
Abstract
Introduction
Human–robot interaction (HRI) was first proposed in 1975. 1 HRI is an important interdisciplinary research field of computer, ergonomics, cognitive science, and other disciplines. It is also an important content of engineering psychology research. At present, HRI is developing toward personification, intellectualization, and naturalization.
Many researchers are now dedicating their efforts to studying interactive modalities such as facial expressions, natural language, and gestures. This phenomenon makes communication between robots and individuals become more natural. 2 Gunes et al. 3 analyzed human participants’ nonverbal behavior and predicted their facial action units, facial expressions, and personality in real time while they interacted with a small humanoid robot. Ali et al. 4 designed a sign language educational humanoid that possess stereo vision and stereo microphones along with stereo audios for intuitive interaction. De Jong Michiel et al. 5 designed a humanoid robot for social interaction, they combined vision, gesture, speech, and input from an onboard tablet, a remote mobile phone, and external microphones. Kumra and Kanan 6 presented a novel robotic grasp detection system that predicts the best grasping pose of a parallel-plate robotic gripper for novel objects using the RGB Depth Map image of the scene. This article considers the sustainability of the product 7 and conducts SHFR-III interactive research from the perspective of positioning, emotion, and dialogue.
Robots should have lightweight, low-energy consumption, and excellent performance, 8 so we designed and built a humanoid emotional robot SHFR-III (see Figure 1). 9 SHFR-III has 22 degrees of freedom and can realize 8 basic expressions, including calm, happiness, and so on.

Humanoid robot SHFR-III.
Target positioning is an important part of the research of humanoid robots. 10 In HRI, first, robots need to recognize the interactive objects from the environment. Laurenzi et al. 11 introduced a set of modules based on visual object localization. Deepak Gala et al. 12 used auditory sensors for positioning. However, the positioning effect of single sensor is greatly affected by external factors, 13 such as auditory positioning is limited by noise and visual positioning is limited by illumination. Therefore, multi-sensor system can reduce this situation.
In real life, people usually do not judge each other’s emotional state based on single modal information. Visual information and voice signal information are very important for emotional judgment. Multi-modal emotion recognition is to recognize emotional states by using multi-modal information. 14 Emotional computing was first proposed by Picard. 15 Emotional computing can measure and analyze the external performance of human emotions and affect them.
As argued by Vinyals and Le, 16 the current conversation systems are still unable to pass the Turing test, and the lack of consistent personal information is one of the most challenging constraints. In recent years, Li et al. 17 learned interactive object-specific conversational styles by embedding users into sequence to sequence model. Al-Rfou et al. 18 used similar user embedding techniques to simulate user personalization. Both studies required conversational data from each user to simulate her/his personality. Qian et al. 19 used bidirectional decoders to generate predefined personality, but a lot of data are needed to mark the information location.
To make HRI more natural and harmonious, this article makes the following contributions for SHFR-III: A multi-sensor positioning subsystem is designed to reduce dependence on work environment and improve the overall positioning accuracy by data fusion of multiple sensors. The emotional recognition model based on facial expression and speech is used to deal with situations that a single modal would fail. At the same time, fuzzy algorithm is used to simulate emotional decision-making. Using default information to solve the problem of inconsistent personal information in dialogue, and maximum mutual information is taken as the objective function to reduce meaningless replies in the dialogue model.
Overview
Our interactive system works as follows (see Figure 2): First, we use multi-sensor positioning subsystem to find the exact location of the interactive objects. Then the robot adjusts the angle between the interactive objects, and the robot then obtains the facial and voice information of the interactive objects through cameras and microphones. The emotional interaction subsystem recognizes their emotional state and emotional decision-making, and SHFR-III will display the results of emotional decision-making with facial expression. The dialogue subsystem with personal information generates responses and presents them in the form of a voice.

The work process.
Multi-sensor positioning subsystem
In this article, a multi-sensor positioning subsystem is designed, which includes an infrared positioning module, an auditory positioning module, and a binocular vision positioning module.
Design of positioning module
Infrared positioning based on infrared sensor array
Four pyroelectric infrared sensors with the same parameters are selected to form the sensor array as shown in Figure 3. The vertical equidistant distribution of the four sensors and the horizontal angle of the adjacent sensors are 30°. The output results of the four sensors from top to bottom are recorded as

The infrared positioning module.
The positioning function
Positioning function truth table.

Auditory positioning based on auditory sensor array
The three sensors are isosceles triangular in the vertical plane. Sensors 2 and 3 are arranged horizontally, and the distance is

The auditory positioning module.
The time difference of sound arrival between sensor 2 and sensor 1 is defined as

As we know,

where
We have the following equation

The distance from the source



The polar angle of the sound source

where
The polar coordinates of the sound source (

Visual positioning based on binocular stereovision
The model of binocular vision positioning is shown in Figure 5.

The vision positioning module.
The focal length of the left and right eyes is (

The transformation relationship between coordinates in the plane (

The parameters of the left and right eyes are introduced into the upper equation. We have the following equation

Fusion strategy analysis of multi-sensor positioning subsystem
The working environment of the system is a closed room of 5 × 6 m2. The coverage area of the positioning subsystem is shown in Figure 6, where O is the positioning center of the multi-sensor subsystem and DEGF represents the whole room. The coverage area of visual positioning module is the triangular area ABC, and polar angle positioning error (

Regional division and error distribution.
According to the working characteristics of multi-sensor positioning subsystem, the multi-level positioning fusion method shown in Figure 7 is proposed. In triangular ABC region, all three positioning modules work normally, and the three-positioning data are fused. In rectangular MNGF region, only infrared positioning module and auditory positioning module can work, at this time, the two-positioning data are fused. In rectangular DENM region, only the auditory positioning module can work normally, and then the auditory positioning data can be output directly.

Distribution of fusion modes of positioning subsystem.
Weighted fusion algorithms with variable weights
The final result of the multi-sensor positioning subsystem, that is, the coordinates of the interactive target relative to the robot in the horizontal plane are expressed in polar coordinates

where
In this article, three kinds of positioning modules are tested separately, and the corresponding positioning accuracy is calculated. The average
The weighting coefficients are inversely proportional to the positioning accuracy, and the weighting coefficients are calculated according to the sum of the coefficients being 1.

The weighted fusion equation is as follows

In equation (3), the weighting coefficient is constant. This equation is only applicable when all three positioning systems are working normally. However, as the location of the interactive target and the external environment change, one or some positioning systems may fail. According to the positioning accuracy of each positioning system determined by experiments, a weighted fusion algorithm with variable weights is proposed.
When the interactive object is out of the location range of visual positioning module or in a dark environment,

Only when the auditory positioning module works, it indicates that the interactive object is in a dim environment and out of the infrared positioning module. At this time, the positioning subsystem directly outputs the results of the auditory positioning module.
When in a noisy environment, the auditory positioning module stops working. At this time, when

Only when the infrared positioning module works,
Emotional interaction subsystem
Bimodal emotion recognition
In this article, facial expression and voice emotion are fused by decision-level fusion.
Facial emotion recognition
Noduls Facial Expression Analysis System (FaceReader) is used for bimodal emotion recognition. This article is based on discrete emotional classification. FaceReader data output format is based on Paul Ekman’s six basic expressions plus calm expressions to construct a seven-dimensional probability matrix describing emotional state.
Speech emotion recognition
Speech emotion recognition is a new research hotspot involving traditional speech signal processing, pattern recognition, human psychology, artificial intelligence, and other fields. The research of speech emotion recognition is based on discrete emotion classification system.
The degree of confusion between category

The higher the level of confusion, the more difficult it is to distinguish between category
When the degree of confusion between a certain category and other categories is greater than 0.02 and less than 0.1, the classification situation cannot be directly judged. By calculating the total degree of confusion between the category and a subclass, the classification with high degree of total confusion can be selected.

where
Decision-level fusion
This article chooses the weighted summation method through experiments.
Fuzzy emotional decision-making model
Fuzzy emotional decision-making takes the initial emotional state and the emotional state of the current interactive object as input and combines the input to make the fuzzy emotional decision through the fuzzy reasoning rules to generate the robot’s emotions.
This article refers to the way of emotional quantification in reference 22 to quantify this emotional state. Seven emotional states are quantified as interval values. Considering external stimuli, the interval equivalence ratio is expanded to [0,7]. The Mamdani algorithm is used to construct a fuzzy affective decision model.
After analysis, the orthodox distribution curve of Gauss function is more in line with the characteristics that the affective control range is gradually weakening from the central point to the surrounding area. It shows that an emotional input belongs to the membership degree of the fuzzy emotional subset, which is convenient for calculation and processing. Assuming that all the emotional centers have the same influence range and ability, the Gauss function is as follows

where
Based on a male volunteer, the fuzzy rules of orthogonal combination are equationted and the probabilities of each rule are evaluated. As presented in Table 2, the horizontal row represents the emotional state of the robot at the front moment, the vertical row represents the external stimulus, and the numerical value of the emotional state in the table represents the proportion of the rule.
Fuzzy emotional decision rules.

Dialogue subsystem with personal information
In this article, a dialogue subsystem with personal information is proposed (see Figure 8). By giving the chat robot specific personal information, the robot can generate a response consistent with its given information. The system first uses the question classifier to distinguish whether the question needs personal information dialogue model to deal with. If yes, the model retrieves the most similar question in the template, return the answer to the category of the question, if not, the open domain dialogue model generates the response.

Dialogue subsystem with personal information.
Questions classification
The classification model is used to determine whether the input problem needs to be processed by the personal information dialogue model, which is a two-class problem. It uses
Personal information dialogue model
This article constructs a personal information dialogue model based on the twin network idea. First, the two objects to be matched are represented by the deep learning model, and then the matching degree of the two objects can be output by calculating the similarity between the two representations. This article uses bidirectional long short-term memory (BiLSTM) to represent the semantic information of sentences. 23
The loss function used is the comparative loss function, 24 which is often used in twin neural networks. This loss function can effectively deal with the relationship between paired data in twin neural networks. The expression of the comparative loss function is as follows

where
Dialogue model based on maximum mutual information
The open domain dialogue model is based on seq2seq. However,if we only rely on the maximum likelihood estimation, even if we train with a large number of data, the seq2seq model is prone to generate security answers like “不知道” (“I don’t know”), “哈哈哈”(“Ha ha ha”), and “好的”(“well”). So we use the anti-language model proposed by Li et al. 25 and take maximum mutual information as the objective function of seq2seq, as shown in the following equations



The

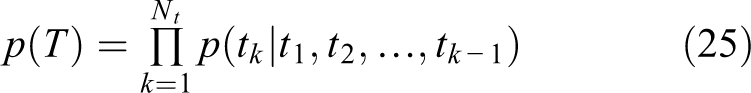

Pre-generative words have a greater impact on sentence diversity than post-generative words. In order to ensure the fluency of sentences as much as possible, only the high probability candidate words generated in the early stage are punished in the process of sentence generation by decoder. The
The model consists of encoder and decoder. In the encoder part, two layers of BiLSTM neural network are adopted, the number of units is 512, and the dimension of word vector is set to 300. Bahdanau’s attention mechanism was used. In the training process, dropout mechanism is adopted with a retention rate of 0.5, Adam learning rate is set to 0.001, batch size is set to 32, and the number of data iterations is 128.
Experiment
Experimental results of multi-sensor positioning subsystem
Each positioning module experiments in different environments
To verify that the multi-sensor positioning system can be applied to various working environments, target positioning experiments are carried out in normal lighting environment, dark environment and noise environment respectively. The experimental results are given in Table 3.
Positioning results in different environment.

From the experimental results, we can see that the some positioning module designed in this article will fail in different scenarios, but other positioning modules still work normally and have good stability.
Fusion experiment results of multi-sensor positioning subsystem
The multi-sensor positioning system is used to locate points in the environment, and the results are fused. Some statistical results are given in Table 4.
Fusion experiment results of multi-sensor positioning system.

The experimental results show that the positioning accuracy after fusion is higher than that of single positioning system, and the stability of positioning has been greatly improved.
Experiments on emotional interaction
Speech emotion recognition
This article uses CASIA Chinese Emotional Corpus for model training, openSMILE for feature extraction, principal component analysis (PCA) contribution selection 95%, and LIBSVM toolkit developed by Professor Lin of Taiwan University (Kernel function is three-degree polynomial). The degree of confusion obtained by experiments is given in Table 5.
The confusion between emotional categories.

According to the degree of confusion, the hierarchical SVM as shown in Figure 9 is designed.

The hierarchical SVM.
The comprehensive recognition rate and recognition rate of each level classifier are given in Table 6.
The recognition rate of each SVM and hierarchical model.

Bimodal emotional fusion
Some data in eNTERFACE’05 multi-modal emotion database is used to verify the validity. The five emotional expressions of happiness, surprise, fear, sadness, and anger are screened by scoring principle. Thirty pieces of data are selected for each emotion for bimodal emotion recognition.
The results of single-modal and bimodal emotion recognition are compared as given in Table 7. The experimental results show that the performance of bimodal emotion recognition is better than single-modal, with an average recognition rate of 59.34%. Table 8 gives the result of emotion recognition.
Comparison of single-mode and double-mode recognition results.

Different emotional recognition results.

When the probability of detecting disgust is the highest, speech emotion recognition is not carried out, and disgust is taken as the final recognition result.
Fuzzy emotional decision-making
After setting the initial emotional state of the robot, with the change of external stimulus, the current emotional state of the robot is simulated and calculated.
When the initial emotional state of the robot is calm, the emotional state of the interactive object changes in turn. The emotional change curve of the robot is given in Figure 10(a). When the robot changes to the state of surprise, as the external stimulus gradually turns to fear, the robot will change to fear. When it encounters the external stimulus of sadness, the robot will then turn to sadness, and keep the sad state under the stimulus of disgust. Figure 10(b) shows the simulation of experimental results with sad initial state.

The emotional change curve of robot with initial emotion: (a) initial emotion as calm and (b) initial emotion as sadness.
The simulation results show that under the fuzzy affective decision-making model, the change of the robot’s emotional state under the external stimulus is slow and continuous, and the calculation results are in accordance with the reasoning rules and human’s emotional changes.
Experiments of dialogue subsystem
In this article, the accuracy, F1 Score (FI) and Area under the curve (AUC) values are selected to evaluate the performance of the question classification model. The values are 87.69%, 0.8754, and 0.8797, respectively.
In the personal information reply model, since five identities are set in this article, accuracy refers to whether the category of sentences with the greatest similarity belongs to the label category, which is 87.4%.
The open domain dialogues are evaluated by manual and bilingual evaluation understudy (BLEU) methods. In the experiment, the penalty coefficient of the maximum mutual information model is 0.5 and
In the overall dialogue system, this article randomly selected some dialogues (the dialogues are in Table 9), and asked volunteers to evaluate the following aspects:
Samples of dialogues.

From Table 10, we can see that our model is superior to the ordinary seq2seq model in each index, especially in information consistency, because this article adds personal information reply model to ensure the consistency of personal information.
Evaluation of responses.

Conclusion and future work
This article designs an interactive system for humanoid robot SHFR-III. The system can use multi-sensor positioning subsystem to locate accurately in complex environment, use bimodal emotion recognition model and fuzzy emotion decision-making model to complete human–robot emotional interaction in the form of robot facial expression, and the dialog subsystem with personal information can complete the response consistent with the default information. The system has the advantages of easy implementation and good interactivity, and can be applied in the fields of elder group’s care, we can understand their emotional world through HRI, and use chatting to relieve their loneliness. Besides, it can also be used in the field of robot teaching and autism treatment and so on.
Our work is only a small step toward achieving a harmonious HRI, and there are many future directions:
In addition, specific subsystems should be added for different application scenarios, such as robot hand grasping, motion trajectory control, smart home control, and so on.