
Abstract
Keywords
Introduction
A behaviour-based paradigm has had a strong impact on multi-robot system research. The social characteristics of insects and animals are analysed in order to examine and apply these findings in designing multi-robot systems. There are many algorithms (e.g., GA, ACO and PSO) inspired by biological societies, which are applied in multi-robot systems to develop similar behaviours like searching [1,2,3] and foraging tasks [4]. Using a multi-robot system in searching tasks can offer several major advantages over the single robot alternative. Searching can be run on a massive pattern in parallel. Here a significant decrease in time regarding the location of the targets and improved robustness against failure of individual robots by redundancy, as well as individual simplicity, is observed [5].
The particle swarm optimization technique is a population-based stochastic search technique introduced by [6,7]. Recently, this technique has been applied to multi-robot search systems. The first versions of PSO were proposed in [1, 2, 8] on a multi-robot search system to find a target in the environment, and studies have demonstrated that the PSO algorithm has an acceptable performance in the searching task. In several instances, adaptations of PSO have been used for multi-robot odour searches [9, 10]. Adapted versions of PSO on distributed mobile robots have been used to search the environment based on only local information [2, 11]. These adapted versions of PSO demonstrate that their performance in a group of robots is better than the basic PSO algorithm; however, this adapted version has its shortcomings, particularly when placed in an environment with a high density of obstacles.
One of the main problems of basic PSO is premature convergence; that is, the particles have a tendency to move towards the best location found and converge to that area; therefore, there is exploitative behaviour in PSO over time. It is obvious that the global searching (exploration) of PSO decreases as time progresses. Some of the variations among many that improve its performance include: fuzzy PSO [12], hybrid PSO [13], intelligent-particle swarm performance [14], addition of a queen particle [15], etc. These variations are tested on the benchmark functions.
The problem of premature convergence is also evident in the multi-robot search system in environments which contain static obstacles. In other words, one of the basic PSO properties is that the global searching or exploration of robots decreases over time and they converge to a small area, and then become unable to explore other promising areas. This problem is called premature convergence. Under this circumstance, when there are big obstacles in an environment, these static obstacles amplify this problem. These obstacles are bigger and taller than the robots and so prevent them from observing the environment behind them. When the target is placed near the obstacles, therefore, the probability of observing from the other side of the obstacles is low, and as time increases the global searching of the robots decreases. As a result they search the small area continuously, and finally converge to that small area, without being able to search the other promising areas.
Based on basic PSO, the robots' velocities in the early iterations are high due to their greater inertia weight (
Another problem of basic PSO is the lack of guarantee in global convergence. Establishing an efficient balance between exploration and exploitation is one of the drawbacks of basic PSO. Researchers have proposed several methods to solve this problem in different domains [17, 18]. This drawback is evident in multi-robot search systems designed on basic PSO. In a sense, in some cases, the robots are placed near the target but have to move based on the velocity and position equations of basic PSO, which may guide the robots to move to the position located farther from the target. This situation obviously causes the search time to increase, particularly when there are obstacles near the target. In this situation the best global robot (
In this article, a simple and effective PSO named the 'Modified PSO with Local Search (ML-PSO)' is proposed. This ML-PSO is based on the modification of basic PSO developed by [20], which was applied in the exploration search space. Here, a new method is proposed on a multi-robot search system which increases the global searching and guides the robots to escape from the local optima and explore different areas to find the desired target. The attempt is made to overcome two problems: premature convergence through increasing the global searching of robots, and adding a local search algorithm such as A-star to guarantee global convergence with a reduction in the search time.
The study is organized as follows. Section 2 introduces the important tools that are used by this proposed algorithm. Section 3 thoroughly describes the proposed algorithm (ML-PSO). The computational results are provided in Section 4. Lastly, some conclusions are provided in Section 5.
Theoretical Background
Particle swarm optimization (PSO)
Particle swarm optimization (PSO) is a new optimization search technique which solves numerical optimization problems. In this method, particles fly through the multidimensional search space to find the potential solution.
To model the swarm, each particle starts to search a with a randomized position (
The next position vector

The velocity of each particle is updated by the following equation:

Equation (2) contains three members: the first member is momentum, while the second and third members are cognitive and social components, respectively.
Momentum:
Cognitive component:
Social component:
Momentum pulls the particle towards the previous velocity direction. The cognitive component is the force that pulls the particle to its best position found thus far, and the social component attracts the particle towards the bestsolution found among all the particles. The inertia weight

The pseudo code of basic PSO
In order to match the basic PSO to the multi-robot system, some modification are needed. In the next section the necessary modification for this study is proposed.
The use of one-to-one matching between particles in the PSO swarm and robots in the multi-robot system motivates our PSO-inspired multi-robot search algorithm. It is assumed that the robots have access to the map of the search space and therefore have complete knowledge about their location in the environment. If the robots do not access the whole map of the environment, it may cause a localization error, in most of these cases preventing the system from accomplishing the search task. There are some key differences between PSO and PSO in the multi-robot search that requires us to make some modifications to the algorithm.
Search space and static obstacles
A real search space was transformed into two-dimensional search space and discretized into non-overlapping cells. The environment in this study includes some static obstacles and a single target. The positions of the obstacles are known, but the location of the target is unknown. The cells that are occupied with the obstacles in the discretized map are marked as unsafe cells and the rest of the cells are considered as safe cells. Therefore, the robot, during the path planning, moves to the safe cells. The centre of each cell is considered a point of interest. This means that if the robot visits the centre of the cell, the entire cell is considered to be a visited cell.
Robot
In this study, it is assumed that the geometrical shape of the robot is like a circle with the determined radius ( ) and has the same size as a cell. The state of each robot in the search space is represented by six variables (x, y, v,
) and has the same size as a cell. The state of each robot in the search space is represented by six variables (x, y, v,
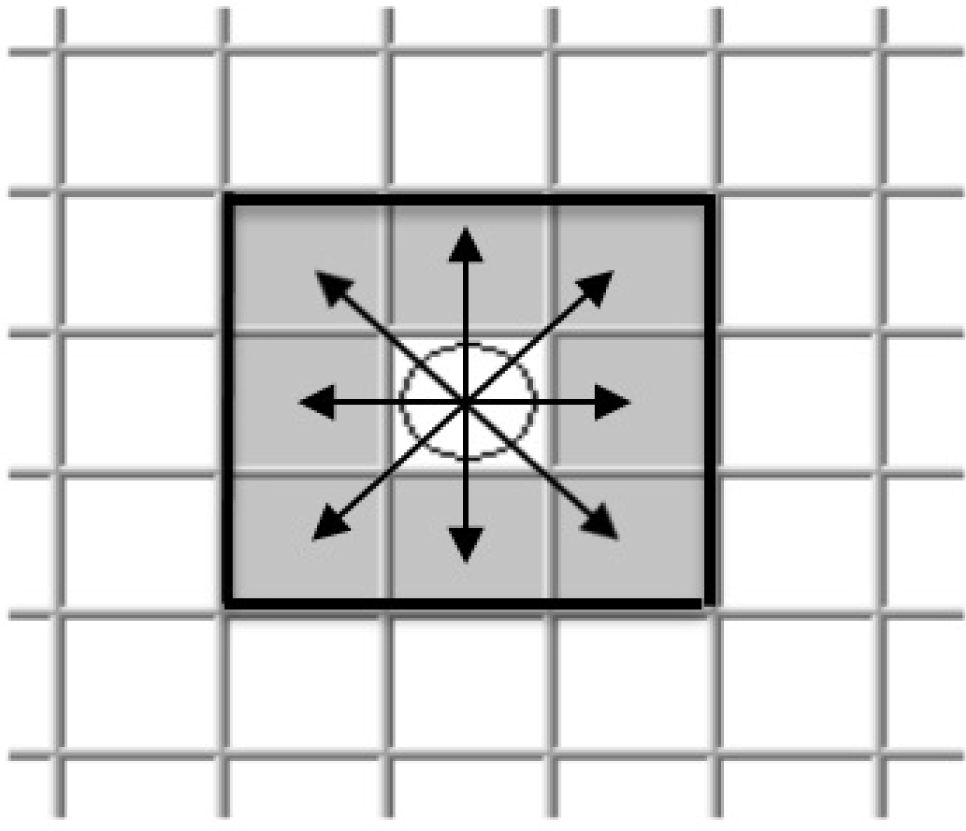
The adjacent cells of the robot in its current position
As described, the search space is discretized; then the path planning of the robot from its current cell to the goal cell is discretized and the robot must cross through the centre of the cells on its route. For a single path the environment is considered to be a static world, and the problem is solved by the A-star algorithm [23]. The traditional A-star method computes the optimal path from the start position to the goal position among the static obstacles, but it fails in a dynamic environment.
It is assumed that the robot camera, which can capture a picture from the environment, is a fitness function. The robot sees up to 10 cells from its current position in eight different directions. Figure 2 shows eight directions from the current position of the robot. When the robot uses the camera to observe its surroundings, if the target is placed in the range of view of the camera (placed in its surroundings) then the fitness function based on equation (3) is calculated; otherwise, it returns to zero. The fitness function is as follows:

Where
Although the particles in the basic PSO do not have limited acceleration and velocity, in the real world the robots have limited velocities that are discretized into discrete values. The velocity of each robot is placed between [−
Collision avoidance among the robots
Using the basic PSO particle displacement at each iteration, detecting any collisions that might occur along the path is not possible. Therefore, approximating the continuous movement of the robots by dividing the displacement into multiple steps and checking for collisions at each iteration is needed. In a multi-robot system, the robots and the target have some volume, and therefore have to avoid collision with each other and static obstacles. In this study, in order to avoid possible collisions among robots, the method proposed in [24] is used. In this study, it is assumed that each robot is equipped with a microcontroller that is able to calculate some simple formulae. Here, the value of the fitness function of each robot is calculated by each of them and is then sent to the central station. The next position and velocity of each robot is calculated by the central station, and then the route of each robot from its current position to the next position is generated. Finally, the collision between the path of the robots and the static obstacles in the search space is checked and the collision-free path is sent to each robot.
Communication among the robots
In this study, at each iteration the robots move to the next position, and the value of fitness functions in these positions are evaluated by each robot. After this, the information about their current positions and their fitness function values are sent to the central station in parallel. The central station updates the map of the environment based on the current positions of the robots. This means the current positions of the robots on the map are marked as visited cells, and are updated at each iteration. The central station based on the obtained information calculates the next velocity and next position of each robot. The next positions and next velocities of the robots are calculated based on the given algorithms (ML-PSO or basic PSO). Finally, the next positions and next velocities of each robot are sent to the robots, and they move to them synchronously at the next iteration.
The algorithm
This proposed algorithm (ML-PSO) is a new version of the basic PSO that is segmented into three: 1) initialization, where each robot is placed in a random manner in the search space with the random velocity and headings. 2) The fitness function of each robot is evaluated according to Eq. (3). If the value of fitness function is greater than any found so far, it is stored as the best position, named
The termination criteria are essential for obtaining the proper solution in a rational time. In this study, if one of the robots reaches the target or the number of iterations exceeds the maximum iterations, which are assumed to be 400 iterations, the termination criteria are reached and the program terminates.
If the number of iterations exceeds 400 iterations, it means that the algorithm could not find the target.
Figure 3 represents the steps of ML-PSO.

The pseudo code of ML-PSO algorithm
Two strategies are proposed in this method. The first strategy establishes an efficient balance between exploration and exploitation by adding the local search method. The second strategy attempts to overcome the premature convergence problem by attracting the robots to the unrevealed area and increases global searching.
The basic PSO cannot guarantee the global convergence of the algorithm. In the ML-PSO, the local search algorithm can guarantee that the robot reaches the target when the robot is placed near it, and its fitness function is more than zero. The reason behind this strategy is that the local search is better able to guide the robot towards the target when the robot is near it, while the basic PSO may guide the robot to escape from the target. This means that when the robot becomes closer to the target, it will be able to track the target faster by applying local searches. In this study, A-star algorithm [23] is applied as a local search algorithm.
If heuristic function never overestimates the actual solution cost, then A-star always finds an optimal solution if one exists, which is the main advantage of A-star in comparison with other heuristic algorithms. Another advantage of A-star is that it considers fewer nodes than any other admissible search algorithm with the same heuristic. These properties make this algorithm the most well-known heuristic search algorithm that is widely used in path finding methods to determine the local search [25].
In this study, when the fitness function of each robot is larger than zero, its next position is calculated based on the local search strategy (A-star) instead of the second strategy. In the A-star, the search is started from the current node, and it continues until reaching the determined look ahead. The look ahead is defined as the number of next positions that the robot has to move to. In this study, the look ahead value is equal to 1. As described before, there are eight adjacent cells around the current position of the robot that it can move to in a specific direction. When the camera of the robot rotates, it can evaluate the fitness function for each of eight directions. Then the A-star algorithm, by selecting the highest f-value that belongs to the specific direction, moves towards the adjacent cell along this specific direction. The f-value for these directions is calculated by the following equation:

According to Eq. (4), the h (n) is the cost-to-go, which is assumed to be the fitness function value of the robot's current position in the specific direction. Meanwhile, g (n) is the cost-thus-far, which is the cost from the current node to the next position, and as the look ahead is equal to one, the g (n) in this study is equal to one. A-star uses two lists: Open and Close. The Open list is the list that stores all the acceptable directions of the robot which has a specific fitness function value, and then sorts them. The sorting of the Open list is based on the Max-Heap in this study, and as each direction is added to the Open list, the list is reordered based on the highest f-value. This means that the top of the list corresponds to the highest f-value. The selected direction with the highest f-value pops up from the Open list and is put into the Close list. The algorithm selects the direction from the Close list and then calculates the next position of the robot based on the selected direction, a position located among the adjacent cells around its current position. Finally, the robot moves to the next position.
When the fitness function of each robot returns to zero, it means the robot did not see the target in this iteration, and as time increases based on the basic PSO property its global searching decreases, and the local searching increases. Therefore, the probability of becoming entrapped in a small area (local optima) increases and robots may converge to the small area, meaning they cannot search the other areas to find the target.
The ML-PSO is inspired by the modification of PSO introduced by [20]. The measurement of fitness function in this method is different. The authors assume that each robot can sense its surroundings and calculate how much space around it is unrevealed. This means that when the robot is placed in one cell, by accessing the map of the search space it can mark its position as a visited area and then calculate how much of the space around its current position it has not yet visited. In order to increase the global searching, the cognitive component (

In ML-PSO, the four presented components that affect the movement of the robots are similar to those in [20]: momentum, cognitive and social, and the fourth component which is the force between robots and unexplored space. The fourth component in the velocity equation represents the vector
In [20], though, the global searching of basic PSO is increased, and this method overcomes the premature convergence problem; however, it has some drawbacks when applied to the searching domain. One of the drawbacks of this method is that when the target is placed near the robots and the robot cannot visit it in the first iteration, it is attracted through the fourth component (
In this proposed method (ML-PSO), the cognitive component (
In order to increase the global searching features of ML-PSO, when the robot is stuck in a small area (local optima), as well as providing a chance for the robots to search their surroundings when they arrive at a new area, the vector size of the fourth component is considered variable by assigning a variable value to
Whether or not the robots are trapped in the local optima is determined by their observation of their surroundings and the calculation of how much of their surrounding area is explored. Equation (6) defines this phenomenon:

In this study, the value of
In order to assign an appropriate value to
In order to guide the robots to escape from that area, they have to search the other unexplored areas. By increasing the value of
The value of

Simulation conditions
The ML-PSO and basic PSO are simulated and tested in three different environments with four different target positions in 100 test cases. The three environments with increasing numbers of obstacles are simulated and presented as (Env. 1, Env. 2, Env. 3) in order to show the function and the performance of this proposed algorithm (ML-PSO) when exposed to different numbers of obstacles and the premature convergence problem. As discussed before, one of the main problems of basic PSO is the premature convergence which appears in this domain when there are obstacles in the environment. Therefore, the presence of obstacles in this environment is essential and contributes towards obtaining an acceptable result. The four target positions are placed near or behind the obstacles to simulate the worst cases. In addition, the initial positions of the robots are located in the worst places but in a random manner; this means the initial positions of the robots are placed randomly at the farthest positions from the target, and they cannot see the target in the first iteration. The four points of the target in Env. 3 with maximum number of obstacles are shown in Figure 4. Only one target position is activated during each search run.

The map of simulation search space (Env. 3) and the four different target point locations
Unlike most of the PSO simulations, the search space in this simulation is bounded. Due to the condition approximation of the robot's actual searching, the search space in this simulation has a hard border. It is assumed that if the next position of each robot were placed out of the search space, it would reverse in order be placed inside the search space.
For the simulation results, the following parameter values are used:inertia coefficient,
Here, the basic PSO algorithm is adapted to the multi-robot search system; therefore, unlike most of the PSO research studies that track function value, this simulation searches the target function. The simulation stops when the robot reaches the target or the maximum number of iterations (400 iterations) has elapsed.
To evaluate the effectiveness of ML-PSO, there are two scenarios:
In order to show and compare the performance of ML-PSO and basic PSO when exposed to the premature convergence (local optima) problem, the amount of space explored by the robots in three different environments with an increasing number of obstacles is evaluated. These three environments contain six, 10 and 14 obstacles, respectively. The search time is selected as a measurement to compare the performance of ML-PSO and basic PSO algorithms when exposed to the two mentioned problems. In this scenario the search time consumed by ML-PSO and basic PSO algorithms in three environments with an increasing number of obstacles is evaluated as 100 runs.
The number of iterations in this article is considered to be 400 based on trial and error, because in most cases if the robots cannot reach the target before 400 iterations it means they are stuck in the local optima and never reach the target in this proposed domain. Since the main objective here is to decrease the search time, 400 iterations could be considered a proper number.
Simulation result in Environment 1
The areas explored by three robots in four different target positions in the environment (Env. 1) which include six obstacles are shown in Figure 5(a-h). Here, it is assumed that the minimum number of obstacles is six, which prevents the robot seeing behind the obstacles.

The results of simulated ML-PSO and basic PSO algorithms in Environment 1 with six static obstacles in 100 runs. The explored space is represented by black dots and the target is shown by the green square, (a) The simulation result of the basic PSO algorithm with target point 1. (b) The simulation result of ML-PSO with target point 1. (c) The simulation result of basic PSO algorithm with target point 2. (d) The simulation result of ML-PSO with target point 2. (e) The simulation result of basic PSO algorithm with target point 3. (f) The simulation result of ML-PSO with target point 3. (g) The simulation result of basic PSO algorithm with target point 4. (h) The simulation result of ML-PSO with target point 4.
The number of areas explored by applying ML-PSO and basic PSO on a multi-robot search system in this environment with six obstacles is evaluated.
Here, Figure 5(a) and 5(b) show the areas explored by basic PSO and ML-PSO algorithms, respectively, at the target point 1. In this case, the basic PSO could not find the target and the robots are stuck in the local optima; therefore, the area explored by basic PSO is smaller. The ML-PSO in this case can find the target and reach it. In order for ML-PSO to reach the target it explores more areas, which is not true for basic PSO.
As seen in Figure 5(c) and 5(d), the robots subject to basic PSO and ML-PSO can find the desired target and reach it. In this situation, though the initial positions of the robots are located in the worst positions in relation to the target, the small number of obstacles in the way of the robots allow the observation of the target in the first iterations. Although the behaviour of ML-PSO in this situation is similar to that of the basic PSO, more unexplored areas are explored through this proposed method during 100 runs.
When the target is placed behind the obstacle and the initial position of the robots is placed as far as possible from the target (4(e)), the robots could not find the target and reach it during 100 test cases through a basic PSO algorithm. The reason here is that the initial positions of the robots are located in the worst positions and are entrapped in the local optima. In this case, in early iterations, when the global searching of the robots is high, none of the robots see the target due to the presence of the obstacles and the limitations of observation by the robot camera. Here, the robots can see only 10 cells around themselves, so in the first iterations they could not observe the target. As the number of iterations increases, the global searching of the robots reduces, and they converge to small areas; hence, they become entrapped in the local optima and never reach the target.
As seen in Figure 5(f), although the target is placed behind the obstacles, ML-PSO helps the robots to escape from the local optima and search more unexplored areas during 100 runs by applying the second strategy. Then, by adopting the local search method (first strategy), the robots move towards the target more quickly.
The target point 4 is located near the corner. This case is very difficult for basic PSO when the initial position of the robots is placed in the farthest position, where the robots could be entrapped in the local optima and converge to that area, while in the case of ML-PSO, when each of the robots finds that it is stuck in the local optima it tries to leave that area and move towards the unexplored areas by applying the second strategy.
Another strategy to evaluate the performance of both of the algorithms in this environment is to compare the number of iterations passed by each algorithm in finding the target. The search times consumed by ML-PSO and basic PSO algorithms in this environment with the four different target positions are compared in Figure 6.
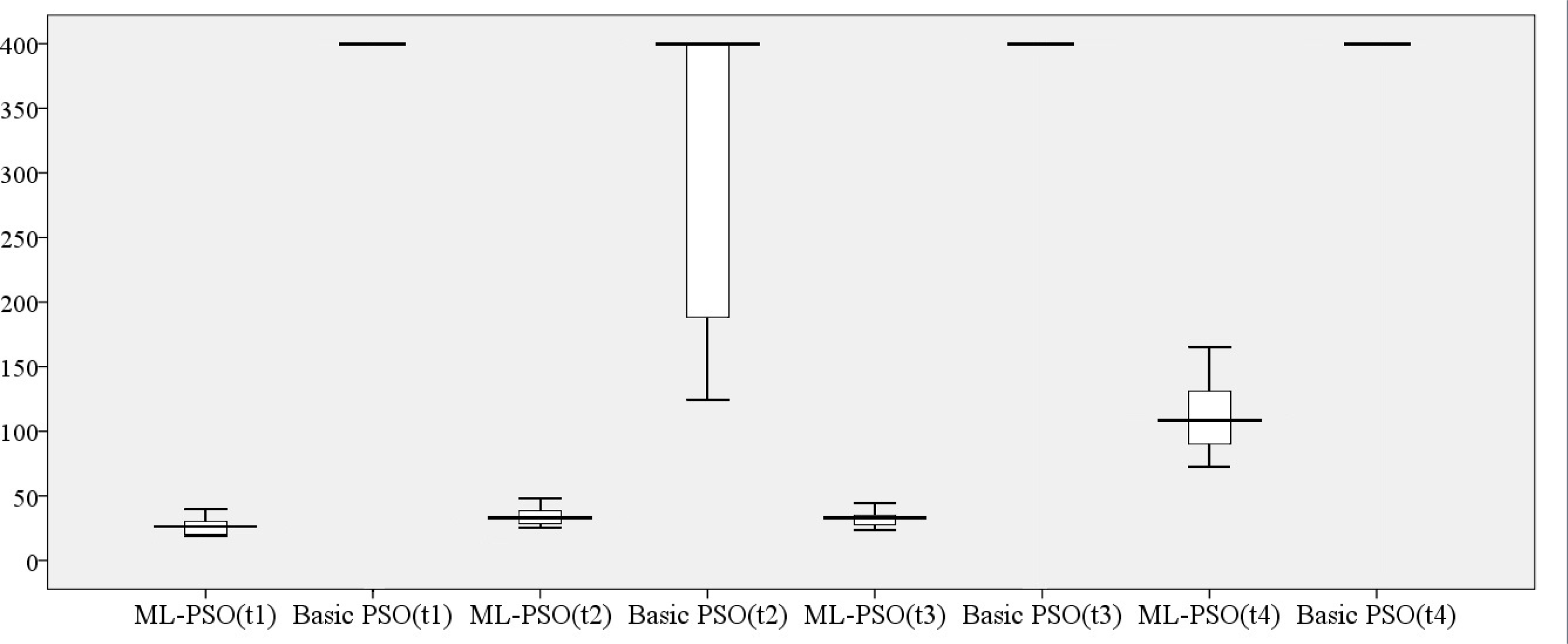
The result of the search time of the ML-PSO and basic PSO algorithm with four different target positions in Environment 1 containing six static obstacles in 100 runs
The basic PSO algorithm could find the target in one of the target points (target point 2) but it could not find the target in target points 1, 3 and 4 during 400 iterations in 100 runs (Figure 6). The ML-PSO algorithm can find the target in four different target points in a reasonable search time.
As seen in target point 1, the basic PSO algorithm could not find the target in a given time during 100 runs. This is because the robots are stuck in the local optima and cannot escape. The number of iterations for the ML-PSO algorithm in this case ranges between 20 and 50 iterations.
The number of iterations in ML-PSO and basic PSO slightly increase in target point 2. The figure shows that the basic PSO algorithm can find and reach the target in between 130 and 400 iterations while the ML-PSO can find and reach the target in between 30 and 50 iterations.
In the remaining number of target points (target points 3 and 4), basic PSO could not find the target due to the premature convergence problem. That is, the robots converge to the small area and never search other areas.
As observed, in these two difficult target positions the ML-PSO can find the target. The function of this algorithm is to guide the robots to escape from the local optima and move towards the unexplored areas through determining whether or not they are stuck in the local optima. Here, when each robot observes the target, it moves towards it using the first strategy. The number of iterations of ML-PSO in target point 3 varies between 25 and 50 iterations. The search time in target point 4 in ML-PSO increases and reaches around 70–140 iterations.
The areas explored by the robots in four different target positions in the environment (Env. 2) with 10 obstacles in 100 test cases are shown in Figure 7(a-h). This environment is more complex than the previous environment, and we therefore expect the weakness of basic PSO to be more evident than before.

The results of simulated ML-PSO and basic PSO algorithms in Environment 2 with 10 static obstacles in 100 runs. Explored space is represented by the black dots and the target is shown by the green square. (a) The simulation result of basic PSO algorithm with target point 1. (b) The simulation result of ML-PSO with target point 1. (c) The simulation result of basic PSO algorithm with target point 2. (d) The simulation result of ML-PSO with target point 2. (e) The simulation result of basic PSO algorithm with target point 3. (f) The simulation result of ML-PSO with target point 3. (g) The simulation result of basic PSO algorithm with target point 4. (h) The simulation result of ML-PSO with target point 4.
The performance of the basic PSO and ML-PSO in exploring the environment with 10 obstacles with four different target positions in 100 runs is shown in Figure 7(a–h). This environment (Env. 2) is more complex than Env. 1. When the number of obstacles increases, the probability of observing the target by the robots decreases.
As seen in Figures 7(a–h), the basic PSO algorithm can only find the target and reach it at the target point 2 (6(c)) because the position of obstacles in this environment is similar to the previous environment (Env. 1) with the same target point. In this case, the added obstacles are not placed in the way of the robots, and thus they can find and reach the target.
In the remaining target points (6(a), 6(e), 6(g)), the basic PSO algorithm fails to find and reach the target. The multi-robot search system using the basic PSO algorithm is stuck in the local optima and converges to that area; therefore, they cannot search other unexplored areas. This is because of the number of static obstacles and the initial positions of the robots which are closer to the target.
On the other hand, ML-PSO algorithm in four different target points can find the target and reach it. Figure 7(b) represents the amount of explored areas with ML-PSO algorithms. The number of explored areas with ML-PSO is more than the number forprevious environments with the same target position. This is because of the obstacles being added to the environment in a way that diverts the robots to search the obstacles' surroundings more extensively.
As shown in Figure 7(c) and 7(d), although the basic PSO could also find the target in this case and reach it, the amount of areas explored by the ML-PSO is more than with basic PSO. In this case, the robots' movement through the basic PSO towards the target is the same as through ML-PSO, but they search the same areas during the search time because the global search decreases over time.
Figures 7(e) and 7(f) represent the amount of explored areas using the basic PSO and the ML-PSO when the target is placed in a difficult position (behind the obstacle). In this case, the robots must move to the nearby area to see the target. Global searching in the basic PSO decreases over time, and thus the robots are stuck in the local optima and cannot explore other areas. In the ML-PSO algorithm, global searching (exploration) is increased by applying the second strategy. This strategy pulls the robots to move towards the unexplored areas; hence, they observe the target by searching different areas. The amount of exploration by the ML-PSO is about twice that of the basic PSO.
The difficult case in this environment is target point 4. In this case the target position is near the corner of the search space and the initial position of the robots is very far from the target; therefore, the robots converge to local optima and search that area continuously, and the amount of areas explored though the basic PSO is low, while the robots can find and reach the target through the ML-PSO algorithm. In contrast, the amount of explored areas when applying ML-PSO algorithm on a multi-robot search system is high due to the initial position of the robots, which is far away from the target, and this algorithm has to maintain the global search at a high level to search many areas and find the target.
Another strategy to evaluate the search time of ML-PSO and basic PSO in this environment is illustrated in Figure 8. Figure 8 represents the search time (number of iterations) the ML-PSO and the basic PSO needed to find the target.

The result of the search time of ML-PSO and basic PSO algorithm with four different target positions in Environment 2 containing 10 static obstacles in 100 runs
As can be seen in Figure 8, in all target points except one the basic PSO algorithm fails to find the target and cannot reach it. The basic PSO in target point 2 can find the target and reach it, and this case is similar to Environment 1 (Env. 1) with the same target point.
The number of iterations for ML-PSO in this environment increases due to the added static obstacles. The number of iterations in the target point 1 for ML-PSO is about 30–60 iterations, while these figures increased in target point 2 and reached about 40–70 iterations. When the target is placed behind the obstacles (target point 3) it is difficult for the robots to find it; therefore, the search time increases and ranges from 50 to around 100 iterations.
In target point 4, the target is placed in one of the hardest positions and the multi-robot is located at the farthest position from the target. This position shows the weakness of the basic PSO in finding objects among 10 obstacles. In this case, a multi-robot search system applying basic PSO could not find the target, but ML-PSO can find the target during 130–170 iterations despite the fact that this case is very difficult.
This environment is the most complex environment in this study, and contains 14 obstacles. The amount of explored areaswith both basic PSO and ML-PSO is shown in Figure 9(a-h).

The results of simulated ML-PSO and basic PSO algorithms in Environment 3 with 14 static obstacles in 100 runs. Explored space is represented by the black dots and the target is shown by the green square. (a) The simulation result of basic PSO algorithm with target point 1. (b) The simulation result of ML-PSO with target point 1. (c) The simulation result of basic PSO algorithm with target point 2. (d) The simulation result of ML-PSO with target point 2. (e) The simulation result of basic PSO algorithm with target point 3. (f) The simulation result of ML-PSO with target point 3. (g) The simulation result of basic PSO algorithm with target point 4. (h) The simulation result of ML-PSO with target point 4.
Figure 9(a-h) shows the amount of explored areas through the ML-PSO and the basic PSO algorithms in the environment (Env. 3), which are the most complex environments in this study and contain 14 static obstacles with four different target positions in 100 test cases.
As shown in Figures 9(a),9(c), 9(e) and 9(g), the basic PSO algorithm failed to find the target in four different target points and could not reach the desired target during 100 runs. In these target positions, the multi-robot search system is stuck in local optima and searches the same areas during the desired search time. As a result, the amount of explored areas is low.
On the other hand, although the environment is complex, ML-PSO can successfully find the target in all target positions and reach it in a given search time. Figures 9(b) and 9(d) show the amounts of explored areasusing ML-PSO algorithms. These amounts are higher than in other environments (Env. 1, Env. 2) with the same target points.
When the target is in the hardest place, such as target points 3 and 4 (behind the obstacle and near the corner), the ML-PSO algorithm guides the robots to search unexplored areas further by increasing global searching; therefore, they move towards the target and then move faster by using the local search strategy.
The search time of the ML-PSO and the basic PSO in this environment with four target positions is shown in Figure 10.

The results of the search time of ML-PSO and basic PSO algorithm with four different target positions in Environment 3 containing 14 static obstacles in 100 test cases
Figure 10 represents the search time consumed through the ML-PSO and the basic PSO algorithms in the most complex environments in this study. As can be seen in Figure 10, through ML-PSO the robots can find the target in four different target points, which is not true for the basic PSO algorithm. The number of iterations in four target points increases in the ML-PSO algorithm in comparison with previous environments (Env. 1, Env. 2).
In target point 1, the ML-PSO spends around 35–100 iterations while the basic PSO fails to find the target, and the multi-robot system is stuck in the local optima. As in previous environments with the same situation can be seen, the basic PSO algorithm failed to find the target and became entrapped in the local optima. When the global searching of the algorithm is at a high level, the static obstacles in the way of the robots prevent them from observing the target in the first iterations; hence, they become entrapped in the local optima, and as time increases they search the same areas and cannot find the target.
In target point 2, the number of iterations required for ML-PSO to find the target is between 60 and around 130. Although in the previous environments with the same target point the basic PSO could find the target and reach it, in this environment the additional static obstacles in the way of the robots lead to the robots being stuck in the local optima and never finding the target, while the ML-PSO can find the target and reach it in between 70 and 100 iterations.
The number of iterations in the basic PSO when the target is placed in target point 3 is 400. This means the robots could not find the target through the basic PSO algorithm in this case. In this case, ML-PSO algorithm can find the target and reach it, and the number of iterations passed by this algorithm varies from 70 to 100.
Target point 4 is the most difficult among all cases in all three environments. In this case, the target is placed near the corner and in the most distant possible position in the search space. The basic PSO quickly became entrapped in local optima and could not search the other areas to find the target, while the ML-PSO could find the target and reach it in 130–250 iterations.
A biologically inspired search strategy is developed and tested for robot swarms. This search technique, named ML-PSO, is based on bird flocking and basic PSO. The ML-PSO algorithm is able to solve two problems of basic PSO, taking into account static obstacles in the search space (Figure 3 represents the pseudo code of the ML-PSO algorithm). The first problem of basic PSO is premature convergence, which appeared in this domain when there are static obstacles in the search space and the initial positions of the robots are far from the target. In basic PSO, as time progresses, the global searching (exploration) of the robots decreases and the robots converge to a small area; thus, the system fails to search the other areas and find the target. In order to solve this problem, ML-PSO increases the global searching of the basic PSO by adding the fourth component to the velocity equation (second strategy), which is inspired by [20] and modified based on this domain. The value of the fourth component varies in different cases when each of the robots detects whether it is stuck in the local optima or not. This variable helps the robot to escape from the local optima and move towards and search the unexplored areas.
Another problem is that basic PSO cannot guarantee that the global optima (the target) will be reached and cannot establish a balance between exploration and exploitation. This means that in some cases when the robots see the target and the fitness function value is high enough, the basic PSO algorithm guides the robot to move to the positions that may increase the distance between the robot and the target. In order to decrease the search time and guarantee that the robots can reach the target when they observe it, the local search method is added to the ML-PSO algorithm. When the robot sees the target, instead of using modified basic PSO equations (second strategy), it moves towards the target by applying a local search method such as A-star (first strategy).
The ML-PSO and basic PSO algorithms are simulated and tested on the multi-robot search system in the three environments, with increasing numbers of static obstacles with four different target positions. The results show that the ML-PSO algorithm has better performance in comparison with the basic PSO, as observed, and the amount of areas explored through ML-PSO is higher than through basic PSO in the same situation. In addition, the search time in ML-PSO is less than in basic PSO in all three environments with four target positions.
This proposed method could be applied in real-world environments with the same situations. This method can be used to solve problems in finding an object in environments with many static obstacles, e.g., factories, hazardous environments, detecting water and oxygen in moon exploration projects, etc.
It is worth mentioning that during the simulations in this study one of the possible drawbacks could be the handling of the localization task with respect to modification in the search environment. For instance, adding moving objects into the search space while their movement information is unknown to the robots could lead to the failure of the robots in their localization task. Therefore, more in-depth studies are necessary to overcome this drawback.