
Abstract
1. Introduction
When performing a given task in an unfamiliar environment, human beings easily adapt the skills or previously learned motions to novel situations and environments. For instance, the operator in Figure 1 wipes the front panels of the train by employing a small set of motions and skills that generalize to different train geometries and positioning (Moura and Erden, 2017). However, current robotic systems often require computationally expensive replanning and precise scans of the new environment to reproduce a given task (Pastor et al., 2011; Shiller, 2015). In addition to this, movement in complex, high degree of freedom manipulation systems often contains a high level of redundancy. The degrees of freedom available to perform a task are usually higher than what is necessary to execute that task. This allows a certain flexibility in finding an appropriate solution, so that this redundancy may be resolved according to some strategy that achieves a secondary objective, while the primary task is not affected. Such approaches to redundancy resolution are employed by human beings (Cruse and Brüwer, 1987), as well as other redundant systems, such as (humanoid) robots (D’Souza et al., 2001).

Manual cleaning of an electric train. Willesden depot, London (2016).
The redundancy resolution may also be interpreted as a form of hierarchical task decomposition, in which the complete space of available movement is split into a task-space component and a null-space component. For instance, one might consider a primary task, such as reaching or trajectory tracking, and a lower-priority task as a secondary goal, such as avoiding joint limits (Gienger et al., 2005), self-collisions (Sugiura et al., 2006), or kinematic singularities (Yoshikawa, 1985). This notion is particularly evident when considering motions modulated by external or environmental constraints. For instance, in the wiping task of Figure 1, the tool is constrained by the window surface; the primary task is to keep the tool aligned and in contact, and the secondary task is to provide surface coverage while maintaining a comfortable arm position. Several variants of this hierarchical approach to redundancy have been used in robotics (Khatib et al., 2008). This core concept has been applied to task sequencing (Mansard and Chaumette, 2007), task prioritization (Baerlocher and Boulic, 2004), and hierarchical quadratic programming (Escande et al., 2014; Herzog et al., 2015). These methods minimize a cost function subject to known constraints. However, they suffer from the curse of dimensionality and are typically unsuitable for real-time applications in high dimensions.
To circumvent this problem, one might attempt to learn a policy, a mapping from states to actions, that encodes behavior consistent with the set of constraints, instead of continuously calculating constraint-consistent actions. This mapping can be learned from data captured during demonstrations, consisting of human or robot motions. This approach falls under the category of imitation learning or learning by demonstration (Argall et al., 2009). One straightforward way to learn behaviors from this is through direct policy learning (DPL) (Alissandrakis et al., 2007; Calinon and Billard, 2007; Schaal et al., 2003). For instance, Gams et al. (2014) proposes to use a modification of dynamic movement primitives (Ijspeert et al., 2003) so that limits are considered at velocity and acceleration levels to tune the interaction forces of a robotic system with an object. Although DPL is well known and widely used, other approaches related to the problem of learning by demonstration involve learning a “filtered” trajectory over the demonstrations and combine operational and configuration tasks within a probabilistic framework. In particular, Calinon (2016) and Hussein et al. (2015) propose to use a Gaussian mixture model or Gaussian mixture regression to learn a parametrized trajectory with known tasks constraints, while Paraschos et al. (2017) propose that learning the prioritization of tasks can also enable the estimation of “soft” constraints and a prioritization between them.
In this paper, the problem of learning by demonstration will be understood as an action mapping in a DPL context (Alissandrakis et al., 2007; Schaal et al., 2003); however, it is well known that this method suffers from poor generalization (Argall et al., 2009) under varying unknown constraints. On the contrary, constraint-aware learning, in which the task or constraint is learned first and a null-space policy common to all tasks is learned separately using conventional methods has been shown to provide significant improvements (Armesto et al., 2017a,b; Lin et al., 2015; Towell et al., 2010). The idea behind constraint-aware methods is that the raw input data can be projected onto the null space of the task or constraint once it has been learned. We can then use other learning methods for the unconstrained policy, which is assumed to be the same across all demonstrations (Lin et al., 2015). Such an approach falls under the categorization of “hard” constraint methods (Paraschos et al., 2017). Lin et al. (2015). Lin et al. (2015) present a method for estimating the null-space projection matrix. The main drawback of their approach is that the estimation is performed by solving a non-convex optimization problem using a spherical representation. This often leads to long computation times and decreased performance (Armesto et al., 2017a). In this paper, we present a closed-form solution of this problem.
The results presented in this paper are, indeed, an extension of (Armesto et al., 2017b), in which we provide a more detailed explanation and justification of the proposed method. In particular, we consider a DPL problem, which might be difficult to learn, by making a reasonable separation into two subproblems: learning the constraint and learning the null-space policy, where both subproblems have closed-form solutions with linear parametrization. This improvement allows us to estimate null-space projection matrixes from data of different tasks, which can be used for learning a null-space policy by observing multiple projections of such a policy. Howard and Vijayakumar (2007) later use this estimate to learn the null-space policy. One of the key differences between our approach and that presented by Lin et al. (2015) is that in this paper we propose learning the constraint equation by minimizing the error in the task-space, while Lin et al. (2015) perform the minimization on an error defined in the null space. Secondly, Lin et al. (2015) impose the assumption of having access to the null space, while here we can deal with data containing both task and null-space components. In addition to this, we split the raw observation into task and null-space components in a more efficient way than the method proposed by Towell et al. (2010). Lin et al. (2017) also efficiently split the learning method into task and null-space components, but for lower-dimensional systems, unlike our method. To estimate the null-space policy, we propose to use locally weighted models (Atkeson et al., 1997); however, the method used to model such a policy is not that relevant and other well-known approaches in DPL might also be used (Calinon, 2016; Hussein et al., 2015; Ijspeert et al., 2003). We show that the learned policy can then be executed
The contributions of this paper are:
We formulate the constrained learning problem as a joint optimization over both constraint and policy parameters. Since this is a difficult problem to solve in practice, we then propose an alternate formulation, which splits this optimization into two subproblems, which we solve sequentially.
We formulate a closed-form solution of these subproblems by making them linear in their respective parameters.
We extend the theoretical work of hierarchically constrained optimization presented by Escande et al. (2014) and adapt it for the domain of constraint-aware learning from demonstration.
We develop a metric for computing the similarity of estimated constraints.
We show that our framework can employ generic models to represent the constraints and policies with no prior knowledge. We then show how application-specific knowledge can be exploited by using domain-specific regressors with physical meaning.
We validate our method through experiments by learning a circular wiping policy from human demonstrations on planar surfaces.
We define a surface alignment task using a force sensor, allowing us to perform wiping on curved surfaces based on the previously learned policy.
2. Preliminaries and problem statement
In many robotics applications, we can decompose the motion policy into a hierarchy of sub-policies. For instance, in such applications as welding, ironing, wiping, writing, etc., we can split the overall policy into a primary task of maintaining the contact with the working surface, and a secondary task of tracing a specific trajectory along the surface. Additionally, we might even specify a third task of avoiding joint limits, or minimizing deviations from a comfortable pose. In this case, a task from a higher level in the hierarchy acts as a constraint on the lower-level policies. In learning from demonstration, we assume that we have been given demonstrations of the kind of motion that we want to describe by a mathematical model.
Let us assume a system with control input

where

where


Note that, by definition,

In a DPL context, an action mapping involves searching for optimal parameters

where the norm is defined, given

and
Calinon and Billard (2007) proposed to solve this problem using a method they called DPL. This is a special case of our formulation that ignores the task hierarchy, pursuing a direct optimization of equation (6).
However, such a direct approach cannot “distinguish” between the actions needed to achieve the primary task (constraint satisfaction) and the actions needed to carry out the secondary task (for instance, tracing a trajectory in the constraint space). Furthermore, the primary task can often be achieved using inverse kinematics or reactively using force or visual feedback. This shifts the focus onto learning a policy that is aware of the acting constraint imposed by the primary task. This idea is implicit in the separation into task-space and null-space components in equations (3) and (4). The inability of DPL to separate such components in the learning process motivates the main goal of this paper: setting up a suitable parametrization and formulating an optimization problem such that the aforementioned constraint-aware learning is possible.
In a generic scenario, the problem is solved using a training dataset with samples of states and controls. However, the dataset might contain data coming from a mixture of different constraints, tasks, and policies. Our problem statement encompasses all these possible situations if the dataset is extended by encoding the different constraints and tasks onto pieces of time-varying information. This additional information classifies the training dataset according to the relevant task or constraint information, to produce an estimate of the null-space policy
3. Constraint-aware policy learning
When learning the policy
Given this assumption, the aim is to learn a null-space policy
Learning is usually carried out by parametrized approximators, which are continuous functions. For instance, universal function approximators, such as the ones proposed by Hornik et al. (1989) provide progressively more accurate approximations as the number of parameters, neurons, etc., increases. Let us assume that the set of constraint matrix, task, and null-space policy can be parametrized as



where we can consider the parameters of the DPL problem in equation (6) to be
Note that the actual explicit expression of equations (7) to (9) would depend on some problem-dependent information available at time

and

with
From this task or null-space parametrization, given a set of demonstrations, the DPL can be reformulated as the “

i.e., minimizing

Of course, the DPL cost (equation (6)) may be directly optimized with a suitable parametrization. However, the assumption that the demonstrations are provided under the previously discussed constraints suggests that equation (10) might be a better parametrization than a generic “constraint-unaware” parametrization of
In practice, this problem is difficult to solve because, even if the approximators (equation (7) to (9)) were linear in their parameters, the presence of pseudoinverses in equation (11) introduces a complex relation with respect to



The proof of this lemma can be found in Appendix A.
3.1. Sequential optimization
We can approximately solve the constraint-parametrized learning problem sequentially, first minimizing
The advantage of this approach is that
3.2. Closed-form constraint estimation
In this section, we define a method for solving the minimization of equation (13). Hence, it will allow us to estimate the constraint matrix and the associated null-space projection matrix, which will be used to split the action observations into task-space and null-space components.
Note that equation (13) only depends on parameters


where
Let us, for convenience, define

where
We now want to compute the parameters
The proof of this lemma appears in Appendix B.
Now, recall that a “demonstration” will be a set of controls at different time instants from, say

subject to

However, depending on the chosen parametrization, this constraint might be difficult to satisfy. Therefore, we propose to approximate

Now, applying Lemma 2, we can obtain the optimal values for
Note that, in practice, these integrals would be evaluated via a sum of the available data samples, i.e., if we have

where
In theory, if several constraints are fulfilled with no error, then the (generalized) eigenvalue zero would have a multi-dimensional subspace of eigenvectors; thus, an orthogonal basis of such eigenvectors would form the rows of
Note that, in this noisy case, the overall result of this first phase of the learning methodology is a matrix
If

generalizing the work of Armesto et al. (2017b). Actually, if the number of constraints is known in advance, it is easy to discriminate between situations where there is an over- or under-parametrization by computing the number of significantly smaller eigenvalues. Thus, if the number of significant eigenvalues is smaller than the expected number of constraints, it implies that there is an under-parametrization and more regressors should be added. On the contrary, if the number of significantly smaller eigenvalues is greater than the number of expected constraints, either the problem is over-parametrized or the data fulfill more constraints than originally assumed.
3.3. Learning the null-space policy
At this stage, once the minimization of


This can be interpreted as an estimate of the “true” null-space and task-space components (equations (3) and (4)), if the relevant eigenvalues are close to zero. Note also that
Now, we can estimate the optimal value of

Since
3.4. Learning with locally weighted models
There are several ways in which we can model the policy
Based on this idea,

where each local model
For each local model, we use a regressor vector

where
Actually, note that the local-model structure can, too, be used to form the regressors for
If we have prior information about the policy we are attempting to learn, we can choose specific regressors if we believe that they will represent the task better. This may improve accuracy and reduce the number of parameters, compared with other options. For instance, a task involving tracing end-effector trajectories may use the rows of the end-effector Jacobian as regressors. The choice of suitable regressors is application-dependent. In our case study, we discuss the selection of regressors suitable for learning policies that are constrained to a planar surface.
4. Learning planar-constrained policies
Defining the appropriate set of regressors can be difficult without prior knowledge about the application. In this section, we propose to exploit the prior knowledge of the application by using Jacobians of the end effector as the main regressors for learning both the constraint and the null-space policy. This will allow us to define exact models for tasks demonstrated on planar surfaces. However, once the model has been trained, the policy can be executed on non-planar surfaces as long as we can guarantee that the end effector will stay aligned with the surface (e.g. by using force feedback). This parametrization is useful for applications where the robot is constrained by a surface on which the task is being performed, such as wiping, dusting, sweeping, scratching, or writing. In all these examples, a constraint could be defined in terms of minimizing the distance from the surface and the misalignment between the surface normal and the orientation of the robot’s tool (see Figure 2). The null space of this task would be any motion of the robot’s tool on the surface, i.e., with speed of movements tangential to the surface.

Robot performing constrained task on curved surface. The robot uses a force sensor and a soft material (sponge) mounted at the end effector as a tool. The interaction of the wiping tool and the surface causes a friction force
4.1. Learning the primary task and the constraint
Let us consider a robot with some tool at its end, whose position in three-dimensional space will be denoted

where

Two-dimensional illustration of a robot performing the demonstrated motion on a flat surface.
In differential kinematics (Siciliano et al., 2009), the state of a robot can be described by the joint velocity,

where
From equations (28) and (27), we can select the following regressors


where the primary-task controller will attempt to achieve a linear time-invariant stable closed loop, so the position and alignment error converge to zero. as required by the primary task. Indeed, note that

and thus the choice of
In theory, the regressors for
Regarding regressors
4.2. Learning the null-space policy
We will now propose a specialized structure for the null-space policy
Recall that the primary task attempts to align the tool orientation with the surface (constraining two degrees of freedom) and maintain the contact (constraining one more degree of freedom). This implies a task that constrains a total of three of the degrees of freedom of the robot. We can reasonably assume that any motion along the surface will be part of the null space of the primary task, with the remaining degrees of freedom available. We can now choose a suitable parametrization of the null-space policy
Since the tool’s orientation is constrained by the primary task, only the position trajectory

which computes the tool’s speed relative to this reference frame. The estimated parameters

which will, basically, be coincident with equation (32) unless heavy misalignment has occurred during the demonstration. With this assumption, we will define the tool speed in the coordinate system of the plane as

Note that these tool Jacobians consider only the tool’s position and not its orientation. Additionally,
If the robot has five degrees of freedom, this choice of
To account for this redundancy, we complement the secondary task description

where matrix
Let us denote


The proof of this lemma appears in Appendix C.
Note that, in the case where

If we choose to parametrize the regressors
4.2.1. Suitable regressors for κ
Recall that the components of
For instance, let us assume that the robot is tracking a curve

with, say, constant tangential speed
As an example, if
4.2.2. Suitable regressors for γ
The quantities

so that the matrix
Additionally, we can exploit the locally weighted models on top of each of these regressors to model more complex policies. We have used these models in our experiments to demonstrate that they are suitable for the modeling wiping task.
5. Task generalization using force sensor
We show the utility of learning surface-constrained policies through generalization to a novel task. In many scenarios, such as in the train-cleaning application (Figure 1), it might be hard to obtain a precise model of the surface, owing to outdoor lighting conditions, different surface materials, and the surface dimensions. Thus, in practical applications, the constraint surface might not be known. Therefore, we aim to redefine the surface alignment task using, for instance, a force or torque sensor.
To guarantee the alignment between the robot end effector and the curved surface, the robot must exert some contact force on the surface and adjust the end-effector orientation to be perpendicular to that surface. As shown in Figure 2, this alignment corresponds to having the end-effector local

where
In this scenario, the Jacobian of this error with respect to the tool frame is defined as

where
Our task is derived from a controller trying to achieve the closed-loop dynamics
It is important to remark that the error vector (equation (40)) used in wiping a non-flat surface with force feedback is different from the error used during the demonstration on the flat surfaces (equation (27)). Despite this, the learned policy

with
In real-time operation,

In this particular case of force-sensor feedback, we use the following regressors

6. Examples
6.1. Learning a circular policy of a particle in the Cartesian space
We first introduce a simple example that contrasts our CAPL with a DPL, illustrating the problems arising from data inconsistency.
Consider a particle moving in a three-dimensional Cartesian space at constant speed—the norm of the velocity vector—and at constant distance of 1 m from the origin. When restricting the motion of this particle to a plane intersecting the origin, the resulting trajectory is a circumference centered at the origin. Our aim is to learn this circular motion for any plane intersecting the origin, provided a set of trajectories of the particle constrained to different planes. We captured two demonstration trajectories of this particle when constrained to move in two planes with an inclination of

Two circular trajectories of a three-dimensional particle moving in two different planes. Plot of the training data and the result of policy execution learned through DPL and CAPL, starting at the same initial position
For this problem, we define the state
6.1.1. CAPL
Given that the constraint is independent of the state space, we define the regressors for the constraint matrix

6.1.2. DPL
For this method, we first used the same policy function (equation (45)).
Let us now compare the performance of both approaches. The DPL is biased because of the inconsistent data at intersection points. For this particular example, different actions
6.2. Learning a wiping policy
We have reproduced conditions outlined in Armesto et al. (2017a) to simulate a kinematic seven-degrees-of-freedom Kuka LBR IIWA R800 robot. We have generated a circular wiping motion together with a joint limit avoidance policy affecting the first, third, and seventh joints of the robot, as described in Armesto et al. (2017a). Both these ground-truth policies have an influence on the motion in the null space of the primary task that aligns the tool with the wiping of a planar surface. A single trajectory of a wiping motion with a duration of 1.5 s sampled at 0.01 s intervals has been collected with a randomly oriented planar surface placed to be perpendicular to the tool of the robot. The robot’s end effector is therefore initially aligned with the surface and in contact with the surface. This ensures that alignment errors are initially close to zero. We can therefore use the singular-value decomposition approach to estimate the constraint parameters. During the data generation, we have artificially added Gaussian noise with a standard deviation of 5% of the joint’s physical range on each joint’s velocity, to emulate collection of noisy (non-perfect) data from a human operator.
The proposed method provides an estimate of
Figure 5 shows the (simulated) measured velocities in the tool’s plane
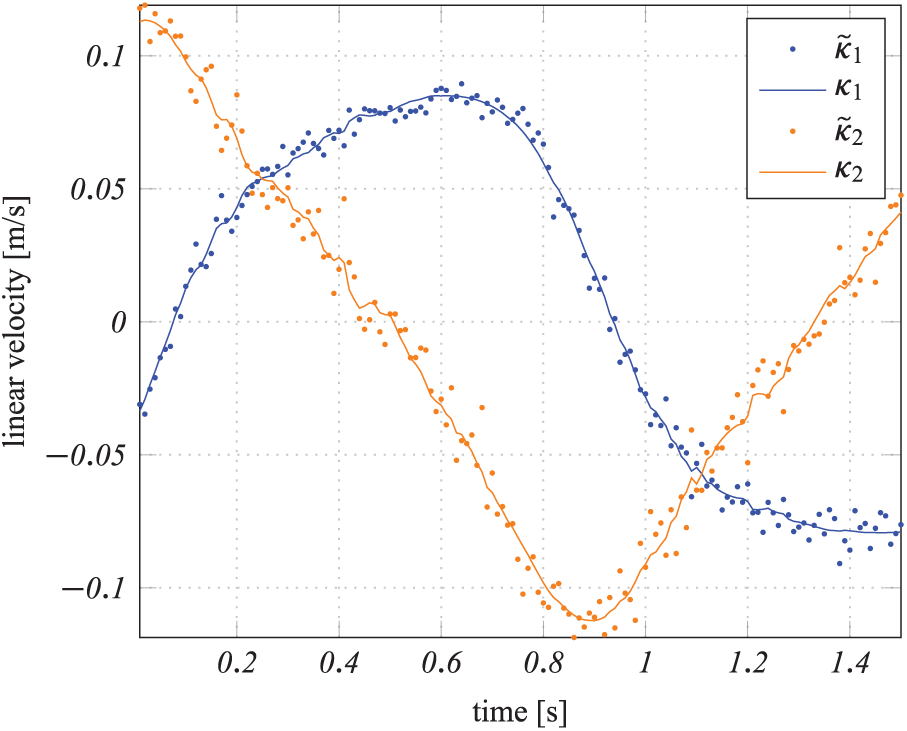
Planar wiping policy estimation. Estimated planar wiping policy

Joint limit avoidance policy estimation. Estimated joint limit avoidance policy

Unconstrained policy estimation. Estimated unconstrained policy
7. Experimental setup
7.1. Testing with real data and a force sensor
In our experiments, we use the seven-degrees-of-freedom Kuka LWR3 robot with an ATI industrial automation Gamma force and torque sensor attached at the end effector, as shown in Figure 8. The force sensor retrieves a six-dimensional wrench vector expressed in the sensor frame. Therefore, we compute the torque at the contact point by transforming the wrench through a distance

Kuka LWR 3 robotic arm, equipped with a force and torque sensor, wiping a curved surface.
We recorded a dataset of wiping trajectories demonstrated by a human being, as shown in Figure 9. The dataset contains 12 trajectories, each on a surface at a different orientation (four of which are shown in Figure 10). Each demonstration involved several circles with the tool of the robot, giving approximately 2000 data points 3 (using a sampling rate of 100 Hz). The demonstrated data were only minimally cropped to ensure that data contained only poses where the tool was in contact with the surface and moving along the demonstrated trajectory.

Demonstration of a circular wiping trajectory on a flat surface. The demonstration was repeated on 12 surfaces of different orientations.

Learning by demonstration. Four of the twelve wiping trajectories from human demonstration (green), and closed-loop policy validation using the respective flat surface orientation and initial position (blue).
We used this dataset to first learn the different constraint matrixes, by parametrizing them as a linear combination of regressors and functions of state, and by applying the estimation method described in Section 3.2. The regressors for each constraint matrix are these from equation (29). For the policy
Figure 10 shows the robot’s end-effector trajectory, corresponding to the execution of the estimated null-space policy for the same constraint (surface inclination) of the demonstrations, as well as the respective end-effector position corresponding to the data. Table 1 shows the result of computing the costs
Costs,

Furthermore, we have also validated the learned policy on a non-flat surface, as shown in Figure 8, demonstrating that the policy, trained from human demonstrations on flat surfaces, generalizes to both flat and curved surfaces. The resulting wiping motion is depicted in Figure 11. Note that we have demonstrated the wiping motion exclusively on flat surfaces; therefore, this shows two aspects of generalization: (I) from a surface alignment task to a force alignment task and (II) from flat surfaces to a curved surface. See Armesto et al. (2017c) for video recordings of the policy generalization to a curved surface. In many practical cases, training with flat surfaces will be easier for the demonstrator (for instance, to align the tool properly with the surface), resulting in a dataset with demonstrations in which

A wiping policy has been trained from human demonstrations on flat surfaces (without using the force sensor); the policy generalizes to non-flat surfaces using a force-sensor-based task to align the tool dynamically.
7.2. Constraint similarity analysis
In all experiments so far, we have assumed that the demonstrator provides a set of sub-datasets
The aim now is to analyse how similar or distinct these sub-datasets are from one another, regarding the estimated underlying constraint, by using the same cost metric proposed for the constraint estimation. Moreover, we consider this analysis for the case of a single full dataset containing data originating from different constraints, to help us in identifying the transition regions. The experiments in this section are meant to provide an additional analysis of the training data, highlighting the difference between data obtained for an unconstrained motion or a motion subject to the same constraint and data collected under different constraints.
To compare the sub-datasets, we simply compute the cost

where we index the time
For the experimental data used in the previous subsection, we manually selected the

Kuka lightweight robotic arm end effector. Cartesian positions for a full unseparated dataset (blue), subject to different constraints in the form of flat surface inclinations. Overlapping are the manually separated sub-datasets, showing that a full unprocessed dataset contains transition regions with data points that are discarded before the learning process.
This manual separation was achieved by visually inspecting the data and selecting the initial and final indices of the data points for each sub-dataset. However, for larger full datasets this figure might become cluttered, making it difficult even to verify that some demonstrations correspond to very similar constraints. This suggests that we could use
Given an unprocessed dataset, we must conduct a similarity analysis for groups of data points, regardless of whether they correspond to the same constraint or not. One approach is to select a set of consecutive data points that represent a window within the full dataset. We then compute the parameters for that window
By repeating this process for the full dataset, we then obtain a matrix such as the one shown in Figure 13. This matrix corresponds to the data shown in Figure 12. We have empirically chosen a window size of 400 samples (corresponding to 8 s for a sampling frequency of 50 Hz) and increments of 50 samples (1 s). In Figure 13, we also overlap boxes showing the manual separation provided by the expert. There are at least two groups of windows (around indices 120 and 150) that could be confused with demonstrations, given that they produce squares of small

Normalized
8. Conclusion
This paper presents a new method for learning, from demonstration, policies that lie in the null space of a primary task, i.e. subject to some constraint. We introduce the term “constraint-aware policy learning” as a reformulation of the direct policy learning method, where the policy appropriately parametrizes the constraint. Additionally, we discuss the conditions for which this “constraint-aware policy learning” can be split into two optimization problems: constraint estimation preceded by null-space policy estimation.
The main advantage of this approach, compared with classic direct policy learning, is its ability to learn a policy consistent with the constraint. To demonstrate this point, we used different tasks and constraints in our experimental demonstration with the real Kuka lightweight arm. In this case, while recording the training data, the human demonstrator provides the task, whereas in the validation stage we use a force-based task to adapt and align the tool to an unknown surface.
While the null-space policy can be parametrized with locally weighted models, as discussed in this paper, or any other more generic functions, in the example of learning a wiping motion we choose to take advantage of our knowledge of this specific task by incorporating more specialized regressors. This decreases the number of parameters that the algorithm must learn, decreasing the required number of demonstrations. Certainly, a clever choice of regressors can—as in our case—greatly improve the results or even turn the learning exercise into a trivial problem. However, what this framework provides is a way of encapsulating all the specifics and domain knowledge in the chosen regressors, and not in the learning algorithm itself.
Moreover, we consider the case of a null-space policy that, instead of having the full dimension of the system actions, can be decomposed, by assumption, into a set of lower-dimensional policies. For this case, we propose an alternative reformulation for estimating these lower-dimensional policies, provided the respective regressors are supplied.
However, to learn a generalizable null-space policy, we must somehow guarantee that the training datasets provide enough variability of constraints. We provide a means of comparing the datasets, regarding their underlying constraint, by using the same metric used in the constraint estimation. This involves building a similarity matrix by computing the estimation residual of a sub-dataset, using the estimated parameters from the other sub-datasets. Furthermore, besides allowing us to identify similar constraints between different sub-datasets, this similarity matrix allows us to identify different constraints within the same dataset, by running the samemetric but over different windows of data. This can be a valuable tool for helping to identify the beginning and end of a demonstration.
In our future work, we intend to exploit more challenging application domains, as well as learning constrained tasks for dynamic systems. We would also like to integrate the constraint-aware learning framework with other policy learning methods to guarantee some desired properties for the null-space policy.