
Abstract
Keywords
Introduction
The basic concept of the Internet of things (IoT) is that various things or objects are interconnected with each other and achieve their common purpose. 1 Various things or objects can be interconnected with addressing wireless communication, such as radio frequency identification (RFID) or near-field communication (NFC).2,3 For example, in the logistics domain, researchers examined the reduction of logistics by addressing the purchasing of materials, transportation, and storage using the IoT. 4 In other domains, such as composite structures, researchers address sensor networks to model methods.5–7 People also considered of efficient methods that analyze personal information, such as social or historical activities on the web using smart devices in the IoT. 8
As IoT is recognized as a new paradigm of modern wireless communication in several fields, 2 research on social IoT is actively underway to magnify the great potential. A variety of devices are connected, communicated, and shared, and actions can be determined by the information. 9 IoT technologies send and share information among various devices utilizing wireless sensor networks. To establish IoT environments, we first need to build reliable wireless sensor networks. To build the networks, we can utilize methods for detecting selective forwarding attacks as well as robust methods for identifying outliers and data gaps.10,11
There are studies for effectively building wireless sensor networks as well as reliability. Chi and Chen 12 have proposed the feasible method for physical communication and link optimization in wireless communication. Liu et al. 13 have proposed the subtractive clustering algorithm to select cluster heads and build optimal clusters.
To provide various IoT services, we apply smart devices, such as mobile, and concept of social relationships to IoT.14,15 In the case of IoT using social concepts, we can use recommendation services by addressing data from IoT devices. 16 We can also discover the social relationships among physical objects utilizing the spatial–temporal attributes for the devices. 17 In addition, there is research applying social concepts to IoT for vehicles. 18
There is a trade-off between scalability and reliability in the social IoT. 19 Namely, if we build a social network based on more devices, the reliability of the data is compromised. Because of this reason, the accuracy and reliability of the information are considered as the important factors in social IoT. Each factor is an act of criteria to determine the decision. We assumed that a decision support system in social IoT could produce more reliable results by adopting the research of the recommendation system on the web. Therefore, we first introduce recommender systems on the web and propose a trust-aware recommender system suitable for social IoT.
As the volume of online information grows rapidly, huge amounts of information lead information inefficiency in information retrieval. As a solution to reduce the information overload problems, “recommender system” has become an important research topic. Recommender systems analyze the preference of users with users’ past record or attributes and then provide personalized suggestions that users might be interested in. Depending on the various information channels, such as smartphones and wearable devices, recommender systems have extended application area into music, product, video, and social connections. 20 Initial recommender systems are focused on utilizing raw data from database, including users’ ratings and demographic features, and properties of items to predict the preference of users.21–24
The conventional recommender systems are divided into three types: content-based filtering, collaborative filtering (CF), and hybrid recommender systems.25–30 Content-based recommender systems are based on calculating item similarity with properties. CF-based systems recommend items that other users with similar preferences liked in the past. Hybrid recommender systems combine the techniques of content-based filtering and the CF. However, such conventional recommender systems suffer from problems, such as data sparsity, cold start, and opinion spam problems.31,32
Trust-aware recommender systems reduce the problems in conventional recommender systems by adapting the concept of the social network service into recommender systems.33–37 Trust in recommender systems means one’s belief toward the ability of others in providing valuable ratings.38–40 Information representing social interaction among users is the main source to find other users having similar tendencies, which is under the assumption that user behaviors are affected by other users whom they trust. 41
In trust-aware recommender systems, there are two types of trust: explicit and implicit trust.42,43 Explicit trust is pre-established social links among users in social network and it is defined directly by users. Explicit trust-aware recommender systems provide a function for users to mark other users whom they trust. Explicit trust information is separately saved in user–user trust matrix database. However, implicit trust is not specified by users but inferred from a user–item rating matrix.
While explicit trust information reduces the shortcomings of traditional recommender systems, there are still drawbacks to the way of incorporating explicit trust into recommender systems.42,44,45 First of all, the lower the density of the dataset, the more likely trust sparsity issues arise which leads to degrade the prediction performance. The user–user trust matrix is generally less dense than user–item rating matrices because users tend to be more reluctant to provide personal information to systems. Second, most recommender systems in the real world do not have features for explicit trust. Third, explicit trust datasets used in research are based on research-oriented datasets that follow a binary form to protect privacy. Finally, there is a trust tendency problem where each user expresses degree of trust at different levels.
Since such problems degrade the quality of recommendations, it becomes an important matter to develop implicit trust methods to reflect properties of trust: transitivity, asymmetry, dynamicity, and context dependence. 42 Trust transitivity means that trust must be propagated.46,47 Trust asymmetry is that the structure of a trust network should be a directional and weighted graph like in the real world. Trust dynamicity is that the level and the state of trust change over time. Context dependence means that degrees of trust on others may vary depending on areas. However, current implicit trust metrics only satisfy transitivity. Therefore, we configure an asymmetric implicit trust network from user–item rating matrix and then additionally infer latent trust relations utilizing trust propagation property. The proposed method requires only user–item rating dataset and it is adaptable to most recommender systems in the real world. Also, we reduce the trust tendency problem by considering the general assessment of each item in calculating trust values between two users.
We evaluate our method with the fivefold cross validation 42 and compare our method with three existing methods: (1) CF with a threshold of Pearson’s correlation coefficient (PCC), (2) Shambour’s implicit trust method, and (3) Moradi and Ahmadian’s 48 reliability-based recommendation method. Through experiments, the proposed method enables relatively high accuracy and a wide range compared to the existing recommendation studies. The study improves the existing implicit trust-aware recommender system without additional trust databases.
In section “Background,” we briefly review the background and the related works on the trust-aware recommender systems. In section “Relative-trust recommendation models,” we introduce our recommendation methods. Then, we compare our proposed method with three other related methods using FilmTrust in section “Experiments.” Finally, we discuss the conclusion and the future work in section “Conclusion.”
Background
Trust-aware recommender systems
Trust-aware recommender systems have a network of trust relationship among users like in social networking sites (SNS). When user A registers user B into a trust list, user A becomes a “truster” and user B is a “trustee” in the trust relationship. A review is a main factor when a “truster” decides whether to trust on “trustee” or not. A trust network is described as a weighted directed graph
In recommender systems, trust means one’s belief toward the ability of others in providing valuable ratings.49,50 Trust network has the following properties: asymmetry, transitivity, dynamicity, and context dependence.42,44,51 Asymmetry is that a trust value
There are two general approaches to assort trust: explicit and implicit trust. Explicit trust is a pre-established social link between users in a social network and it is explicitly defined by users.42,43 Explicit trust methods configure explicit trust networks as directional and unweighted graphs because explicit trust dataset for research is formed in binary. A user–user matrix contains sets of user IDs of truster and trustee, and the trust values. A trust relation exists only when trust value
An example of trust dataset.


An example of an explicit trust network based on Table 1.
However, implicit trust is inferred from the rating dataset. An implicit trust network is denoted as a weighted and undirected graph. If two users have ratings on common items, there is likely to be a latent implicit trust statement between two users.42,52,53 The concept of implicit trust is hardly distinguishable from user-based recommender system. 54
Table 2 and Figure 2 show an example of an implicit trust network inferred from rating dataset. Recommender systems compute implicit trust values utilizing the user–item rating matrix. In Table 2, trust relation
An example of rating dataset.


An example of an implicit trust network based on Table 2.
Related works
Implicit trust metrics reduce shortcomings in explicit trust metrics.42,44,55 Guo et al. 42 review the existing methods for implicit trust56–59 and conduct evaluations. Fazeli et al. 44 incorporate the same methods, which Guo et al. 42 compared, to the matrix factorization techniques. The implicit trust metrics in both studies satisfy the only transitivity among trust properties.42,44 Wang et al. 55 employ implicit trust relationships to overcome the disadvantage of explicit trust relationships. They propose two neural network models addressing both implicit and explicit trust relationships.
Reliability measurements are methods to filter unnecessary information that is expected to cause a negative effect on the performance of recommendations.48,54 Hernando et al. 54 propose reliability measurements for CF. The proposed reliability measurements filter unnecessary neighbors before predicting ratings. However, it is unadaptable for recommender systems having explicit trust networks. So, Moradi and Ahmadian 48 improve reliability measurements suitable for recommender systems having explicit trust networks. Wang et al. 55
Even though explicit trust information improves the performance of traditional recommender systems, there are still limitations in explicit metrics.42,44,45 All the techniques for explicit trust are available only when recommender systems have the explicit trust dataset. However, most recommendation systems in the real world do not have additional explicit trust datasets.
Also, explicit trust values of the publicly available dataset are scaled in a different way than real-world recommender systems. Although trust value in real-world recommender systems is scaled with real numbers, trust value in most publicly available datasets is binary because of user privacy. Moreover, there is a tendency issue that each user has a different standard to express the degree of trust. In addition, trust sparsity problem is more serious than in rating information because it is difficult to encourage users to rate trust values of others into systems. It becomes more important to improve implicit trust methods to overcome the disadvantages found in existing methods for explicit trust network. However, current implicit trust metrics also have problems that these metrics only satisfy transitivity among properties of trust. The structure of implicit trust network configured by existing metrics is a symmetry graph, which is unrealistic. Moreover, there is no consideration of dynamicity or context dependence. Although implicit trust value decreases trust tendency problem more than explicit trust value, implicit trust value is also risky on trust tendency problem because of no consideration on the general assessment of each item.
We expect the performance of recommendations to be improved if implicit trust further satisfies trust properties. Therefore, our proposed method configures trust implicit network as an asymmetric structure like in the real world. Also, we reduce trust tendency problem by considering the general assessment of items.
Relative-trust recommendation models
We follow the definition of trust as one’s belief toward the ability of others in providing valuable ratings.49,50 Trust-aware recommender systems presume that there is high correlation between trust and similarity of preference. Therefore, the core procedure is to identify neighbors who might have similar preference.42,44
Our proposed method is based on implicit measurement with following reasons. First of all, implicit trust is more easily obtained in recommender systems than explicit trust. Implicit trust value is calculated from item–user rating matrix and explicit trust value is obtained from user–user trust matrix. However, user–user trust matrix is not commonly used in recommender systems yet. It is because additional functions and datasets for user–user trust datasets require more memory space and computation. Also, users tend to be reluctant to provide their personal information to the system.
Second, the density of the dataset is important than the amount. When density of dataset is high, there are many single users or items with historical data. However, low-density datasets have many single users or items with little or no historical data. In general, user–item dataset is denser than user–user dataset. Therefore, our method configures a user–user network from user–item datasets and predicts users’ preferences for reducing trust sparsity.
Third, implicit trust is more directly related with users’ purchase behavior. When a user A decides to mark to trust another user B, the user A may trust user B for IT matters, but not fashion. Then, the explicit trust value becomes a latent risk factor to produce prediction error when predicting user A’s preference. However, an explicit trust value is not distinguishable about the contextual reason why user A decides to trust user B. However, there are data sparsity and tendency problems even in implicit trust metrics. Our proposed metrics suggest three following steps to alleviate such problems in implicit trust measurements:
Figure 3 shows the overall process of the proposed method.

Overall process of the proposed method.
Constructing asymmetric trust networks
The first step is to calculate the relative similarity between the truster and trustee using the user–item rating dataset. The proposed implicit trust value has two main differences from existing methods. First, we utilize the average rating of an item as an indicator representing the general assessment of each item. Existing methods42,44 derive implicit trust values with the similarity of their ratings and the average rating of a user is a representative of personal tendency. Therefore, when a user A givers the best rating for all the purchased items, the user A is categorized as a generous consumer. However, it leads to false predictions in the case that he gave generous items because he purchased only good quality items, not because he is a generous customer. In the situation, we cannot guarantee that he is willing to give the best rating again for the next purchase. Thus, if both users give the highest rating even to the worst rated items in the past, then implicit trust between the two users should be weighted more.
Second, our proposed method calculates implicit trust value as relative and asymmetry relation. We argue that the quality of products is the primary factor to consider the rating tendency of each user, not the average rating. Implicit trust value between two users is symmetry following to existing implicit trust methods.42,44 That means, if there is a trust relationship between two users, both users must believe that other users provide valuable ratings to the same extent. Considering trust relationships, in reality, such symmetry trust relations hardly exist.
In the sense, we concentrate on the phenomenon that consumers review other’s ratings to pre-estimate the quality of an item before making orders. Our proposed method first derive relative similarity value
This step uses equation (1)

where
Then, we total up a set of

where
Table 3 is an example of rating dataset to help the explanation above. Following to existing implicit trust methods42,44,
An example of rating dataset.

Inferring latent trust networks
After constructing an asymmetric trust network, we identify latent trust relations through the trust propagation metric. Propagation metrics infer latent relationships between users and alleviates the data sparsity problem. However, existing propagation methods are adaptable only for a directional and unweighted graph with explicit trust information or a unidirectional graph with implicit trust values.42,44 Since our method configures a trust network as a directional and weighted graph, existing trust propagation is not adoptable. So, we transform the existing propagation metric
50
to be suitable for our trust network with calculating the final relative similarity

An example of trust propagation.
Even though there is no directional implicit trust value from user
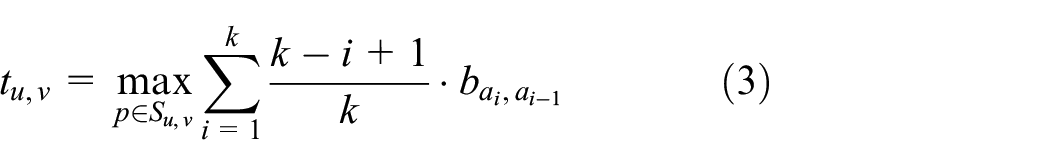
where
Since the relative similarity value
We consider that
Prediction
Then, we predict ratings of unseen items for a target user through Resnick’s prediction formula.
60
The predicted rating

where
We select
Experiments
Dataset
We analyze FilmTrust dataset crawled by Guo et al.42,61,62 FilmTrust is a movie recommender website where users evaluate movies and also add other users to the trust list. The user–item rating data consist of the total 35,497 ratings of 2071 different items by 1508 users. The trust network data contain 1853 directed trust edge information from 609 trusters to 732 trustees without trust weights. The summary of the FilmTrust dataset is in Tables 4 and 5.
Rating dataset.

Trust dataset.

We verify the performance of the proposed method with the fivefold cross validation.42,44 We evaluate the accuracy of rating prediction with the following metrics—mean absolute error (MAE) and root mean square deviation (RMSE). We also utilize rating coverage (RC) and user coverage (UC) to test the available coverage of rating prediction.
MAE is the average difference between predicted rates and real rates, and the definition of MAE for user

where
RMSE shows the contributions of the absolute errors between the predicted and actual rates. Low RMSE value means positive high accuracy of recommendation and the definition is as follows

where
We also evaluate UC. UC measure defines the portion of users who are able to have at least one predictable rating with the proposed method. UC equals the number of predictable users divided by the total number of users in the test set. High UC value means the high performance of recommendation methods. When UC value is 1, the evaluated method can predict at least one item for all users in systems within acceptable errors.
Result and analysis
To evaluate the proposed method, we calculate the accuracy of rating prediction and predictable RC with the following existing methods:
CF with threshold
Shambour’s method
Moradi and Ahmadian’s reliability-based recommendation method
CF based on PCC with threshold shows the worst performance in the evaluation of implicit trust methods. 42 Shambour’s method shows the best performances in the evaluation of implicit trust methods. 42 Reliability-based recommendation method by Moradi and Ahmadian 48 shows the best performance among trust-aware recommender systems using explicit and implicit trust statements.
We set threshold
Figures 5 and 6 show the comparison results of the proposed method with other methods. As the result shown in Figure 5, the performance of the proposed method outperforms other methods. Also, explicit trust statements in the proposed method negatively effect on the performance when the density of trust statements is sparse. Since FilmTrust dataset is dense compared with other datasets, the difference among methods is relatively small.

MAE performance of predicting item ratings.

RC performance of predicting item ratings.
Figure 7 shows the MAE performance of predicting item ratings over density of each test set. Since we conduct fivefold cross evaluation, each training dataset has different density. Our method shows not only the lowest MAE but also the highest RC than other methods. It shows more clearly that our proposed method is effective considering a trade-off between the coverage and accuracy of the predictions in the recommender system.

MAE performance of predicting item ratings in each test set.
The parameter

The rating coverage performance of change over threshold

The rating prediction performance of change over threshold
The UC performance in Figure 10 shows that UC gets lower as threshold
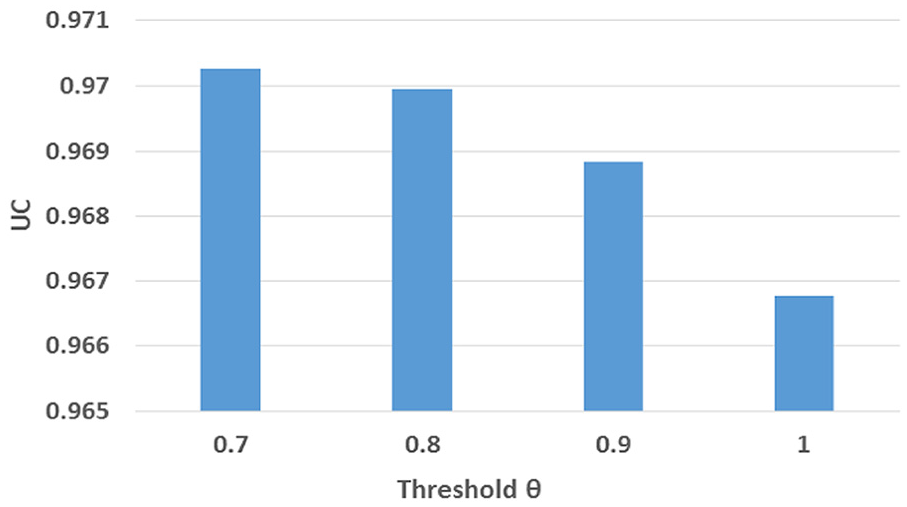
UC performance of change over threshold
We also test RMSE of change over the threshold

RMSE performance of change in
Conclusion
Trust-aware recommender systems utilize explicit trust and implicit trust to make better personalized recommendations in terms of correctness and coverage. Although most research about trust-aware recommender systems is focused on merging explicit trust into recommender systems, our research concentrates on improving implicit trust metrics to compensate for the limitations in explicit trust. For that, we argue that the performance of a recommender system becomes improved when implicit trust is able to explain the properties of trust better. The properties are asymmetry, trust tendency, and trust propagation. It means that we can utilize implicit trust in the environment of social IoT. Namely, we can use implicit trust in social IoT to spread more reliable information.
Therefore, we propose a method to configure an asymmetric trusted network. Also, we suggest a propagation metric for a directional and weighted trust graph. The proposed method calculates the relative similarity value based on the general assessment of each item. Through experiments, we confirm that our proposed method shows positive performance with higher accuracy and RC compared to existing methods. From our work, we provide contributions in recommender systems and social IoT:
We propose a method to configure an implicit trust network reflecting trust properties from a user–item rating matrix in a recommender system;
We propose new implicit trust metric, relative trust value;
We modify the explicit trust propagation method for a directional and weighted trust graph;
Our proposed method shows higher accuracy with higher RC compared to the existing recommendation methods;
It can be guaranteed that our proposed method can be utilized in social IoT environment;
We identify possibilities of new follow-up studies of implicit trust metrics.
As users are willing to provide less information on online, the methods for predictions with less referred data should be considered. For that, we suggest novel follow-up studies based on our work: reliability measurements, and belief propagation methods for a directional and weighted trust network.