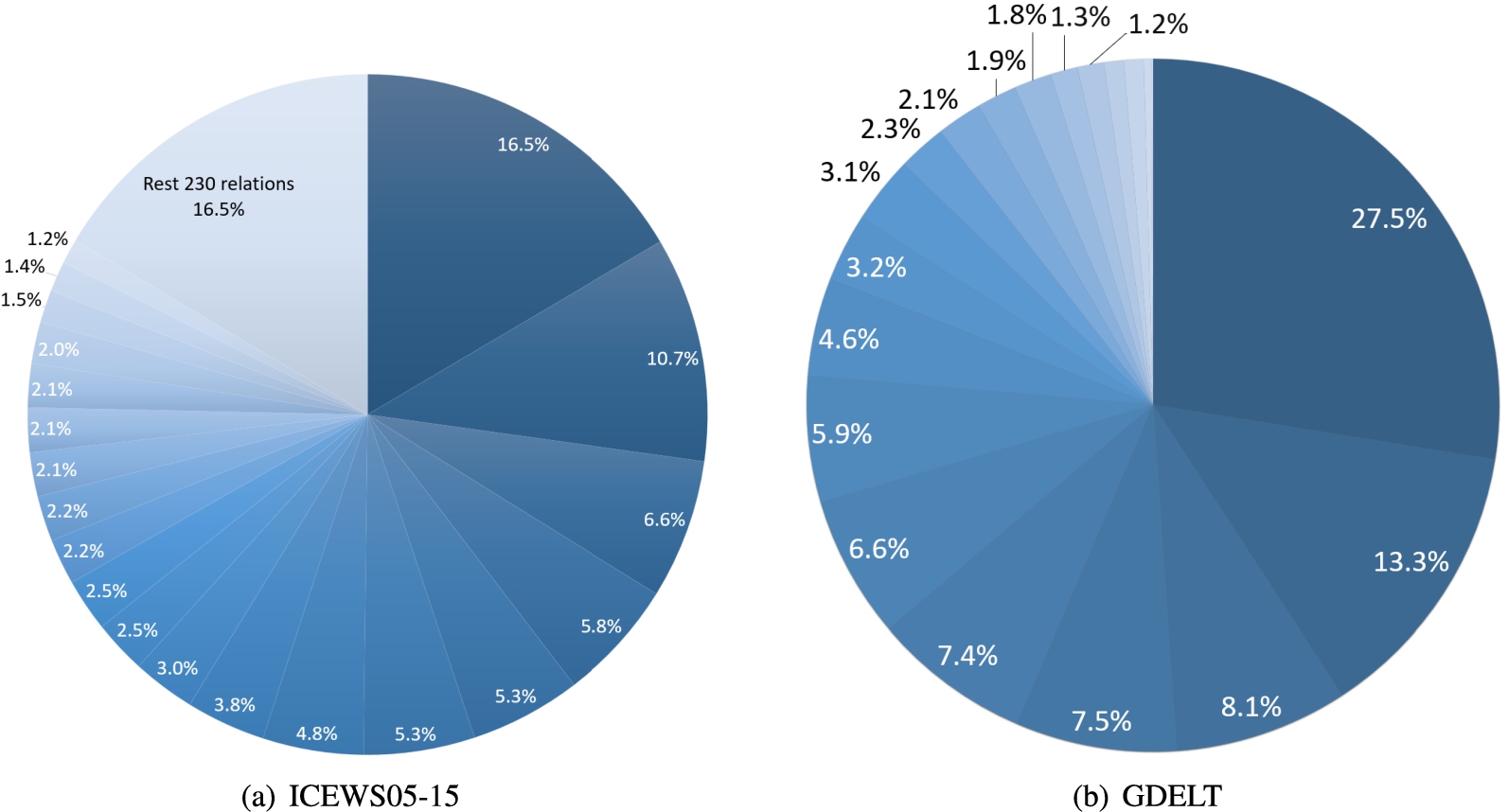
Percentage of existing quadruples per each relations in two datasets.
Statistics of the number of quadruples associated with relations on ICEWS05-15 and GDELT
ICEWS14 and ICEWS05-15 have higher number of entities, relation types, and timestamps than GDELT which are shown in Table 2. While the GDELT dataset has only 20 relations, it is way denser than the other two datasets and have much larger data volume in terms of facts. We show the number of quadruples for different relations in Fig. 2, and we also give the information about the number of quadruples formed by each relation in Table 5. As the statistics of the two datasets ICEWS14 and ICEWS05-15 are similar, we only show the case of ICEWS05-15. It is noting that in both ICEWS14 and ICEWS05-15, the top 10 relations in terms of quantity almost construct the 60% of the datasets. In ICEWS05-15, there are 212 relations, among which each relation is present in less than 1000 facts. Only 39 relations out of 212 is present in more than 1000 facts, which leads to less density, resulting in a weak expression ability of most relations. At the same time, this dataset has more than 4000 timestamps that makes the temporal information more relevant. Different from the ICEWS05-15 dataset, in GDELT, there are 10 relations that each of them built more than 100 thousand facts, and 9 relations that each of them built more than 10 thousand facts, so all relations are relatively fully used in different facts. Such a small number of relations and timestamps contribute to a large amount of data, indicating that both relations and time have rich semantics in this dataset.
The baseline models, TNTComplEx and BoxTE, learn the semantics of relations and timestamps equally, allowing them to have good representation capabilities on GDELT. In contrast, TLT-KGE specifically models temporal information by using many extra embeddings related to time, leading to its strong performance on ICEWS05-15, but its normal performance on GDELT shows their design is limited. Based on the best results of our model on three datasets, it can be concluded that our model, by calculating temporal relevance and placing emphasis on learning temporal and relational information, demonstrates good adaptability to different types of datasets. Additionally, with the increase in dimensions, the model’s representational power also improves. The performance of some well-performing baseline models in high dimensions will be discussed in the analysis of the model’s parameter quantity.
We conducted an ablation experiment on the temporal relevance component. In order to do so, the attention mechanism was removed from the model design with a focus on learning temporal information and relational information. Rel-TR focuses on relational information, while Time-TR focuses on temporal information. Table 6 shows that Time-TR outperforms Rel-TR by 6% on ICEWS14 and 3% on ICEWS05-15, while these two models perform similarly on GDELT.
Impact of learning relational and temporal information is evaluated by
Rel-TR and Time-TR, where Rel-TR only learns relational information and
Time-TR only learns temporal information. Im-TR only learns relational
and temporal information with temporal relevance, ignoring the original
information of facts. Sem-TR removes the extra relation embedding for
learning the semantics of facts
Impact of learning relational and temporal information is evaluated by Rel-TR and Time-TR, where Rel-TR only learns relational information and Time-TR only learns temporal information. Im-TR only learns relational and temporal information with temporal relevance, ignoring the original information of facts. Sem-TR removes the extra relation embedding for learning the semantics of facts
As mentioned in the main experiment, in ICEWS14 and ICEWS05-15, time plays a significant role, and in GDELT, both temporal and relational information are important. The results of Time-TR and Rel-TR align with these characteristics. Furthermore, in order to test the design of the imaginary part in our original model which is used to save the original information of facts, Im-TR is proposed, where both real and imaginary parts learn relational and temporal information with temporal relevance.
On ICEWS14 and ICEWS05-15, Im-TR performs better than Rel-TR but worse than Time-TR., which means that Selectively learning information leads to the improved performance, but it still loses some information when compared with Time-TR and original model. On GDELT it performs better than both Rel-TR and Time-TR and similarly to original model. As facts in GDELT have rich temporal and relational information, the attention mechanism has a weak bias towards these two types of information, which is also shown in Fig. 3(b). Therefore, Im-TR is similar with original one on GDELT.
Sem-TR performs worse on both ICEWS14 and ICEWS05-15. From Fig. 3(a), we can see on ICEWS datasets, the attention mechanism mainly focus on the temporal information, which leads to a massive lack of relational information, so extra relation embedding for enhancing the learning of the semantics of facts is important in our orginal design. Similar with Im-TR, attention mechanism dose not play an important role on GDELT, so the lack of information is less, and its performance is also close to TRKGE.
Overall, the original model TRKGE has the best performance, which demonstrates the meaningfulness of biased learning towards temporal and relational information. It not only improves the model’s performance but also increases its adaptability to different datasets.
In order to visualize the emphasis on time, we show attention values on two datasets of ICEWS05-15 and GDELT in Fig. 3. In the left hand side, the Fig. 3 (a), we can see that the attention values for the frequent three relations on ICEWS05-15 are almost 1. This means the learning is entirely biased towards time, while the attention values for the less frequent relations are evenly distributed around 0.5. However, the most frequent 10 relations constitute 60% of the facts in ICEWS05-15. This indicates that the impact of the less frequent relations is not very high. Therefore, Time-TR model can effectively capture the majority of the facts but cannot represent the remaining facts well, resulting in slightly weaker performance compared to our model, TRKGE. In the case of the GDELT dataset, where both relations and timestamps exhibit rich semantic information, the attention values are centered around 0.5 in the visualization. This aligns with the characteristics of this dataset in terms of time relevance relations which is also consistent with the performance of Rel-TR, Time-TR and Im-TR.

Attention values on ICEWS05-15 and GDELT. In the left (a), the first 3 values are from the most frequent 3 relations, the last 4 values are from the least frequent relations, and the middle 3 values are randomly selected. In the right (b), because of the small number of relations and memory limitations, the values are selected from the middle 10 relations.
In this section, we performed an experiment to compare TNTComplEx, TLT-KGE and our model in terms of the number of parameters to reflect their efficiency. Table 7 provides a reference for the number of parameters of each model. It is evident that the performance gain of our model is not with higher parameter count than the other leading models, emphasizing its efficiency.
Model parameter count for TRKGE, TNTComplEx and TLT-KGE. For TLT-KGE,
w is the number of shared time windows
Model parameter count for TRKGE, TNTComplEx and TLT-KGE. For TLT-KGE,
These three models were evaluated on dimensions of 500, 1000, 1500, and 2000, and line graphs were plotted and shown in Fig. 4, to represent the model’s performance with the number of parameters in four dimensions. As the Mean Reciprocal Rank (MRR) can indicate the overall effectiveness of a model, we correlated MRR with the number of parameters in the the graphs to illustrate the performance of different models under varying parameter counts. From Fig. 4, it can be observed that TNTComplEx performed poorly on ICEWS14 and ICEWS05-15 but excelled on GDELT due to its design for simultaneously learning relational and temporal information. TLT-KGE performed well on ICEWS14 and ICEWS05-15 but poorly on GDELT, since it is designed to capture more temporal information, which results in more parameters, especially in the case of ICEWS05-15, where its number of parameters is much more than TNTComplEx and our model. From the graphs, it is obvious that our model achieves better results on ICEWS14 with similar parameter counts. On ICEWS05-15, our model can achieve similar optimal results with only half of parameters of TLT-KGE. On GDELT, both our model and TNTComplEx effectively learn rich information from relations and timestamps and achieve better results with much fewer parameters than TLT-KGE.

Performance under different numbers of parameters. Circles represent 500 dimensions, triangles represent 1000 dimensions, stars represent 1500 dimensions, and squares represent 2000 dimensions.
In order to further test the efficiency of our models, we chose three models that performe well to compare the runtimes, TNTComplEx, TLT-KGE(Complex), and TLT-KGE(Quaternion). Although BoxTE also performs well, it takes several days to run, so it was not chosen here. As four models are the tensor decomposition models, they do not need many epochs, so we set the epoch to 100 and the models are tested every 10 epochs, and then the total time of each model is reported. From the Table 8 we can see that the most basic model, TNTComplEx spends the least time on all three datasets. The running time of our models is closer to TNTComplEx on ICEWS14 and ICEWS05-15, while the two models of TLT-KGE need more time. On GDELT, our model requires more time to train, because a small number of entities and relationships and a large number of facts bring complex information, which influences the temporal relevance part and gives a big boost to the performance, but it is still close to the runtime of TLT-KGE(Quaternion).
Running time of three model in units of seconds
For the task of temporal knowledge graph completion, most tensor decomposition models are efficient, we bring temporal relevance into the model and our model still has better performance with little time cost. Therefore, our model can efficiently and effectively represent temporal facts well in different types of TKGs.
By decomposing embeddings into real and imaginary parts, we have ensured that both temporal and relational information in facts are well-represented. The real part plays a crucial role in preserving temporal relevance of relational knowledge, guaranteeing that time-sensitive relations are not marginalized. In contrast, the imaginary component captures the nature of the original information, preventing potential information loss. This distinction and simultaneous handling of these components empower our model to preserve more complex characteristic in TKGs. Our experimental results serve as a testament to the model’s proficiency. By excelling in link prediction tasks and outperforming existing state-of-the-art models, it underscores its capability to cater to the dynamics of TKGs. The novelty presented in this paper is not just in the creation of an advanced embedding model but also the demonstration that understanding and effectively representing the interplay between time and relationships in knowledge graphs can bring significant improvements. This serves as a new direction for future research in refining temporal relevance measures or exploring other complex space representations. In conclusion, as TKGs continue to grow in relevance, models like ours will be instrumental in ensuring that the temporal and relational information they contain is comprehensively captured and utilized. We believe that our proposed model sets a new benchmark in TKG embedding.
In future work, we aim at extending this model to handle more intricate temporal patterns by incorporating advanced time-aware components. Additionally, exploring alternative complex space, like quaternion space, representations may unlock even more efficient ways to represent temporal and relational dynamics in knowledge graphs.