
Abstract
Keywords
Introduction
The swift advancement of artificial intelligence (AI) in the medical domain is progressively altering how people acquire, understand, and utilize health information. 1 From image identification and assisted diagnosis to illness management, artificial intelligence's medical applications have grown beyond lab research in recent years and are rapidly influencing clinical practice and public health messagin. 2 Concurrently, short video platforms such as TikTok, YouTube, and Bilibili have emerged as important avenues for the public to obtain medical information, voice health opinions, and engage in doctor–patient interactions. 3
According to earlier research, the caliber of medical material on social media is strongly correlated with the features of the platform and the experience of the creator. For instance, Bilibili has a higher concentration of professional medical creators, with videos on the site score much higher than those on TikTok and YouTube in terms of scientific accuracy, completeness of information, and practical precision. 4 But even on Bilibili, the majority of professional content is still produced by nonprofessionals, and the percentage of professional content is still low. This change has led to the expanding public discussion over whether “AI provides better information than doctors” on social media.
Notably, the benefits of AI in medical conversations are no longer limited to “knowledge coverage” and “logical language”; its compassion and emotional expressions in responding to patient questions have greatly increased through algorithmic optimization and training. 5 Some studies have found that in areas like psychiatric problems, AI may even surpass many medical professionals in structural clarity and emotional consistency, 6 taking into account the idea of “digital empathy.” 7 AI's diagnostic recommendations may be more comprehensive or fluid than those of healthcare practitioners, who frequently deal with more pragmatic limits like time constraints and cautious response techniques.
Furthermore, public views of AI and doctor performance are influenced by complicated elements like content packaging, creator identity, and platform computations. According to research, emotionally charged and dynamic presentation can increase the reach of even low-quality content on platforms such as TikTok, outperforming scientifically accurate content in terms of engagement. 8 However, the professionalism of artists and the completeness of video structure on Bilibili are essential components in establishing trust.4,9
In light of this, the purpose of this study is to employ multidimensional assessment tools to methodically examine variations in the quality of content pertaining to “AI + 医疗(Medical)” across the three main short video platforms (TikTok, Bilibili, and YouTube).
It also records the view tendencies of video creators and combines real doctor comments from the Dingxiang Health online platform, 10 comparing the artificially intelligent answers using Deep Seek R1 and Chat-GPT O3-mini-high. This research aims to provide a thorough response to the question of whether AI can outperform doctors in providing high-quality medical information by measuring differences in structure quality (Quality Rating) and humanistic care (Compassion and Bedside Manner). It will also provide theoretical and practical references for future mechanisms that will enhance collaboration between AI and doctors.
Methods
Study design and setting
This analysis is a cross-sectional, comparative analysis of medical information quality and compassionate treatment expressed in AI-assisted and healthcare professional-generated answers on social networking platforms. Between March 29, 2021, and December 1, 2024, video data was gathered from three prominent short video platforms (YouTube, TikTok, and Bilibili) that are available worldwide but prioritize content that is pertinent to viewers that speak Chinese and English. Real-world patient questions and answers from medical professionals were sourced from Dingxiang Health, the largest online medical evaluation platform in China, located in Hangzhou, Zhejiang Province, China. AI answers were evaluated and assessed by medical personnel at the First Affiliated Hospital of Zhengzhou University, Zhengzhou People's Hospital, and Guizhou Provincial People's Hospital coming from February 10 to 15, 2025, and data analysis was finished between February 15 and 20, 2025 (Figure 1).

Video data collection process.
Video selection and screening
We retrieved short videos related to healthcare AI-assisted diagnosis across from YouTube, Bilibili, and TikTok by looking up the key phrases “AI-Assisted Medical Diagnosis” and “AI + 医疗(Medical)” between March 29, 2021, and December 1, 2024. The initial search yielded the top 100 relevant videos from each platform's algorithm. Inclusion criteria were: (1) video duration greater than 5 s and (2) high relevance to the query terms. Exclusion criteria were: (1) advertisements and (2) videos published within the last 7 days of the search date to avoid recency bias. After applying these criteria, a total of 240 videos were included for final analysis, with the final sample size from each platform as follows: Bilibili (
Selection and screening of real doctor–patient Q&A
We sourced real-world patient questions from Dingxiang Health (https://dxy.com/). To ensure diversity, we used stratified random sampling to select 10 patient inquiries from each of five major clinical departments: Ophthalmology & ENT, Gynecology, Surgery, Internal Medicine, and Pediatrics. This resulted in a total of 50 distinct patient questions. For each of these 50 questions, we generated simulated answers using two AI models (specified below) and compared them against the original answers provided by medical professionals on the platform, resulting in a total of 150 Q&A pairs for evaluation (50 questions × 3 respondents).
Supplementary Table 2, which enumerates the samples from each department and their corresponding sources, provides specifics on the selection and screening procedure used for the Q&A.
Scoring process and standards
Scoring process
The following randomization and blinding procedures were used to guarantee scoring objectivity: For video collection, the top 100 videos per system were chosen by significance to the keywords “AI-Assisted Medical Diagnosis” and “AI + 医疗(Medical)” using system algorithms, then randomly picked using a machine that generates random numbers to select 240 videos (after excluding commercials and recent videos). For Q&A study, 10 questions per department were chosen at random from Dingxiang Health's database using a stratified random sampling technique to guarantee representation across Ophthalmology & ENT, Gynecology, Surgery, Internal Medicine, and Pediatrics. During evaluation, answers from AI (Deep Seek R1 (DeepSeek, China), a prominent Chinese LLM known for its strong reasoning capabilities and widespread use in China, Chat-GPT O3-mini-high (OpenAI, USA), a high-intelligence mode of the “o3-mini” model family, optimized for complex reasoning tasks) and physicians were made anonymous and delivered in a randomized order to three raters. All three raters independently assessed the entire set of randomized responses from all sources (i.e., both AI models and physicians). This design ensured that each rater applied the scoring criteria consistently across all respondent types, which is crucial for a fair comparison. Raters were blinded to the respondent type (AI or physician) and assessed separately to minimize bias. In order to ensure consistency, differences between raters 1 and 2 were settled by using rater 3's score as the last evaluation.
Scoring standards
Video quality assessment
Rater 3's score was used as the final assessment to resolve discrepancies between raters 1 and 2 in order to maintain uniformity.
Consultation quality assessment
In addition to rating the videos, the answers provided by AI and medical experts were also assessed using the following two score criteria:
Scoring consistency evaluation
To confirm the ratings’ consistency, Cohen's Kappa statistical method 15 was employed. This instrument is frequently used to evaluate the consistency between two raters. Stronger consistency is indicated by higher Kappa values, which range from −1 to 1. The Cohen's Kappa values in this study demonstrated strong consistency for video quality scores and answer quality scores, while degree of uniformity for the quality scores and compassion scores of real-world consulting material was lower. In cases where differences occurred between the first two judges, the third rater's score was adopted as the final assessment to maintain consistency. Detailed results are listed in Supplementary Table 3.
Data analysis and processing
Because the data in this investigation did not follow a normal distribution, nonparametric statistical approaches were used to process the data. The actions listed below were taken:
All statistical calculations were performed using SPSS 26.0 software, and the level of confidence was established at
Results
Video quality analysis
Data collection
The procedure for gathering data for this study's video quality analysis is shown in Figure 1. We chose brief films about “AI-Assisted Medical Diagnosis” and “AI + 医疗(Medical)” from the three main social media platforms (YouTube, Bilibili, and TikTok). All advertisements and videos released within the last seven days were disqualified during the screening process. Ultimately, the top 100 pertinent films from each platform were chosen, yielding a total of 240 videos for analysis, meeting the standards of being longer than 5 s and extremely pertinent to the keywords.
General characteristics analysis
Figure 2 and Table 1 display the general features of the chosen videos. Figure 2(a) to (c) illustrates the distinctions between platforms and creator occupations, creator professions and opinions, and platforms and opinions. From Figure 2(a), it is evident that the vocations of creators vary significantly among platforms. On Bilibili, the percentage of professional creators is large, while on TikTok and YouTube, the creators are primarily nonprofessionals. Figure 2(b) and (c) shows the associations between creator vocations and video opinions, as well as platform opinions. As seen in Figure 2(d) and (f), the findings indicate that creators on Bilibili (74.29%), TikTok (56.67%), and YouTube (53.75%) have a tendency to think that AI diagnostics are superior. In general, 60.83% of the videos indicate the belief that AI diagnostics are better than those of doctors (Figure 2(g)). Table 2 shows that there is a statistically significant difference between the three groups in regards to Short Video Creator Occupation (

General characteristics of the video data. (a) Stacked bar chart of Short Video Creator Occupation vs. Platform. (b) Opinions vs Occupation of Short Video Creators in a stacked bar chart. (c) Stacked bar chart of Platform vs. Opinions. (d) Donut chart of various viewpoints on Bilibili platform. (e) Donut chart of various Opinions on TikTok platform. (f) Donut chart of various viewpoints on YouTube platform. (g) Donut chart of various viewpoints across all three platforms. (h) Sankey diagram illustrating the connection between Platform, Short Video Creator Occupation, and Opinions.
General characteristics and comparative analysis of included videos.

Note: #: Kruskal-Wallis test.
M: median, Q1: first quartile, Q3: third quartile.
Occupational analysis of video creators.

Note: χ2: chi-square test
Overall opinion characteristics analysis by platform.

Note: -: Fisher exact.
Scoring analysis
The mDISCERN, GQS, and VIQI scoring systems were used to assess the videos’ quality. The following are the outcomes:

Video quality evaluation results using mDISCERN, VIQI, and GQS. (a)–(e) The findings of the mDISCERN Score are displayed using a radar plot, violin plot, bar chart, kernel density plot, and clustered violin plot. (e)–(j) Radar plot, violin plot, bar chart, kernel density plot, and grouped violin plot showing the VIQI Score findings. (k)–(n) Violin plot, bar chart, kernel density plot, and grouped violin plot showing the GQSscore findings. **
mDISCERN score analysis.
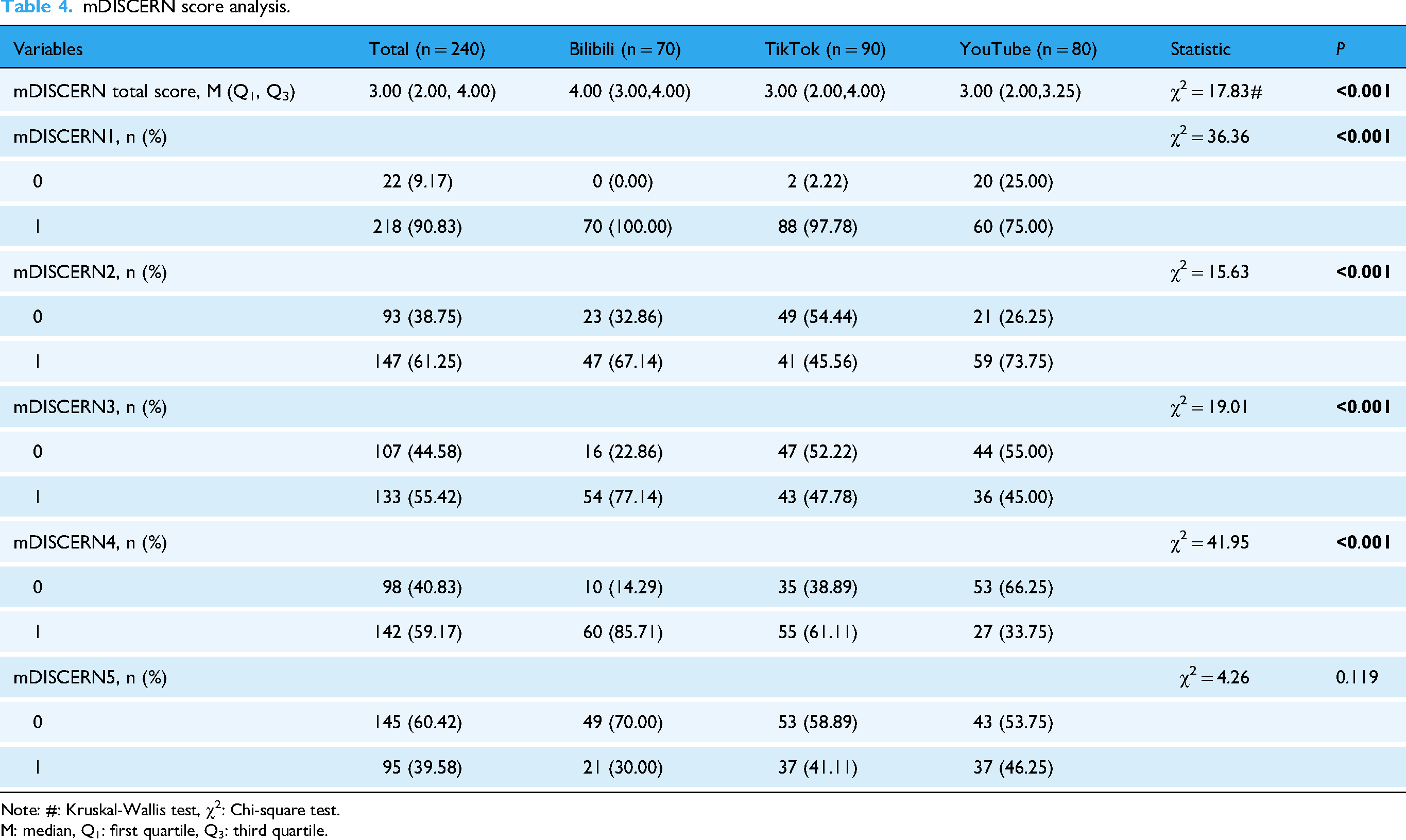
Note: #: Kruskal-Wallis test, χ2: Chi-square test.
M: median, Q1: first quartile, Q3: third quartile.
VIQI score analysis.

Note: #: Kruskal-Wallis test.
M: median, Q1: first quartile; Q3: third quartile.
Overall analysis of three scores.

Note: #: Kruskal-Wallis test.
M: median, Q1: first quartile, Q3: third quartile.
Additionally, Table 6 also presents the overall outcomes for the three grading methods. As indicated in Table 6, there are all differ significantly among the three groups for VIQI total score, mDISCERN total score, and GQS score (
Correlation analysis
We also looked at the relationship between video quality ratings and interaction data. The correlation analysis heatmap is displayed in Figure 4(a), and the primary positive findings are shown in Figure 4(b) to (f). Corresponding negative results are displayed in Supplementary Figure 1. The results demonstrate a substantial positive connection between GQS score and VIQI total score (0.69), and mDISCERN total score (0.65), indicating a considerable degree of consistency between these scoring criteria. There is a strong positive connection between interaction indicators (Shares, Collections, Likes, Comments) (around 0.9 or higher), indicating that content with more shares tends to also typically receive more likes, collections, and comments. In addition to the close relationship between user interactions (likes, shares, collections, and comments), there is also a good link between interaction behavior and content quality ratings (GQS score, VIQI, and mDISCERN). Nevertheless, the video length does not greatly impact interactions and may even be a small negative correlation.

Correlation analysis of video quality and interaction metrics. (a) Heatmap illustrating the correlation between video generic characteristics and video quality ratings. The positive correlation results seen in the heatmap are further illustrated in the regression-based scatter plots shown in (b–f), which represent: (b) Duration vs. mDISCERN Total Score, (c) Likes vs. VIQI Total Score, (d) Collections vs. VIQI Total Score, (e) Comments vs. VIQI Total Score, and (f) Shares vs. VIQI Total Score.
AI vs. Healthcare professionals answer quality analysis
Data collection
In order to assess the caliber of AI and medical expert responses, we randomly chose 10 actual patient queries from each of the five main departments (Ophthalmology & ENT, Gynecology, Surgery, Internal Medicine, Pediatrics) on Dingxiang Health (https://dxy.com/). Both Deep Seek and GPT offered answers to each topic, which were then compared to the responses from medical professionals. A total of 50 Q&A samples were chosen for examination. Figure 5 presents the data gathering procedure for the AI vs. medical personnel answer quality analysis in this study.

Question and answer analysis from Dingxiang Health Platform
General characteristics analysis
Figure 6 and Tables 7 and 8 display the distribution of responses by department and participant type. As seen in Figure 6(a) to (e), overall, the results strongly regarded Deep Seek's responses as superior (

General characteristics of the Q&A data. Bar chart (a) and donut chart (b) showing the total opinions analysis from three separate raters. (c) Stacked bar chart that shows the rater's propensity for choosing among the three raters. (d) Stacked bar chart showing which responder's answer is considered superior according to the three responders. (e) Stacked bar chart illustrating which responder's answer is superior across different departments. (f) Sankey diagram illustrating the relationship between responder, department, and opinions.
Basic characteristics and comparative analysis of responses favoring each party across different departments.

Note: -: Fisher exact.
Opinions: Which answer is better.
Basic characteristics and comparative analysis of responses favoring each party.

Note: -: Fisher exact.
Scoring analysis
We used Quality Rating and Compassion and Bedside Manner Rating to score the responses from AI and medical experts (the general distribution of scores is displayed in Figure 7(a), and Table 9 presents the outcomes of both scores). Figure 7 and Table 9 display the findings for Quality Rating (Figure 7(b) to (d)) and Compassion and Bedside Manner Rating (Figure 7(e) to (g)). A radar chart showing the three responders’ scores on these two ratings may be found in Figure 7(a). As demonstrated in Figure 7(b) to (c), for Compassion and Bedside Manner Rating, GPT's result was considerably higher than those of Physicians and Deep Seek (

Quality rating and compassion and bedside manner rating results for AI and physicians’ answers. (a) Radar chart displaying the Compassion and Bedside Manner Rating and Answer Quality Rating for the three responders. The distribution of compassion and bedside manner rating is displayed by the violin plot (c) and kernel density plot (b). (d) Violin plot showing the Compassion and Bedside Manner Rating for answers from Physicians and AI (Deep Seek + GPT). Kernel density plot (e) and violin plot (f) showing the distribution of Answer Quality Rating. (g) Violin plot displaying the Answer Quality Rating for answers from Physicians and AI (Deep Seek + GPT). **
Basic characteristics and comparative analysis of answer quality and compassion and bedside manner scores.

Note: χ2: Chi-square test, -: Fisher exact.
Correlation analysis
Figure 8(a) and (b) shows the correlation study between the accuracy and compassion evaluations for AI and healthcare professionals’ responses. Higher quality responses are often associated with stronger compassion and bedside manners, according to the data, which reveal a somewhat favorable association between Quality Rating and Compassion and Bedside Manner Rating (

Correlation analysis of answer quality and compassion. (a) A heatmap that illustrates the relationship between the overall qualities of the answer, the answer quality rating, and the ratings for compassion and bedside manners. (b) Regression scatter plot illustrating the relationship between Answer Quality Rating and Compassion and Bedside Manner Rating.
Discussion
This study methodically analyzed the performance disparities in diagnostic recommendations between AI and healthcare professionals by analyzing social media content associated with “AI + 医疗(medical)” videos and actual doctor–patient Q&A. Two very consistent and interesting tendencies emerge from the data: First, on the three platforms—YouTube, Bilibili, and TikTok—most video creators express the opinion that “AI diagnostics are better than doctors,” regardless of whether their producers have a medical training; secondly, in real-world Q&A scenarios, AI outperforms real doctors both in terms of information quality (Quality Rating) and humanistic care (Compassion and Bedside Manner Rating). The conventional belief that AI lacks empathy and compassion is called into question by these findings. This paradox should be understood within the conceptual framework of digital empathy. 16
From a communication standpoint, AI's consistency, structured output, and high readability fit in well with the “fast-paced + logically clear” content preferences of short video platforms. 17 Additionally, after incorporating new emotional language models, AI's language has become more empathetic, which is more acceptable to patients who are in urgent need of emotional care. 18 In contrast, doctors face more real-world constraints, like limited time, mental energy, and the inherent tension between doctor and patient, which may cause them to express themselves in a way that is unclear and context-dependent, which could be misconstrued as unprofessional or cold. 19
Our findings unequivocally demonstrate that platform type has a major impact on video quality. Because of its user demographic and content approval processes, videos on Bilibili are typically of higher quality than those on YouTube and TikTok. On Bilibili, professional medical creators account for a larger proportion, and the platform's stricter screening procedure for medical content makes the information provided more trustworthy. On the other hand, on TikTok and YouTube, amateur creators predominate, which not only degrades the overall medical content material but may also distort public perception by highlighting novelty and straightforward storylines that appeal to viewers while exaggerating the benefits of AI. This result is in line with earlier studies, which demonstrate that the caliber of medical information on social media platforms is closely linked to the creator's professional background. 20 We also observe that platform algorithms and user composition may further amplify this cognitive bias. 21 Furthermore, these disparities might be partially explained by the moderating guidelines and audience demographics unique to each site. Bilibili’s younger, more education-oriented user base and stronger moderation standards may favor specialized, higher-quality health content, while the broader and more divergent audiences of TikTok and YouTube, combined with less stringent moderation practices, may contribute to greater variance and overall lower quality. Bilibili, with its focus on sharing information and a greater number of professional creators, scores higher in quality of content, while TikTok and YouTube are more populated with nonprofessional creators who tend to highlight AI's advantages. Additionally, this preference shows cross-platform consistency—AI is considerably preferred over doctors in user surveys across all platforms, which is an ongoing trend, not an isolated case. The fact of AI-assisted healthcare being superior to doctors in some contexts 22 has also begun to alert researchers.
This paradox, where AI is seen as being similar to (or better than) doctors, while doctors are not viewed as doctors, essentially reflects the divergence between the way medical information is presented and the professional content in contemporary healthcare communication.23,24 AI provides an idealized dialogue model that fits user expectations in its language: both organized and warm. 25 Real doctors, on the other hand, are limited by a number of realities (time, inadequate knowledge, emotional regulation), which forces them to communicate more professionally and with less emotion.. 26 This is not helpful in a digital setting and can even be interpreted as discriminatory if doctors’ responses are too direct. 27 This explains why the idea of “digital empathy” has drawn more attention from scholars in recent years, particularly with the growth of telemedicine. The significant advantage AI showed in humanistic care dimensions (Compassion and Bedside Manner Rating) in this study can provides a deeper understanding through the lens of digital empathy.16,28 Digital empathy emphasizes the transmission of caring experiences through language techniques, emotional symbols, and interaction design in mediated communication.2,16 AI systems, through algorithm-generated responses, exhibit three main characteristics of digital empathy: structured emotional templates, established emotional cues, and interaction immediateness.2,16 In simulated consultations, DeepSeek and ChatGPT models employ strategies like frequent emotional anchor words (“I understand your concern,” “This must be difficult for you”), detailed descriptions of pathology (which improve cognitive empathy), and preset comforting phrases (“We will find a solution together”), in order to create an idealized care script that aligns with user expectations. Even though this algorithm-driven empathy expression lacks genuine affective underpinnings, its language structure's completeness and consistency in emotional density increase the likelihood that it will be viewed as “professional and warm” in fragmented short video platforms. 29
However, healthcare professionals’ humanistic expressions are constrained by the compassionate expressions of healthcare personnel. First, real doctor–patient interactions show a time dilution effect in empathy—doctors need to balance medical correctness and emotional support within limited time frames, leading to a significantly lower percentage of caring utterances compared to AI. Second, the digital migration loss of sympathetic indicators (including eye contact and body language) in clinical practice is clearly visible when transposed into writing. For instance, cautious phrases used by doctors to avoid legal concerns (e.g., “The possibility of malignancy cannot be excluded”) may be twisted into “cold assertions” or even misrepresented as “schadenfreude” in short clip platforms. The reshaping of communication by platforms may alter the original aim of professional assessments, which is consistent with the “media filter” phenomena in digital empathy theory. 16
In addition, we think that the scope and importance of humanistic care in medicine need to be reexamined. It is an indisputable fact that physicians in the actual world treat patients both psychologically and physiologically.30,31 In professional practice, what patients truly need is often a concise and well-organized response, rather than overly sentimental or performative sympathy. 32 Doctors’ fundamental duty of physicians is professional judgment, followed by emotional support. Humanistic care that is appropriate can improve patient compliance and trust, but too much of it might weaken one's professional image and make decisions less effectively. 33 This is a crucial issue our study aims to highlight: doctors should achieve structured empathy while retaining scientific judgment, instead of mindlessly copying AI's soft templates. Our results imply that this idea of “structured empathy” can be effectively integrated into medical education programs, enabling physicians to speak more clearly and compassionately without compromising their ethical standards. Such training could balance the gap between clinical rigor and patient-centered communication. From a pragmatic standpoint, AI's benefits in standardized expression and structural modeling provide useful illustrations for medical professionals’ communication education. This is another key point this study wants to stress, that is, the complimentary relationship between human and AI in medical diagnostics (Human-Artificial Intelligence Theranostic Complementarity). 34 In the future, AI may assist human physicians in optimizing expression structures, improving communication efficiency in actual clinical contexts, rather than totally replacing them.
Limitations
There are various restrictions on this study. Initially, the video and consultation samples were limited to three platforms and a single country source, which would have limited their applicability in different contexts. Second, only two proprietary AI models (DeepSeek R1 and o3-mini) were tested; performance may vary between different systems and subsequent iterations, and reproducibility is limited by vendor-controlled parameters. Third, all assessments were carried out in simulated, text-only environments, which exclude the nonverbal clues and contextual dynamics central to actual clinical interactions and may have skewed raters to believe that AI outputs as more sympathetic. Fourth, despite the implementation of blinding and randomization processes, some degree of rater subjectivity cannot be eliminated. Lastly, there was limited comparability among indicators due to the incomplete harmonization of cross-platform interaction metrics. These limitations set the parameters of inference but do not diminish the relevance of our findings, which offer a preliminary body of evidence base for comprehending how platform characteristics and AI systems impact digital health communication.
Conclusion
This study demonstrates that platform setting and respondent type significantly influence the perceived quality of digital health communication. Despite having a wider audience, TikTok and YouTube, which are dominated by amateurs, showed lower quality films than Bilibili, which regularly featured higher-quality videos, particularly from professional creators. In simulated text-only consultations, AI answers were rated higher than those of physicians for both informative quality and sympathetic tone, with DeepSeek excelling in structural clarity and GPT in perceived empathy. It must be emphasized that these assessments of empathy are confined to the textual domain of simulated interactions and do not equate to the complex empathy demonstrated in real-world clinical settings, which relies heavily on nonverbal communication and shared contextual experiences. Furthermore, the content sampled in this study was subject to the curation of each platform's recommendation algorithms, which may prioritize certain types of content (e.g., novel or pro-AI narratives) and thus influence both the availability of videos and user perceptions. These results imply that AI systems may offer helpful models for organized and patient-focused communication; yet, they should be taken cautiously because text-only evaluations cannot capture the nonverbal clues and contextual dynamics central to actual clinical practice. Rather than suggesting replacement, the findings point to possibilities for AI–clinician collaboration to enhance both accuracy and humanity in digital health communication, a path that future multimodal and longitudinal studies should pursue.
Supplemental Material
sj-tif-1-dhj-10.1177_20552076261421341 - Supplemental material for Comparing AI and physician medical advice quality and humanistic care on social media platforms
Supplemental material, sj-tif-1-dhj-10.1177_20552076261421341 for Comparing AI and physician medical advice quality and humanistic care on social media platforms by Zhaorui Wang, Youfu He, Linlin Guo, Yu Qian, Liqiong Ai, Jing Huang, Ruiting Feng and Qiang Wu in DIGITAL HEALTH
Supplemental Material
sj-xlsx-2-dhj-10.1177_20552076261421341 - Supplemental material for Comparing AI and physician medical advice quality and humanistic care on social media platforms
Supplemental material, sj-xlsx-2-dhj-10.1177_20552076261421341 for Comparing AI and physician medical advice quality and humanistic care on social media platforms by Zhaorui Wang, Youfu He, Linlin Guo, Yu Qian, Liqiong Ai, Jing Huang, Ruiting Feng and Qiang Wu in DIGITAL HEALTH
Supplemental Material
sj-xlsx-3-dhj-10.1177_20552076261421341 - Supplemental material for Comparing AI and physician medical advice quality and humanistic care on social media platforms
Supplemental material, sj-xlsx-3-dhj-10.1177_20552076261421341 for Comparing AI and physician medical advice quality and humanistic care on social media platforms by Zhaorui Wang, Youfu He, Linlin Guo, Yu Qian, Liqiong Ai, Jing Huang, Ruiting Feng and Qiang Wu in DIGITAL HEALTH
Supplemental Material
sj-xlsx-4-dhj-10.1177_20552076261421341 - Supplemental material for Comparing AI and physician medical advice quality and humanistic care on social media platforms
Supplemental material, sj-xlsx-4-dhj-10.1177_20552076261421341 for Comparing AI and physician medical advice quality and humanistic care on social media platforms by Zhaorui Wang, Youfu He, Linlin Guo, Yu Qian, Liqiong Ai, Jing Huang, Ruiting Feng and Qiang Wu in DIGITAL HEALTH
Supplemental Material
sj-docx-5-dhj-10.1177_20552076261421341 - Supplemental material for Comparing AI and physician medical advice quality and humanistic care on social media platforms
Supplemental material, sj-docx-5-dhj-10.1177_20552076261421341 for Comparing AI and physician medical advice quality and humanistic care on social media platforms by Zhaorui Wang, Youfu He, Linlin Guo, Yu Qian, Liqiong Ai, Jing Huang, Ruiting Feng and Qiang Wu in DIGITAL HEALTH
Footnotes
Acknowledgments
The acknowledgments are extended to the short video production team involved in this project and the medical experts who contributed to the consultation content on the Dingxiang Doctor platform. Additionally, the Tiktok, Bilibili, YouTube, GPT, and Deep Seek platforms are thanked.
Ethical considerations
This study has been authorized by the Institutional Review Board of The Fifth Clinical Medical College of Henan University of Chinese Medicine (Zhengzhou People's Hospital) (Approval No.20250215-001). As only publicly accessible, anonymized data were used, the requirement for informed permission was not required.
Author contributions
Zhaorui Wang, Youfu He, and Linlin Guo: conceptualization, methodology, investigation, data curation, and writing – original draft (equal contribution). Youfu He: supervision, project administration, funding acquisition, and writing – review and editing (corresponding author). Jing Huang and Yu Qian: formal analysis, validation, and visualization. Liqiong Ai: resources, software, and validation. Ruiting Feng and Qiang Wu: writing – review and editing and supervision.
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was provided by the Guizhou Provincial Science and Technology Agency Project (Qian Ke He Foundation ZK [2023] General 217; Qian Ke He Foundation ZK [2023] General 216); and Support by Key Advantageous Discipline Construction Project of Guizhou Provincial Health Commission in 2023; the Provincial Key Medical Discipline Construction Project of the Health Commission of Guizhou Province from 2025 to 2026; and 2024 Zhengzhou City Medical and Health Science & Technology Innovation Guidance Program (Project No. 2024YLZDJH273). The study design, data collection and analysis, publication decision, and manuscript preparation were all beyond the funders’ purview.
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Data availability statement
All data is sourced from publicly accessible video site Bilibili (bilibili.com), TikTok (tiktok.com), and YouTube (youtube.com). The online consultation data is sourced from the publicly available Dingxiang Health platform (dxy.com).
Supplemental material
Supplemental material for this article is available online.
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.