
Abstract
1. Introduction
In recent decades, intelligent aerial vehicles have experienced an explosive growth. Self-improvement ability has become a natural property for robotic machines, while the hard-coding controller cannot adapt to the new environments. Human beings learn to adjust their actions from the consequences of implementing policies [1]. Based on these experiences, humans facilitate the development and expression of adaptive behaviours to complete new tasks by trial and error. Reinforcement learning refers to an algorithm for robots to learn optimal policies [2].
Reinforcement learning techniques are widely utilized for smart robots [3–5]. Over the last few decades, policy-search methods have proven more efficient than value-search methods in the domain of continued states and high-dimension problems [6], and several applications have been proposed [3, 7, 8]. In robot learning, some experiences can be modelled as motor primitives that were introduced to construct complex behaviours [9]. By adjusting the meta-parameters, the robots can generalize new behaviours in order to adapt to new situations without having to relearn the overall shape of motion [10]. Jan Peters employed an expectation-maximization policy-search algorithm called reward-weighted regression(RWR) to solve an optimal control problem for robots [11]. Jens Kober [12] generalized the RWR algorithm with predictive variance for exploration and constructed a kernel-based version called Cost-regularized Kernel Regression(CrKR). CrKR and RWR drew meta-parameters from Gaussian distribution
The quadrotor unmanned aircraft is an attractive vertical take-off and landing aerial vehicle that has attracted a lot of attention. The aerial vehicle is a typical under-actuated and non-linear coupled system. Many control methods are designed for the stabilization and trajectory tracking of the quadrotor. Bouabdallah [13, 14] applied the classical PID and LQ algorithm to the attitude stabilization and achieved trajectory tracking by combining an inner/outer loop with backstepping and sliding-mode techniques. Madani and Benalleque [15] designed a controller to track the desired trajectory by using a full state backstepping approach. Moreover, they [16] considered the uncertainty and unknown dynamics of the quadrotor and presented a robust trajectory-tracking controller. The neural network, as a powerful approximation approach, was introduced into the domain of adaptive and robust control. Nicol, Macnab and Ramirez-Serrano [17] utilized robust control with a neural network to solve the problem of wind disturbance. Raimúndez and Villaverde [18] augmented a conventional PD controller by using a real-time tuning, single hidden-layer neural network as an adaptive element to account for model's inversion error cancellation.
In this paper, we present a uniform framework of adaptive control by using policy-searching algorithms for the quadrotor. Four policy-search methods are utilized for adjusting model parameters and the compensation for external disturbances by learning the adaptive elements. The four methods are RWR, CrKR, PoWER and the kernel version of PoWER, which are introduced in this paper.
This paper is organized as follows. Section 2 illustrates the details of the policy-learning problem. The reviews of RWR, CrKR and PoWER are presented in Section 3, along with the description of an improved new algorithm. The model of the quadrotor is illustrated in Section 4. In Section 5, the landscape of the adaptive trajectory controller is described. Evaluations of and experiments with four algorithms are presented in Section 6, and we offer some concluding remarks in Section 7.
2. Policy-learning Problem
In a real control problem, a policy or controller is constructed in order to acquire effective actions for some purposes. The policies can be determined by using appropriate parameters

where

where
For policy searching, a Gaussian policy is always employed, as well as:

where
3. Policy Search Approaches
In this section, firstly, we review three Expectation Maximization(EM) algorithms provided by Jan Peters and Jens Kober [11, 19, 20]. Subsequently, the weighting exploration with a cost-regularized kernel regression is described.
3.1. Expectation-Maximization-based policy-search approaches
While the policy-gradient methods require the user to specify a learning rate for the parameter learning's progress, Expectation-Maximization policy search approaches update parameters as a weighted maximum likelihood estimate, which has a closed form solution for most of the policies used.
The Monte-Carlo Expectation-Maximization(MC-EM) method is considered as an efficient policy-search method. Firstly, an episode-based MC-EM algorithm is presented by Algorithm 1 [21].
Episode-Based MC-EM Policy Updates

Reward-Weighted Regression(RWR) is a version of an episode-based MC-EM policy-learning algorithm, which uses a linear mean policy with a state-independent variance for

where

and

We insert Eq. (6) into Eq. (5), which can be rewritten as:

where

Instead of exploration with state-independent variance for RWR, PoWER augments a policy with state-dependent variance, and thus

where
For most policy-learning algorithms, designing good basic functions is challenging. Therefore, a kernel-based version of reward-weighted regression is introduced and called ‘Cost-regularized Kernel Regression’. By inserting Eq. (8) into

With the kernel function

where

CrKR utilizes kernel functionality and need not define parameterized policy and basis functions. With exploration in space
3.2. Cost-regularized kernel regression with weighting exploration
As PoWER, we adopt state-dependent variance for the stochastic policy and apply the perturbation to parameters

Eq. (14) can be inserted into Eq. (6) to obtain:

where

for each episode
Therefore, with the weights' exploration, the kernel-based version of meta-parameter regression can be transformed to:

where

Use of cost-regularized kernel regression with weighting exploration(We-CrKR) achieves the appropriate parameters by exploring within the weights' space instead of the parameters' space.
A simple simulated planar-cannon shooting is considered to benchmark the two reinforcement learning algorithms CrKR and We-CrKR. The 2D toy-cannon shooting game is described by Lawrence [22]. The simulation is set up on a planar with Stokes's drag and horizon wind model(the wind velocity equals 1m/s). The toy cannon is located at (0, 0) while the target is putted on the

where
CrKR and We-CrKR are the two algorithms that are compared with each other, and the performances are averaged over 10 complete learning runs. Twenty-five Gaussian functions are considered to be the basic function, with the desired position as the input state on a regular grid for each parameter. Two algorithms converge after 500 episodes. However, because the meta-parameters derived from CrKR perturb approximately before the completion of these 500 episodes, the costs of CrKR are slightly higher and have a larger standard deviation than those of the We-CrKR algorithm. Figure 1 describes the performance of the two methods: lines show the median and error bars indicate the standard deviation.

Costs of CrKR and We-CrKR(
4. Quadrotor Mathematical Model
The model of a quadrotor is presented as follows. Firstly, two coordinate systems are introduced: the inertial frame

Using the Newton-Euler formula, the dynamics of the quadrotor in a fixed inertial frame can be expressed by:

where

where

In the inertial frame, the force


Coordinate System of the Quadrotor
5. Adaptive Trajectory-tracking Controller
The trajectory-tracking controller in reference [23] is utilized as the basic policy. The basic controller adopts the inner/outer-loop structure. A position-error PD closed-loop equation of the quadrotor constructs the relationship between the attitude and the linear acceleration. Subsequently, a command-filtered backstepping technique for tracking the attitude commanded signal was produced by the outer-loop position controller. The details are specified by Algorithm 2.
There are two command-filtered parameters, which are
In non-linear control, the outputs bear a close relationship to the system parameters of the quadrotor, such as the quality of mass and the moment of inertia. However, the accurate system parameters are hardly ever obtained and, even more importantly, some of them change during flight. Another problem is external disturbances, such as gusts of wind.
In order to solve the first problem, the system parameters are considered as the meta-parameters for the reinforcement learning algorithm. According to the flight performance and temporal reward, the parameters can be updated to create a better reward and flight performance. The logic process of the adaptive controller is described by Figure 3. The inputs of the adaptive policy-search block include the states

Adaptive trajectory-tracking control block diagram
Suppose that the accurate mass and moment of inertia are unknown, the meta-parameters

Trajectory tracking control with command-filtered compensation

We choose the states

where


where


where the
Considering the effects of external disturbances, we add adaptive elements to the control parameters. In addition, the logic process is the same as the one presented above in Figure 3, but the adaptive elements denote different sections. We can define the new controller parameters with adaptive elements as:
6. Evaluations and Experiments
In this section, we consider the system parameters' adaptation and adaptive control for external disturbances within the framework of reinforcement learning. A quadrotor model is picked up to describe the performances of algorithms, and the basic parameters of the quadrotor are presented in Table 1 [24].
Quadrotor unmanned, mini-helicopter model parameters

The basic control parameters are the same as those given in reference [23] and can be described as:

and sampling time
In a real flight of a quadrotor helicopter, there are always some system parameters needing correction. Moreover, external disturbances are other unpredictable elements. We need to utilize the adaptive controller to overcome the effects of these factors, and two scenarios are considered: a quadrotor with inaccurate system parameters, and trajectory tracking for a quadrotor with external disturbances.
In Scenario 1, a quadrotor with inaccurate mass


where


while the initial system parameters are presented in Table 1. Therefore, two kernel-based regression algorithms are utilized to adjust the system parameters in the controller for better performance during flight.
Figure 4 describes the performances of two algorithms. The We-CrKR algorithm explores in the weights' space and has a quicker convergence than that of CrKR. Moreover, a higher reward is achieved by We-CrKR, with smaller variance after 500 episodes. The trajectory provided by the origin controller is presented by the green curve in Figure 5 and there is a relatively large gap from the expected trajectory. The CrKR and We-CrKR can both, finally, provide good performances for flight with the meta-parameters described in Table 2. In addition, the results of We-CrKR are closer to the real system parameters than those of CrKR.
Improved meta-parameters by CrKR and We-CrKR


Rewards of flight with CrKR and We-CrKR for inaccurate system parameters

Trajectories of flight with CrKR, We-CrKR and an origin controller for inaccurate system parameters
For online learning problems, the real flight data cannot provide sufficient exploration in the parameters' space for direct model-free policy learning. Using a model-based policy search is a solution and, with supervised learning techniques, the simulation vehicle model can be achieved through the flight data, and then be based on simulation-model policy updates with CrKR or We-CrKR in order to obtain improved meta-parameters. The details of a model-based policy search are described in reference [21].
In Scenario 2, adaptive elements



where


Adaptive elements




For constant wind, we define
In Figure 6, the results of PoWER and RWR are compared with each other. The red curve denotes the rewards for all roll-outs provided by PoWER, while the blue one presents the performance of RWR. The results are averaged over 10 episodes and the lines show the median values and error bars indicating standard deviation. It is obvious that the performance of PoWER is better than that of RWR. In addition, the final average reward of PoWER reaches about 5.8 while only reaching 5.45 for RWR.

Rewards of flight with PoWER and RWR for constant wind
Figure 7 describes the trajectories of position for all three controllers. The red curve denotes the trajectory conducted by the adaptive controller, which is improved by the reinforcement-learning framework of PoWER. The adaptive controller cancels the effects of constant wind on the quadrotor, and a tiny tracking error is acquired. With trained parameters supplied by by RWR, the adaptive controller decreases the tracking error compared with that of the origin controller, but the error is larger than that of PoWER's controller.
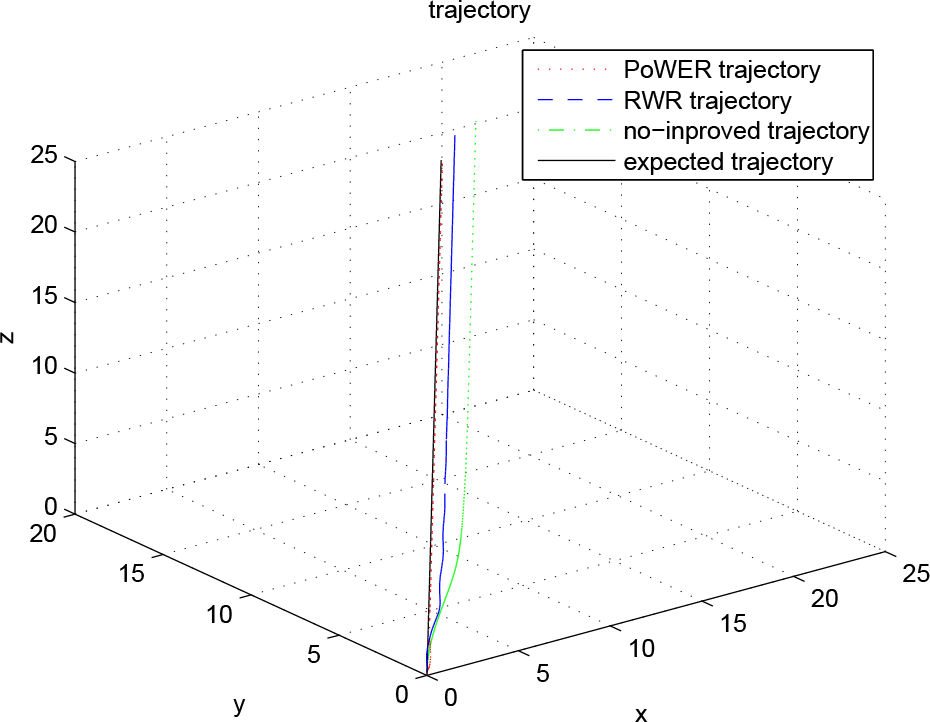
Trajectories of flight with PoWER, RWR and the origin controller for constant wind
Wind gusts are always considered as turbulence flows. The direction and strength of turbulence varies irregularly, and we can pick up the system noise in order to represent the effect of turbulence. Thus, define
Figure 8 describes the rewards of two algorithms. Because of the turbulence, the two algorithms both have large variances. After approximately 3,000 episodes, the PoWER has converged and, moreover, yields a high performance with a reward of 5.9. RWR always improves the performance during all episodes, but finally yields a performance with a reward of 5.8. Without the adaptive elements, the origin controller cannot erase the effects of turbulence and a tracking error exists. Moreover, a smaller tracking error seems to be achieved by using PoWER (see Figure 9).

Rewards of flight with PoWER and RWR for gusts wind

Trajectories of flight with PoWER, RWR and an origin controller for wind gusts
In the last case, a buffeting wind that changes periodically is considered, and the effects of the wind

which are also considered in Reference [17].
With the same initial conditions as those of the previous simulations, after approximately 800 episodes, PoWER has converged, while RWR spends approximately 2,000 episodes on convergence. In addition, PoWER achieves a higher reward than that of RWR (see Figure 10(a)). Moreover, the trajectories of position for PoWER and RWR are described by Figure 10(b). Figure 10 shows the trajectories of states for PoWER and RWR, and the actions and angles are reachable by a real quadrotor.

Trajectories of states with PoWER and RWR for buffeting wind: (a) Rewards for PoWER and RWR; (b) Positions for PoWER and RWR; (c) Euler Angles for PoWER; (d) Euler Angles for RWR; (e) Thrust for PoWER; (f) Thrust for RWR; (g) Torques for PoWER; (h) Torques for RWR
7. Conclusion
In this paper, we combined a command-filtered non-linear controller with reinforcement-learning techniques in order to construct an adaptive trajectory-tracking control algorithm, which will protect against inaccurate system parameters and external disturbances for a quadrotor helicopter. Within a reinforcement-learning framework, we separated the problem into two parts: meta-parameters' prediction and adaptive policy learning. Based on CrKR and PoWER, a new kernel-based regression called We-CrKR was provided with less variance in the initial phase. CrKR and We-CrKR were utilized for learning the meta-parameters for the quadrotor system, and better performance and less variance can be obtained by using We-CrKR. Moreover, PoWER and RWR were introduced for learning the adaptive elements. Numerical simulations for the two problems were performed and the results demonstrated the efficiency of the adaptive trajectory-tracking algorithm with reinforcement-learning techniques.